
Program
Insinyur Pembelajaran Mesin
44 Hr
Konsep cross-entropy berakar dari teori informasi, di mana entropi informasi, juga dikenal sebagai entropi Shannon, diperkenalkan secara formal pada 1948 oleh Claude Shannon dalam makalah berjudul “A Mathematical Theory of Communication.” Sebelum membahas cross-entropy, mari pahami entropi.
Entropi menghitung derajat keacakan atau ketidakteraturan dalam suatu sistem. Dalam konteks teori informasi, entropi dari sebuah variabel acak adalah ketidakpastian, kejutan, atau informasi rata-rata yang melekat pada kemungkinan hasil. Sederhananya, ini mengukur ketidakpastian suatu peristiwa.
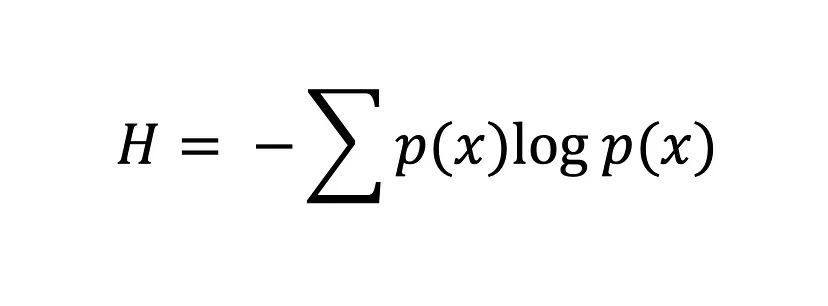
Persamaan entropi Shannon
Semakin besar nilai entropi, H(x), semakin besar ketidakpastian untuk distribusi probabilitas, dan semakin kecil nilainya, semakin rendah ketidakpastiannya.
Cross-entropy, juga dikenal sebagai logarithmic loss atau log loss, adalah fungsi loss populer dalam machine learning untuk mengukur kinerja model klasifikasi.
Ini mengukur jumlah bit rata-rata yang diperlukan untuk mengidentifikasi sebuah peristiwa dari satu distribusi probabilitas, p, menggunakan kode optimal untuk distribusi probabilitas lain, q. Dengan kata lain, cross-entropy mengukur perbedaan antara distribusi probabilitas yang ditemukan oleh model klasifikasi dan nilai prediksinya.
Fungsi loss cross-entropy digunakan untuk mencari solusi optimal dengan menyesuaikan bobot model machine learning selama pelatihan. Tujuannya adalah meminimalkan kesalahan antara hasil aktual dan hasil prediksi. Nilai cross-entropy yang lebih rendah menunjukkan kinerja yang lebih baik. Optimisasi ini terjadi melalui gradient descent, di mana gradien dari fungsi loss memandu pembaruan parameter.
Jika Anda familier dengan Kullback-Leibler (KL) Divergence, Anda mungkin bertanya, “Apa perbedaan antara cross-entropy dan KL divergence?” Pertanyaan yang wajar. Keduanya banyak digunakan untuk mengukur perbedaan atau kesamaan distribusi probabilitas. Meskipun memiliki kesamaan, keduanya melayani tujuan yang berbeda.
Seperti disebutkan di atas, cross-entropy mengukur jumlah bit rata-rata yang diperlukan untuk mengidentifikasi peristiwa dari satu distribusi probabilitas, P, menggunakan kode optimal untuk distribusi probabilitas lain, Q, dan biasanya digunakan dalam machine learning untuk mengevaluasi kinerja model dengan tujuan meminimalkan kesalahan antara distribusi probabilitas yang diprediksi dan distribusi sebenarnya.
Sebaliknya, KL divergence mengukur perbedaan antara dua distribusi probabilitas, P dan Q. Secara spesifik, KL divergence mengkuantifikasi jumlah informasi yang hilang ketika Q digunakan untuk mendekati P. Ini sangat berguna dalam tugas pembelajaran tanpa pengawasan (unsupervised) di mana tujuannya adalah menemukan struktur dalam data dengan meminimalkan divergensi antara distribusi data sebenarnya dan distribusi data yang dipelajari.
Dalam machine learning, fungsi loss membantu model mengetahui seberapa salah prediksinya dan memperbaiki diri berdasarkan kesalahan tersebut. Ini adalah fungsi matematis yang mengkuantifikasi perbedaan antara nilai prediksi dan nilai aktual dalam model machine learning, namun fungsinya tidak hanya itu.
Ukuran kesalahan dari fungsi loss juga berperan sebagai panduan selama proses optimisasi dengan memberikan umpan balik ke model tentang seberapa baik kecocokannya dengan data. Karena itu, sebagian besar model machine learning menerapkan fungsi loss selama fase optimisasi, di mana parameter model dipilih untuk membantu model meminimalkan kesalahan dan mencapai solusi optimal–semakin kecil kesalahan, semakin baik modelnya.
Kita dapat mengukur kesalahan antara dua distribusi probabilitas menggunakan fungsi loss cross-entropy. Misalnya, anggap kita melakukan tugas klasifikasi biner (tugas klasifikasi dengan dua kelas, 0 dan 1).
Dalam kasus ini, kita harus menggunakan binary cross-entropy, yaitu cross-entropy rata-rata di seluruh sampel data:

Rumus binary cross entropy [Sumber: Cross-Entropy Loss Function]
Jika kita menghitung loss dari satu titik data dengan nilai benar y=1, berikut bentuk persamaannya:
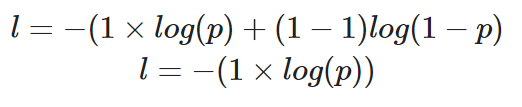
Menghitung binary cross-entropy untuk satu instance saat nilai sebenarnya 1
Probabilitas prediksi, p, menentukan nilai loss, l. Jika nilai p tinggi, model akan diberi penghargaan karena membuat prediksi yang benar—hal ini ditunjukkan dengan nilai loss, l, yang rendah.
Namun, probabilitas prediksi p yang rendah menyiratkan model salah, dan fungsi loss binary cross-entropy akan mencerminkannya dengan membuat nilai l menjadi lebih tinggi.
Untuk tugas klasifikasi multi-kelas, cross-entropy (sering juga disebut categorical cross-entropy) dapat diperluas sebagai berikut. Dalam kasus ini, lapisan keluaran biasanya menggunakan fungsi aktivasi softmax untuk menghasilkan distribusi probabilitas di semua kelas:
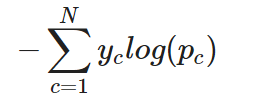
Categorical cross-entropy untuk satu instance
Dengan kata lain, untuk menerapkan cross-entropy pada tugas klasifikasi multi-kelas, loss untuk setiap kelas dihitung secara terpisah lalu dijumlahkan untuk menentukan total loss.
Cross-entropy loss adalah pilihan standar untuk tugas klasifikasi, namun memahami kapan menggunakan masing-masing variannya membantu Anda membangun model yang lebih baik:
| Fungsi Loss | Kasus Penggunaan | Aktivasi Keluaran | Contoh |
|---|---|---|---|
| Binary Cross-Entropy | Dua kelas (0 atau 1) | Sigmoid | Deteksi spam, diagnosis medis |
| Categorical Cross-Entropy | Banyak kelas yang saling eksklusif | Softmax | Klasifikasi gambar, analisis sentimen |
| Binary Cross-Entropy (multi-label) | Banyak label per sampel | Sigmoid (per keluaran) | Penandaan gambar, kategorisasi dokumen |
Pada bagian tutorial ini, kita akan mempelajari cara menggunakan fungsi loss cross-entropy di TensorFlow dan PyTorch.
Mari mulai dengan membuat dataset. Kita akan menggunakan fungsi make_classification dari Scikit-learn untuk membantu kita:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training data
X, y = make_classification(
n_samples=10000,
n_informative=10,
random_state=2022
)
# split into train and test
X_new, X_test = X[:9000, :], X[9000:, ]
y_new, y_test = y[:9000], y[9000:]
X_train, X_val, y_train, y_val = train_test_split(
X_new, y_new,
test_size=0.3
)
print(f"Train data: {X_train.shape}\n\
Train labels: {y_train.shape}\n\
Test data: {X_test.shape}\n\
Test labels: {y_test.shape}")
"""
Train data: (6300, 20)
Train labels: (6300,)
Test data: (1000, 20)
Test labels: (1000,)
"""Model yang akan kita bangun terdiri dari lapisan input, satu lapisan tersembunyi, dan lapisan output.
Karena ini adalah tugas klasifikasi biner, kita akan menggunakan binary cross-entropy sebagai fungsi loss. Lapisan output menggunakan fungsi aktivasi sigmoid untuk menghasilkan probabilitas antara 0 dan 1.
import tensorflow as tf
# Build and train model
model = tf.keras.Sequential([
tf.keras.layers.Dense(10,
input_shape=(X_train.shape[1],),
activation="relu"),
tf.keras.layers.Dense(10,
activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(
loss="binary_crossentropy", # loss function here
optimizer="adam",
metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=20, validation_data=[X_val, y_val], verbose=0)Selanjutnya, kita akan memplot loss untuk melihat apakah model membaik–artinya kesalahan berkurang pada setiap epoch hingga tidak dapat meningkat lagi.
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()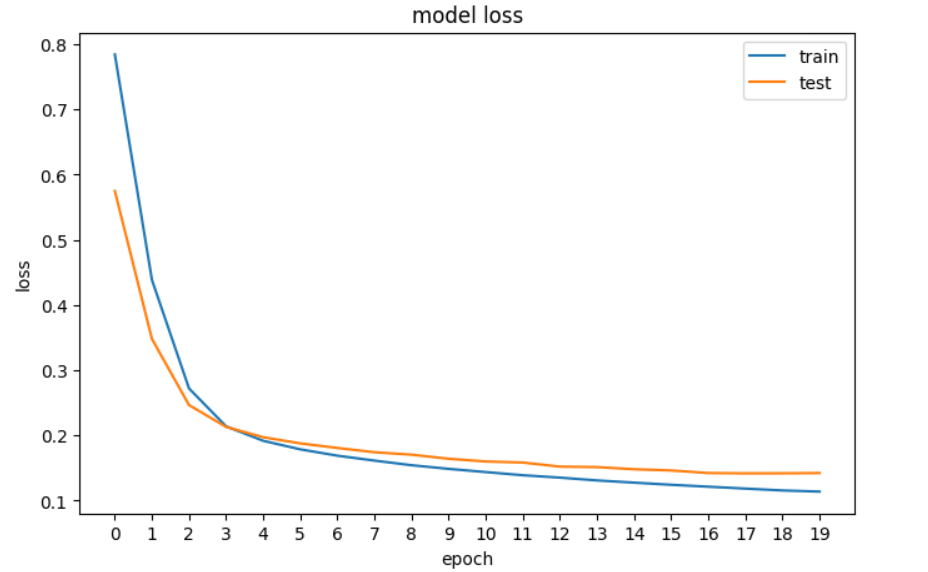
Plot loss jaringan saraf kita di TensorFlow.
Di PyTorch, input, output, dan parameter model dikodekan menggunakan tensor, yang berarti kita harus mengonversi array Numpy menjadi tensor. Itulah yang pertama kita lakukan pada kode di bawah ini, lalu kita membangun jaringan saraf dan mencetak dimensinya.
import torch
import torch.nn as nn
import torch.optim as optim
# Convert numpy arrays to tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_val_tensor = torch.tensor(X_val, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
y_val_tensor = torch.tensor(y_val, dtype=torch.float32).reshape(-1, 1)
# Build the model
input_dim = X_train.shape[1]
hidden_dim = 10
output_dim = 1
model = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)
print(model)
"""
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=10, bias=True)
(3): ReLU()
(4): Linear(in_features=10, out_features=1, bias=True)
(5): Sigmoid()
)
"""Berikutnya, kita mendefinisikan fungsi loss binary cross-entropy dan optimizer:
loss_fn = nn.BCELoss() # binary cross entropy
optimizer = optim.Adam(model.parameters(), lr=0.001)Sekarang kita perlu melatih model. Berikut loop pelatihannya:
# Training loop
n_epochs = 20
train_loss = []
val_loss = []
for epoch in range(n_epochs):
# Training
model.train()
y_pred = model(X_train_tensor)
loss = loss_fn(y_pred, y_train_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# Validation
model.eval()
with torch.no_grad():
y_val_pred = model(X_val_tensor)
v_loss = loss_fn(y_val_pred, y_val_tensor)
val_loss.append(v_loss.item())Dan sekarang memplot loss:
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()
Plot loss jaringan saraf kita di PyTorch
Berikut rangkuman singkat tentang apa yang telah kita pelajari mengenai loss cross-entropy:
Untuk melanjutkan pembelajaran Anda, lihat sumber daya kami:
Mulai Perjalanan Machine Learning Anda Hari Ini!
Program
Program
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
