
Programma
Scienziato dei dati associato in Python
90 h
La regressione lineare è una tecnica fondamentale in statistica e machine learning che aiuta a modellare la relazione tra variabili. In termini semplici, permette di prevedere un risultato sulla base di uno o più fattori influenti. È ampiamente utilizzata nella valutazione immobiliare, nelle previsioni di vendita, nella valutazione del rischio e in molti altri ambiti.
In questo tutorial esploreremo la regressione lineare in scikit-learn, vedendo come funziona, perché è utile e come implementarla con scikit-learn. Alla fine sarai in grado di costruire e valutare un modello di regressione lineare per fare previsioni basate sui dati.
Grafico a dispersione del prezzo delle case rispetto al numero di stanze
Oltre alla sua utilità immediata per determinare i prezzi delle case, la regressione lineare svolge un ruolo importante nel machine learning.
Nonostante la sua semplicità, la regressione lineare resta uno strumento indispensabile nel machine learning grazie a efficienza, interpretabilità e versatilità.
La libreria scikit-learn rende facile implementare la regressione lineare. Questa libreria ha molti vantaggi.
model.fit(X_train, y_train).Se sei alle prime armi con scikit-learn, puoi dare un'occhiata al nostro corso Machine Learning con scikit-learn per un'introduzione pratica alla libreria Python.
Come abbiamo visto, nella regressione lineare semplice i dati sono modellati usando una "retta di miglior adattamento". La formula di questa retta è:
![]()
dove m è la pendenza della retta e b è l'intercetta.
La "regressione lineare multipla" generalizza il caso con un predittore a diversi predittori (numero di stanze, vicinanza all'oceano, reddito medio del quartiere). La formula si generalizza a:
![]()
dove ciascuna xi è una variabile indipendente e la corrispondente bi è il suo coefficiente. In tre dimensioni, la retta si generalizza a un piano. In dimensioni superiori, il piano diventa un "iperpiano".
Come si interpretano i coefficienti e l'intercetta? L'intercetta è il valore previsto di y quando tutte le variabili indipendenti sono 0, ovvero il valore di base della variabile dipendente quando non c'è contributo dai predittori. Ogni coefficiente bi rappresenta la variazione della variabile dipendente y per una variazione unitaria in xi, mantenendo costanti tutte le altre variabili indipendenti.
Installare scikit-learn è semplice. Usa il comando pip install scikit-learn. Se vuoi installare una versione specifica, per esempio la 1.2.2, modifica il comando includendo la versione: pip install scikit-learn==1.2.2. Se usi Anaconda, scikit-learn dovrebbe essere già installata. Se per qualche motivo devi comunque installarla con la distribuzione Anaconda, usa il comando conda install scikit-learn.
Diversi pacchetti sono necessari o consigliati quando si usa scikit-learn. La libreria numpy serve per memorizzare caratteristiche e etichette. La libreria pandas è consigliata per caricare, preprocessare ed esplorare i dataset.
Se usi scikit-learn, con ogni probabilità stai già usando pandas per la preparazione dei dati. Per tracciare i risultati, probabilmente userai matplotlib o seaborn o entrambi. Qualsiasi di queste librerie può essere installata con pip install, come nell'esempio sopra. Puoi anche installare più librerie con un unico comando:
pip install scikit-learn numpy pandas matplotlib seaborn.
Prima di caricare il dataset, importiamo i soliti sospetti.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsUsiamo il noto dataset California housing.
# Read in California housing dataset.
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()Dividiamo i dati in set di training e di test. Importiamo il metodo train_test_split() da sklearn.model_selection, poi lo invochiamo specificando la percentuale del test set e un random_state. Useremo anche la regressione lineare semplice, utilizzando la caratteristica corrispondente al numero medio di stanze.
# Import train_test_split.
from sklearn.model_selection import train_test_split
# Create features X and target y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)[["AveRooms"]]
y = housing.target # Median house value in $100,000s
# Split the dataset into training (80%) and testing (20%) sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Ora che abbiamo diviso i dati in set di test e training, standardizziamo le caratteristiche. Questo processo garantisce che tutte le variabili siano sulla stessa scala, il che può migliorare le prestazioni del modello e la stabilità numerica.
# Import StandardScaler.
from sklearn.preprocessing import StandardScaler
# Instantiate StandardScaler.
scaler = StandardScaler()
# Fit and transform training data.
X_train_scaled = scaler.fit_transform(X_train)
# Also transform test data.
X_test_scaled = scaler.transform(X_test)In questo codice, StandardScaler è uno strumento di preprocessing usato per rimuovere la media e scalare le caratteristiche alla varianza unitaria. Questo aiuta a evitare che alcune caratteristiche dominino il modello a causa di differenze di scala.
Lo scaler è addestrato sui dati di training usando il metodo fit_transform(). I dati di test vengono poi trasformati separatamente con il metodo transform() per garantire che siano scalati con gli stessi fattori dei dati di training, evitando leakage.
Per creare un modello di regressione lineare, importa LinearRegression() da sklearn.linear_model. Invocalo e assegnalo a una variabile.
# Import LinearRegression.
from sklearn.linear_model import LinearRegression
# Instantiate linear regression model.
model = LinearRegression()Adattare il modello con i dati di training è semplice.
# Fit the model to the training data.
model.fit(X_train_scaled, y_train)Ora che abbiamo addestrato il modello, facciamo previsioni sul set di test.
# Make predictions on the testing data.
y_pred = model.predict(X_test_scaled)Ora che abbiamo fatto previsioni sul set di test, dobbiamo capire quanto bene coincidano con la realtà. Esistono diverse metriche per valutare le prestazioni di un algoritmo di regressione. Le più comuni sono il coefficiente di determinazione (R2), l'errore quadratico medio (MSE) e la radice dell'errore quadratico medio (RMSE).
Il coefficiente di determinazione, indicato con R2, misura quanto bene un modello di regressione spiega la variabilità della variabile target. In altre parole, quantifica quanta parte della variabilità della variabile target è spiegata dai predittori, nota come bontà dell'adattamento.
Per capirlo meglio, osserviamo la formula:
![]()
dove yactual sono i valori effettivi della variabile target, ypredicted sono i valori previsti dal modello e ȳ è la media dei valori effettivi. Questa formula aiuta a capire quanta varianza della variabile target è spiegata dal modello. Il denominatore rappresenta la varianza totale nei dati, mentre il numeratore rappresenta la varianza non spiegata dopo l'applicazione del modello di regressione. Il rapporto fornisce quindi la percentuale di varianza spiegata dal modello.
Come si interpreta R2?
Alcune considerazioni chiave da tenere a mente.
Valutare le prestazioni del modello usando il coefficiente di determinazione è facile con scikit-learn.
# Import metrics.
from sklearn.metrics import mean_squared_error, r2_score
# Calculate and print R^2 score.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")R-squared: 0.0138Altre metriche comunemente usate sono l'errore quadratico medio (MSE) e la radice dell'errore quadratico medio (RMSE). Queste metriche misurano quanto le previsioni del modello si discostano dai valori reali.
L'MSE calcola la differenza quadratica media tra valori reali e previsti:
sul numero totale di osservazioni n. Poiché gli errori vengono elevati al quadrato prima della media, gli errori più grandi sono penalizzati più pesantemente di quelli piccoli, rendendo l'MSE sensibile ai valori anomali. Un MSE più basso indica un miglior adattamento del modello.
Per affrontare queste problematiche, si usa l'RMSE, che è semplicemente la radice quadrata dell'MSE. Poiché l'RMSE è nelle stesse unità della variabile target, fornisce una misura più interpretabile di quanto, in media, le previsioni si discostino dai valori reali.
Calcolare MSE e RMSE è semplice con scikit-learn.
# Calculate and print MSE.
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
# Calculate and print RMSE.
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")Mean squared error: 1.2923
Root mean squared error: 1.1368Eseguiamo di nuovo il modello usando tutte le caratteristiche disponibili, non solo il numero medio di stanze. Ti aspetti risultati migliori o peggiori?
# Uses all features.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load data set.
housing = fetch_california_housing()
# Split into X, y.
X = pd.DataFrame(housing.data, columns=housing.feature_names)
y = housing.target # Median house value in $100,000s
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data.
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create model and fit it to the training data.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions.
y_pred = model.predict(X_test_scaled)
# Calculate and print errors.
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2:.4f}")
mse = mean_squared_error(y_test, y_pred)
print(f"Mean squared error: {mse:.4f}")
rmse = mse ** 0.5
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5758
Mean squared error: 0.5559
Root mean squared error: 0.7456Vediamo che i risultati sono nettamente migliori rispetto all'uso di una sola caratteristica. Tuttavia, questo solleva la domanda se ci servano tutte le caratteristiche. Alcune sono più rilevanti di altre? La scelta delle caratteristiche più rilevanti dal dataset è nota come feature selection.
La feature selection è importante per diversi motivi.
Quando più caratteristiche sono altamente correlate, sono ridondanti, cioè forniscono essenzialmente la stessa informazione al modello. Questa situazione è detta multicollinearità. Sebbene la multicollinearità non influisca sempre sull'accuratezza dei modelli predittivi, complica la selezione e l'interpretazione delle caratteristiche, soprattutto nella regressione lineare e modelli affini.
Il Variance Inflation Factor (VIF) è una metrica usata per rilevare la multicollinearità tra i predittori. Per ciascun predittore, il VIF è calcolato come:
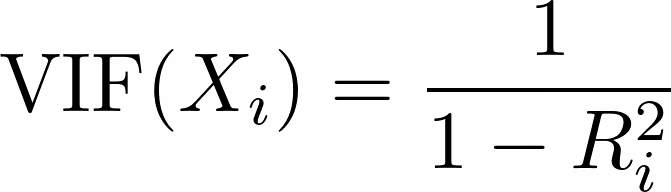
dove Ri2 è il valore di R2 ottenuto quando il predittore Xi viene messo in regressione rispetto a tutti gli altri predittori nel modello. Un VIF più alto indica che il predittore è altamente correlato con altre variabili.
# Import libraries.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from statsmodels.stats.outliers_influence import variance_inflation_factor
# Load the dataset.
housing = fetch_california_housing()
X = pd.DataFrame(housing.data, columns=housing.feature_names)
# Compute the correlation matrix.
corr_matrix = X.corr()
# Identify pairs of features with high collinearity (correlation > 0.8 or < -0.8).
high_corr_features = [(col1, col2, corr_matrix.loc[col1, col2])
for col1 in corr_matrix.columns
for col2 in corr_matrix.columns
if col1 != col2 and abs(corr_matrix.loc[col1, col2]) > 0.8]
# Convert to a DataFrame for better visualization.
collinearity_df = pd.DataFrame(high_corr_features, columns=["Feature 1", "Feature 2", "Correlation"])
print("\nHighly Correlated Features:\n", collinearity_df)
# Compute Variance Inflation Factor (VIF) for each feature.
vif_data = pd.DataFrame()
vif_data["Feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
# Print VIF values.
print("\nVariance Inflation Factor (VIF) for each feature:\n", vif_data) Highly Correlated Features:
Feature 1 Feature 2 Correlation
0 AveRooms AveBedrms 0.847621
1 AveBedrms AveRooms 0.847621
2 Latitude Longitude -0.924664
3 Longitude Latitude -0.924664
Variance Inflation Factor (VIF) for each feature:
Feature VIF
0 MedInc 11.511140
1 HouseAge 7.195917
2 AveRooms 45.993601
3 AveBedrms 43.590314
4 Population 2.935745
5 AveOccup 1.095243
6 Latitude 559.874071
7 Longitude 633.711654Rimuoviamo AveBedrms dal modello.
# Import libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load California housing dataset.
housing = fetch_california_housing()
# Create DataFrame and remove "AveBedrms" feature.
X = pd.DataFrame(housing.data, columns=housing.feature_names).drop(columns=["AveBedrms"])
y = housing.target # Median house value in $100,000s
# Split data into training and testing sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data (Standardization).
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create a linear regression model and train it.
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Make predictions on the test set.
y_pred = model.predict(X_test_scaled)
# Calculate performance metrics.
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
# Print evaluation metrics
print(f"R-squared: {r2:.4f}")
print(f"Mean squared error: {mse:.4f}")
print(f"Root mean squared error: {rmse:.4f}")R-squared: 0.5823
Mean squared error: 0.5473
Root mean squared error: 0.7398I risultati sono (leggermente) migliorati.
Costruire un modello di regressione è solo il primo passo; comprenderne gli output è altrettanto importante. Analizzando i coefficienti del modello, possiamo determinare quali caratteristiche hanno l'impatto più significativo sulle previsioni.
Una volta addestrato un modello di regressione lineare, i coefficienti sono accessibili con model.coef_. L'intercetta è accessibile con model.intercept_.
Una volta addestrato un modello di regressione lineare con LinearRegression(), i coefficienti sono accessibili con model.coef_ e l'intercetta con model.intercept_.
print("Intercept:", model.intercept_)
coeff_df = pd.DataFrame({"Feature": X.columns, "Coefficient": model.coef_})
print("\nFeature Coefficients:\n", coeff_df) Intercept: 2.0719469373788777
Feature Coefficients:
Feature Coefficient
0 MedInc 0.725747
1 HouseAge 0.121519
2 Latitude -0.943105
3 Longitude -0.900735Poiché Scikit-Learn non fornisce un metodo summary() integrato come Statsmodels, possiamo estrarre e visualizzare manualmente l'importanza di ciascuna caratteristica usando i coefficienti della regressione. Le caratteristiche con coefficienti assoluti maggiori hanno un impatto più forte sulla variabile target. Considera il seguente codice.
# Sort dataframe by coefficients.
coef_df_sorted = coef_df.sort_values(by="Coefficient", ascending=False)
# Create plot.
plt.figure(figsize=(8,6))
plt.barh(coef_df["Feature"], coef_df_sorted["Coefficient"], color="blue")
plt.xlabel("Coefficient Value")
plt.ylabel("Feature")
plt.title("Feature Importance (Linear Regression Coefficients)")
plt.show()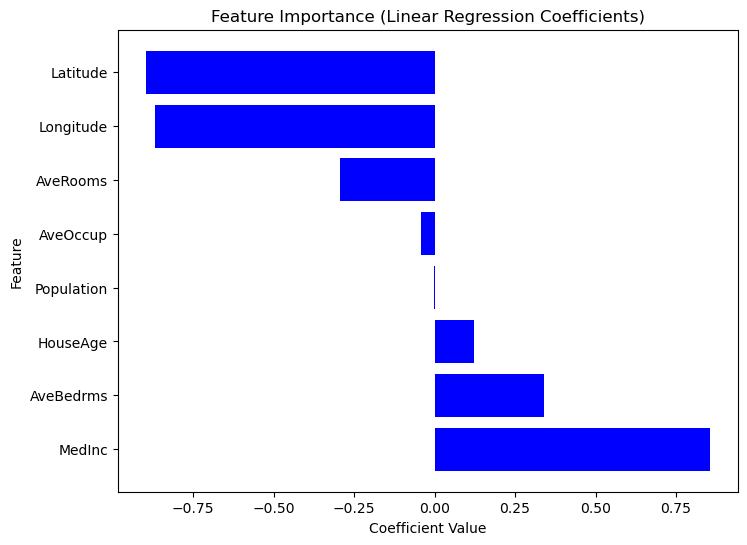
Grafico dell'importanza delle caratteristiche in base ai valori dei coefficienti
Ora visualizziamo i residui e l'adattamento della regressione.
# Compute residuals.
residuals = y_test - y_pred
# Create plots.
plt.figure(figsize=(12,5))
# Plot 1: Residuals Distribution.
plt.subplot(1,2,1)
sns.histplot(residuals, bins=30, kde=True, color="blue")
plt.axvline(x=0, color='red', linestyle='--')
plt.title("Residuals Distribution")
plt.xlabel("Residuals (y_actual - y_predicted)")
plt.ylabel("Frequency")
# Plot 2: Regression Fit (Actual vs Predicted).
plt.subplot(1,2,2)
sns.scatterplot(x=y_test, y=y_pred, alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--') # Perfect fit line
plt.title("Regression Fit: Actual vs Predicted")
plt.xlabel("Actual Prices (in $100,000s)")
plt.ylabel("Predicted Prices (in $100,000s)")
# Show plots.
plt.tight_layout()
plt.show()
Grafici per visualizzare i residui e l'adattamento della regressione
La distribuzione dei residui (grafico a sinistra) dovrebbe essere centrata intorno a zero, indicando che gli errori sono distribuiti casualmente. Se i residui seguono una distribuzione normale, il modello si adatta bene; se invece mostrano asimmetria o un trend, potrebbero indicare errori sistematici. L'adattamento della regressione (grafico a destra) confronta valori reali vs. previsti, con la linea tratteggiata rossa che rappresenta un adattamento perfetto. Se i punti seguono da vicino la linea, le previsioni sono accurate; se compare un pattern (ad esempio una curva), la relazione potrebbe non essere realmente lineare.
Queste visualizzazioni aiutano a diagnosticare overfitting o underfitting, rivelano pattern nei residui che suggeriscono relazioni mancanti e forniscono una valutazione chiara dell'efficacia del modello.
La regressione lineare è ampiamente utilizzata in molti settori per previsione e decision-making. Nel real estate, stima i prezzi delle case in base a fattori come dimensione e posizione.
Vendite e marketing la usano per la previsione della domanda e l'ottimizzazione del budget, mentre l'healthcare la applica alla valutazione del rischio di malattie. In finanza, aiuta nella previsione dei prezzi azionari e nello scoring del credito e, nella manifattura, supporta il controllo qualità e la previsione dei guasti.
La regressione lineare rimane una delle tecniche più fondamentali e utilizzate nel machine learning e nella modellazione statistica. Nonostante la sua semplicità, è uno strumento potente per comprendere le relazioni tra variabili e fare previsioni in numerose applicazioni reali.
Ecco i punti chiave del tutorial:
Per ulteriori informazioni sull'interpolazione di stringhe in Python, consulta le risorse di DataCamp.
I migliori corsi DataCamp
Programma
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

