
Program
Yardımcı Veri Bilimcisi Python'da
90 sa
Doğrusal regresyon, değişkenler arasındaki ilişkiyi modellemeye yardımcı olan istatistik ve makine öğrenimindeki temel bir tekniktir. Basitçe söylemek gerekirse, bir veya daha fazla etkileyen faktöre dayanarak bir sonucu tahmin etmemizi sağlar. Emlak fiyatlandırması, satış tahmini, risk değerlendirmesi ve daha birçok alanda yaygın olarak uygulanır.
Bu eğitimde, scikit-learn içinde doğrusal regresyonu inceleyecek, nasıl çalıştığını, neden faydalı olduğunu ve scikit-learn kullanarak nasıl uygulanacağını ele alacağız. Sonunda, veriye dayalı tahminler yapmak için bir doğrusal regresyon modeli kurup değerlendirebileceksiniz.
Oda Sayısına Karşı Konut Fiyatı Saçılım Grafiği
Konut fiyatlarını belirlemedeki doğrudan faydasının ötesinde, doğrusal regresyon makine öğreniminde önemli bir rol oynar.
Basitliğine rağmen doğrusal regresyon, verimliliği, yorumlanabilirliği ve çok yönlülüğü sayesinde makine öğreniminde vazgeçilmez bir araç olmaya devam eder.
Scikit-learn kütüphanesi, doğrusal regresyonu uygulamayı kolaylaştırır. Bu kütüphanenin birçok avantajı vardır.
model.fit(X_train, y_train) satırını kullanırsınız.Scikit-learn'e yeniyseniz, Python kütüphanesine uygulamalı bir giriş için scikit-learn ile Makine Öğrenimi kursumuza göz atabilirsiniz.
Görüldüğü gibi, basit doğrusal regresyonda veriler "en iyi uyumlu bir çizgi" ile modellenir. Bu çizginin formülü şudur:
![]()
burada m doğrunun eğimi, b ise y-kesişimidir.
"Çoklu doğrusal regresyon", tek bir yordayıcı durumunu birden fazla yordayıcıya (oda sayısı, okyanusa yakınlık, mahallenin medyan geliri) geneller. Formül şu şekilde genellenir:
![]()
burada her bir xi bağımsız bir değişkeni, karşılık gelen bi ise onun katsayısını temsil eder. Üç boyutta, doğru bir düzleme genellenir. Daha yüksek boyutlarda düzlem bir "hiperdüzlem" olur.
Katsayıları ve kesişimi nasıl yorumlarız? Kesişim, tüm bağımsız değişkenler 0 iken y'nin tahmin edilen değeridir; başka bir deyişle, yordayıcılardan katkı olmadığında bağımlı değişkenin temel değeridir. Her bir bi katsayısı, diğer tüm bağımsız değişkenler sabitken, xi'deki bir birimlik değişim için bağımlı değişken y'deki değişimi ifade eder.
Scikit-learn'ü kurmak kolaydır. pip install scikit-learn komutunu kullanmanız yeterlidir. Belirli bir sürüm (ör. 1.2.2) kurmak isterseniz, komuta sürümü ekleyin: pip install scikit-learn==1.2.2. Anaconda kullanıyorsanız scikit-learn zaten yüklü olmalıdır. Herhangi bir nedenle Anaconda dağıtımını kullanırken yine de kurmanız gerekirse, şu komutu kullanın: conda install scikit-learn.
Scikit-learn kullanırken birkaç kütüphane gerekli ya da önerilir. numpy kütüphanesi özellikleri ve etiketleri depolamak için gereklidir. pandas kütüphanesi veri kümelerini yükleme, ön işleme ve keşfetme için önerilir.
Scikit-learn kullanıyorsanız, muhtemelen veri hazırlığınız için zaten pandas kullanıyorsunuzdur. Sonuçları çizdirmek için büyük olasılıkla matplotlib veya seaborn ya da her ikisini kullanacaksınız. Bu kütüphanelerin herhangi biri, yukarıdaki örneğe benzer şekilde pip ile kurulabilir. Hatta tek bir komutla birden fazla kütüphaneyi kurabilirsiniz:
pip install scikit-learn numpy pandas matplotlib seaborn.
Veri kümesini yüklemeden önce, alışık olduğumuz kütüphaneleri içe aktaralım.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsBilinen California konut veri setini kullanalım.
# Read in California housing dataset.
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()Verileri eğitim ve test kümelerine bölelim. sklearn.model_selection içinden train_test_split() metodunu içe aktarıp, test seti yüzdesini ve bir random_state belirterek çağıracağız. Ayrıca ortalama oda sayısına karşılık gelen özelliği kullanarak basit doğrusal regresyon uygulayacağız.
# Import train_test_split.
from sklearn.model_selection import train_test_split
# Create features X and target y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)[["AveRooms"]]
y = housing.target # Median house value in $100,000s
# Split the dataset into training (80%) and testing (20%) sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Artık verileri test ve eğitim setlerine ayırdığımıza göre, özellikleri standartlaştıralım. Bu işlem, tüm değişkenlerin aynı ölçekte olmasını sağlar; bu da model performansını ve sayısal kararlılığı iyileştirebilir.
# Import StandardScaler.
from sklearn.preprocessing import StandardScaler
# Instantiate StandardScaler.
scaler = StandardScaler()
# Fit and transform training data.
X_train_scaled = scaler.fit_transform(X_train)
# Also transform test data.
X_test_scaled = scaler.transform(X_test)Bu kodda StandardScaler, ortalamayı kaldırıp özellikleri birim varyansa ölçeklemek için kullanılan bir veri ön işleme aracıdır. Bu, ölçekteki farklılıklar nedeniyle belirli özelliklerin modeli baskılamasını engellemeye yardımcı olur.
Ölçekleyici, fit_transform() yöntemiyle eğitim verisine uyarlanır ve dönüştürülür. Test verisi daha sonra transform() yöntemi kullanılarak ayrı şekilde dönüştürülür; böylece eğitim verisiyle aynı faktörler kullanılarak ölçeklenir ve veri sızıntısı önlenir.
Bir doğrusal regresyon modeli oluşturmak için sklearn.linear_model içinden LinearRegression()'ı içe aktarın. Çağırın ve bir değişkene atayın.
# Import LinearRegression.
from sklearn.linear_model import LinearRegression
# Instantiate linear regression model.
model = LinearRegression()Modeli eğitim verisiyle eğitmek basittir.
# Fit the model to the training data.
model.fit(X_train_scaled, y_train)Artık modelimizi eğittiğimize göre, test seti üzerinde tahmin yapalım.
# Make predictions on the testing data.
y_pred = model.predict(X_test_scaled)Test setinde tahminler yaptığımıza göre, bunların gerçeklikle ne kadar örtüştüğünü bilmemiz gerekiyor. Bir regresyon algoritmasının performansını değerlendirmek için çeşitli metrikler mevcuttur. En yaygın olanlardan bazıları belirleme katsayısı (R2), ortalama kare hata (MSE) ve karekök ortalama kare hata (RMSE)dir.
R2 olarak gösterilen belirleme katsayısı, bir regresyon modelinin hedef değişkenin değişkenliğini ne kadar iyi açıkladığını ölçer. Başka bir deyişle, hedef değişkendeki değişkenliğin ne kadarının yordayıcılar tarafından açıklandığını, yani uyumun iyiliğini nicelleştirir.
Bunu daha iyi anlamak için formüle bakalım:
![]()
burada yactual hedef değişkenin gerçek değerleri, ypredicted modelin tahmin ettiği değerler ve ȳ gerçek değerlerin ortalamasıdır. Bu formül, hedef değişkendeki varyansın ne kadarının model tarafından açıklandığını anlamamıza yardımcı olur. Payda, verideki toplam varyansı; pay ise regresyon modeli uygulandıktan sonra açıklanamayan varyansı temsil eder. Dolayısıyla oran, model tarafından açıklanan varyans yüzdesini verir.
R2'yi nasıl yorumlarız?
Aklınızda bulundurmanız gereken bazı önemli noktalar.
Scikit-learn ile belirleme katsayısını kullanarak model performansını değerlendirmek kolaydır.
# Import metrics.
from sklearn.metrics import mean_squared_error, r2_score
# Calculate and print R^2 score.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")R-squared: 0.0138Diğer yaygın metrikler, ortalama kare hata (MSE) ve karekök ortalama kare hata (RMSE)dir. Bu metrikler, bir modelin tahminlerinin gerçek değerlerden ne kadar saptığını ölçer.
MSE, gerçek ve tahmin edilen değerler arasındaki ortalama karesel farkı hesaplar:
toplam gözlem sayısı n için. Hatalar ortalama alınmadan önce kare alındığından, büyük hatalar küçük olanlardan daha fazla cezalandırılır; bu da MSE'yi aykırı değerlere duyarlı kılar. Daha düşük MSE, daha iyi bir model uyumunu gösterir.
Bu sorunu ele almak için MSE'nin karekökü olan RMSE kullanılır. RMSE hedef değişkenle aynı birimlerde olduğundan, ortalama olarak tahminlerin ne kadar saptığını daha yorumlanabilir bir ölçü sunar.
MSE ve RMSE hesaplamak scikit-learn ile kolaydır.
# Calculate and print MSE.
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
# Calculate and print RMSE.
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")Mean squared error: 1.2923
Root mean squared error: 1.1368Modeli yalnızca ortalama oda sayısını değil, mevcut tüm özellikleri kullanarak yeniden çalıştıralım. Daha iyi mi yoksa daha kötü sonuçlar mı bekliyorsunuz?
# Uses all features.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load data set.
housing = fetch_california_housing()
# Split into X, y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)
y = housing.target # Median house value in $100,000s
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data.
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create model and fit it to the training data.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions.
y_pred = model.predict(X_test_scaled)
# Calculate and print errors.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5758
Mean squared error: 0.5559
Root mean squared error: 0.7456Sonuçların yalnızca tek bir özellik kullanmaya kıyasla oldukça daha iyi olduğunu görüyoruz. Ancak bu, tüm özelliklere ihtiyaç duyup duymadığımız sorusunu gündeme getiriyor. Bazı özellikler diğerlerinden daha mı ilgili? Veri kümesinden en ilgili özellikleri seçmeye özellik seçimi denir.
Özellik seçimi çeşitli nedenlerle önemlidir.
Birden fazla özellik yüksek derecede ilişkili olduğunda, özdeştir; yani modele özünde aynı bilgiyi verirler. Bu duruma çoklu bağlantı (multicollinearity) denir. Çoklu bağlantı, her zaman kestirim modellerinin doğruluğunu etkilemese de, özellikle doğrusal regresyon ve ilişkili modellerde özellik seçimini ve yorumlamayı zorlaştırır.
Varyans Şişirme Faktörü (VIF), yordayıcılar arasındaki çoklu bağlantıyı tespit etmek için kullanılan bir metriktir. Her bir yordayıcı için VIF şu şekilde hesaplanır:
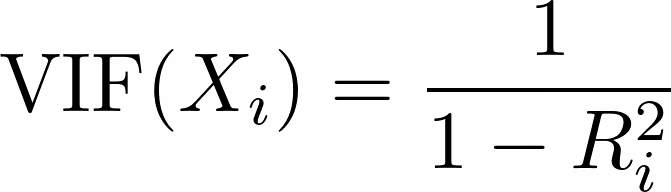
burada Ri2, Xi yordayıcısı modeldeki diğer tüm yordayıcılara karşı regresyona tabi tutulduğunda elde edilen R2 değeridir. Daha yüksek VIF, yordayıcının diğer değişkenlerle yüksek korelasyona sahip olduğu anlamına gelir.
# Import libraries.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from statsmodels.stats.outliers_influence import variance_inflation_factor
# Load the dataset.
housing = fetch_california_housing()
X = pd.DataFrame(housing.data, columns=housing.feature_names)
# Compute the correlation matrix.
corr_matrix = X.corr()
# Identify pairs of features with high collinearity (correlation > 0.8 or < -0.8).
high_corr_features = [(col1, col2, corr_matrix.loc[col1, col2])
for col1 in corr_matrix.columns
for col2 in corr_matrix.columns
if col1 != col2 and abs(corr_matrix.loc[col1, col2]) > 0.8]
# Convert to a DataFrame for better visualization.
collinearity_df = pd.DataFrame(high_corr_features, columns=["Feature 1", "Feature 2", "Correlation"])
print("\nHighly Correlated Features:\n", collinearity_df)
# Compute Variance Inflation Factor (VIF) for each feature.
vif_data = pd.DataFrame()
vif_data["Feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
# Print VIF values.
print("\nVariance Inflation Factor (VIF) for each feature:\n", vif_data) Highly Correlated Features:
Feature 1 Feature 2 Correlation
0 AveRooms AveBedrms 0.847621
1 AveBedrms AveRooms 0.847621
2 Latitude Longitude -0.924664
3 Longitude Latitude -0.924664
Variance Inflation Factor (VIF) for each feature:
Feature VIF
0 MedInc 11.511140
1 HouseAge 7.195917
2 AveRooms 45.993601
3 AveBedrms 43.590314
4 Population 2.935745
5 AveOccup 1.095243
6 Latitude 559.874071
7 Longitude 633.711654Modelden AveBedrms'i kaldıralım.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load California housing dataset.
housing = fetch_california_housing()
# Create DataFrame and remove "AveBedrms" feature.
X = pd.DataFrame(housing.data, columns=housing.feature_names).drop(columns=["AveBedrms"])
y = housing.target # Median house value in $100,000s
# Split data into training and testing sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data (Standardization).
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create a linear regression model and train it.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions on the test set.
y_pred = model.predict(X_test_scaled)
# Calculate performance metrics.
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
# Print evaluation metrics
print(f"R-squared: {r2:.4f}")
print(f"Mean squared error: {mse:.4f}")
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5823
Mean squared error: 0.5473
Root mean squared error: 0.7398Sonuçlar (az da olsa) iyileşti.
Bir regresyon modeli kurmak yalnızca ilk adımdır; çıktılarını anlamak da aynı derecede önemlidir. Modelin katsayılarını analiz ederek, hangi özelliklerin tahminler üzerinde en büyük etkiye sahip olduğunu belirleyebiliriz.
Bir doğrusal regresyon modeli eğitildiğinde, katsayılara model.coef_ ile erişilebilir. Kesişime ise model.intercept_ ile erişilebilir.
LinearRegression() kullanılarak bir doğrusal regresyon modeli eğitildiğinde, katsayılara model.coef_ ve kesişime model.intercept_ ile erişilebilir.
print("Intercept:", model.intercept_)
coeff_df = pd.DataFrame({"Feature": X.columns, "Coefficient": model.coef_})
print("\nFeature Coefficients:\n", coeff_df) Intercept: 2.0719469373788777
Feature Coefficients:
Feature Coefficient
0 MedInc 0.725747
1 HouseAge 0.121519
2 Latitude -0.943105
3 Longitude -0.900735Scikit-Learn, Statsmodels'taki gibi yerleşik bir summary() metodu sunmadığından, her bir özelliğin önemini regresyon katsayılarını kullanarak elle çıkarıp görselleştirebiliriz. Mutlak değeri daha büyük olan katsayılara sahip özellikler, hedef değişken üzerinde daha güçlü bir etkiye sahiptir. Aşağıdaki koda bakın.
# Sort dataframe by coefficients.
coef_df_sorted = coef_df.sort_values(by="Coefficient", ascending=False)
# Create plot.
plt.figure(figsize=(8,6))
plt.barh(coef_df["Feature"], coef_df_sorted["Coefficient"], color="blue")
plt.xlabel("Coefficient Value")
plt.ylabel("Feature")
plt.title("Feature Importance (Linear Regression Coefficients)")
plt.show()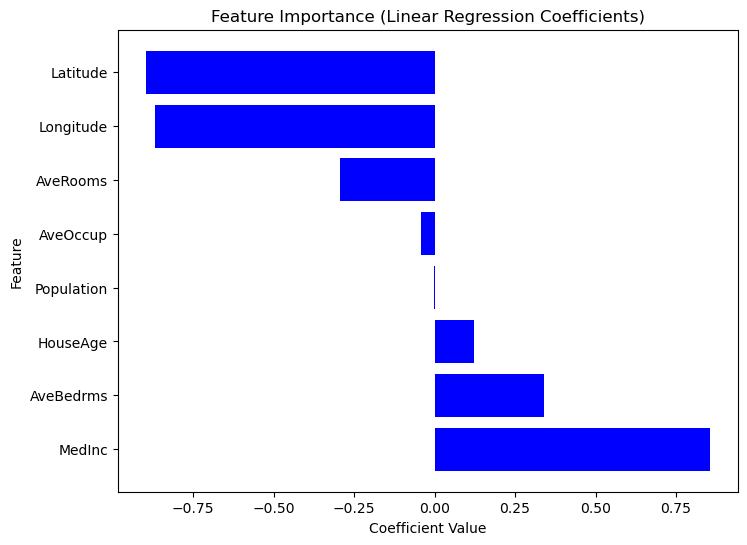
Katsayı Değerlerine Göre Özellik Öneminin Grafiği
Şimdi artık artık artıkları (residuals) ve regresyon uyumunu görselleştirelim.
# Compute residuals.
residuals = y_test - y_pred
# Create plots.
plt.figure(figsize=(12,5))
# Plot 1: Residuals Distribution.
plt.subplot(1,2,1)
sns.histplot(residuals, bins=30, kde=True, color="blue")
plt.axvline(x=0, color='red', linestyle='--')
plt.title("Residuals Distribution")
plt.xlabel("Residuals (y_actual - y_predicted)")
plt.ylabel("Frequency")
# Plot 2: Regression Fit (Actual vs Predicted).
plt.subplot(1,2,2)
sns.scatterplot(x=y_test, y=y_pred, alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--') # Perfect fit line
plt.title("Regression Fit: Actual vs Predicted")
plt.xlabel("Actual Prices (in $100,000s)")
plt.ylabel("Predicted Prices (in $100,000s)")
# Show plots.
plt.tight_layout()
plt.show()
Artıkları ve Regresyon Uyumunu Görselleştiren Grafikler
Artık dağılımı (soldaki grafik) sıfır etrafında merkezlenmiş olmalıdır; bu, hataların rastgele dağıldığını gösterir. Artıklar normal dağılımı takip ediyorsa model iyi uyum sağlar; ancak çarpıklık veya bir eğilim varsa sistematik hatalara işaret edebilir. Regresyon uyumu (sağdaki grafik) gerçek ve tahmin edilen değerleri karşılaştırır; kırmızı kesikli çizgi mükemmel uyumu temsil eder. Noktalar çizgiyi yakından takip ediyorsa tahminler doğrudur; ancak bir desen (ör. eğri) varsa ilişki gerçekten doğrusal olmayabilir.
Bu görselleştirmeler aşırı veya yetersiz uyumu teşhis etmeye, artık örüntülerinin eksik ilişkiler önerdiği durumları ortaya çıkarmaya ve modelin etkinliğine dair net bir değerlendirme sunmaya yardımcı olur.
Doğrusal regresyon, tahmin ve karar verme amacıyla sektörler arasında yaygın olarak kullanılır. Gayrimenkulde, büyüklük ve konum gibi faktörlere göre konut fiyatlarını tahmin eder.
Satış ve pazarlama, talep tahmini ve bütçe optimizasyonu için; sağlık sektörü ise hastalık risk değerlendirmesi için kullanır. Finansta hisse senedi fiyat tahmini ve kredi skorlama süreçlerinde yardımcı olur; üretimde ise kalite kontrol ve arıza tahminine katkı sağlar.
Doğrusal regresyon, makine öğrenimi ve istatistiksel modellemenin en temel ve en yaygın kullanılan tekniklerinden biri olmaya devam etmektedir. Basit olmasına rağmen, değişkenler arasındaki ilişkileri anlamak ve çeşitli gerçek dünya uygulamalarında tahminler yapmak için güçlü bir araçtır.
İşte bu eğitimden çıkarılacak temel noktalar:
Python dize enterpolasyonu hakkında daha fazla bilgi için DataCamp'in kaynaklarına göz atın.
Öne Çıkan DataCamp Kursları
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
