
programa
Ingeniero de Aprendizaje Automático
44 h
El concepto de entropía cruzada hunde sus raíces en el campo de la teoría de la información, donde la entropía de la información, también conocida como entropía de Shannon, fue introducida formalmente en 1948 por Claude Shannon en un artículo titulado "Una teoría matemática de la comunicación". Antes de abordar la entropía cruzada, tratemos la entropía.
La entropía calcula el grado de aleatoriedad o desorden de un sistema. En el contexto de la teoría de la información, la entropía de una variable aleatoria es la incertidumbre, sorpresa o información media inherente a los posibles resultados. En pocas palabras, mide la incertidumbre de un acontecimiento.
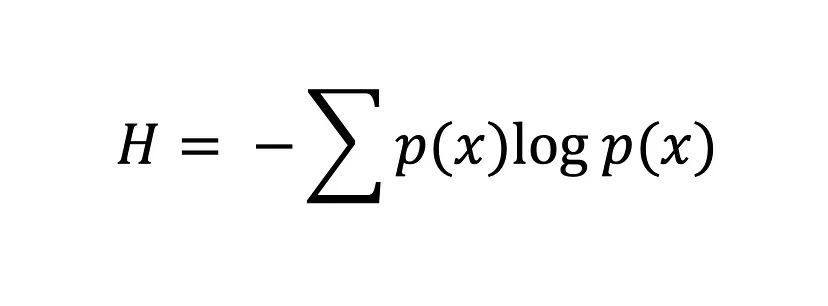
La ecuación de entropía de Shannon
Cuanto mayor sea el valor de la entropía, H(x), mayor será la incertidumbre de la distribución de probabilidad, y cuanto menor sea el valor, menor será la incertidumbre.
La entropía cruzada, también conocida como pérdida logarítmica o pérdida logarítmica, es una popular función de pérdida utilizada en el aprendizaje automático para medir el rendimiento de un modelo de clasificación.
Mide el número medio de bits necesarios para identificar un suceso de una distribución de probabilidad, p, utilizando el código óptimo para otra distribución de probabilidad, q. En otras palabras, la entropía cruzada mide la diferencia entre la distribución de probabilidad descubierta de un modelo de clasificación y los valores predichos.
La función de pérdida de entropía cruzada se utiliza para encontrar la solución óptima ajustando los pesos de un modelo de aprendizaje automático durante el entrenamiento. El objetivo es minimizar el error entre los resultados reales y los previstos. Un valor de entropía cruzada más bajo indica un mejor rendimiento.
Si conoces la divergencia de Kullback-Leibler (KL), quizá te preguntes: "¿Qué diferencia hay entre la entropía cruzada y la divergencia KL?". Y es una pregunta justa. Ambos conceptos se utilizan ampliamente para medir las diferencias o similitudes de las distribuciones de probabilidad. Aunque comparten algunas similitudes, tienen finalidades diferentes.
Como ya se ha dicho, la entropía cruzada mide el número medio de bits necesarios para identificar un suceso de una distribución de probabilidad, P, utilizando el código óptimo para otra distribución de probabilidad, Q, y se suele utilizar en el aprendizaje automático para evaluar el rendimiento de un modelo cuyo objetivo es minimizar el error entre la distribución de probabilidad predicha y la distribución verdadera.
En cambio, la divergencia KL mide la diferencia entre dos distribuciones de probabilidad, P y Q. Es decir, la divergencia KL cuantifica la cantidad de pérdida de información cuando se utiliza Q para aproximar P. Esto es increíblemente útil en tareas de aprendizaje no supervisado en las que el objetivo es descubrir la estructura de los datos minimizando la divergencia entre las distribuciones de datos verdaderas y aprendidas.
En el aprendizaje automático, las funciones de pérdida ayudan a los modelos a determinar lo equivocados que están y a mejorarse a sí mismos basándose en esa equivocación. Son funciones matemáticas que cuantifican la diferencia entre los valores predichos y los reales en un modelo de aprendizaje automático, pero esto no es todo lo que hacen.
La medida del error de una función de pérdida también sirve de guía durante el proceso de optimización, al proporcionar información al modelo sobre lo bien que se ajusta a los datos. De ahí que la mayoría de los modelos de aprendizaje automático apliquen una función de pérdida durante la fase de optimización, en la que los parámetros del modelo se eligen para ayudarle a minimizar el error y llegar a una solución óptima: cuanto menor sea el error, mejor será el modelo.
Podemos medir el error entre dos distribuciones de probabilidad utilizando la función de pérdida de entropía cruzada. Por ejemplo, supongamos que estamos realizando una tarea de clasificación binaria (una tarea de clasificación con dos clases, 0 y 1).
En este caso, debemos utilizar la entropía cruzada binaria, que es la entropía cruzada media de todas las muestras de datos:

Fórmula de la entropía cruzada binaria [Fuente: Función de pérdida de entropía cruzada]
Si tuviéramos que calcular la pérdida de un único punto de datos en el que el valor correcto es y=1, así es como quedaría nuestra ecuación:
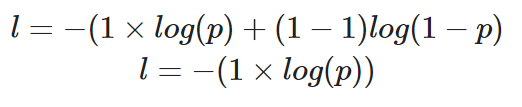
Cálculo de la entropía cruzada binaria para un único caso en el que el valor verdadero es 1
La probabilidad prevista, p, determina el valor de la pérdida, l. Si el valor de p es alto, el modelo será recompensado por hacer una predicción correcta, lo que se ilustrará con un valor bajo de pérdida, l.
Sin embargo, una probabilidad predicha baja, p, inferiría que el modelo era incorrecto, y la función de pérdida de entropía cruzada binaria lo reflejará haciendo que el valor de l sea más alto.
Para una tarea de clasificación multiclase, la entropía cruzada (o entropía cruzada categórica, como suele denominarse) puede ampliarse sencillamente como sigue:
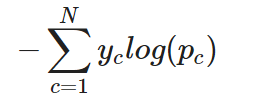
Entropía cruzada categórica para una única instancia
En otras palabras, para aplicar la entropía cruzada a una tarea de clasificación multiclase, la pérdida de cada clase se calcula por separado y luego se suma para determinar la pérdida total.
En esta parte del tutorial, aprenderemos a utilizar la función de pérdida de entropía cruzada en TensorFlow y PyTorch.
Empecemos por crear el conjunto de datos. Utilizaremos la función make_classification de Scikit learns para ayudarnos:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# create training data
X, y = make_classification(
n_samples=10000,
n_informative=10,
random_state=2022
)
# split into train and test
X_new, X_test = X[:9000, :], X[9000:, ]
y_new, y_test = y[:9000], y[9000:]
X_train, X_val, y_train, y_val = train_test_split(
X_new, y_new,
test_size=0.3
)
print(f"Train data: {X_train.shape}\n\
Train labels: {y_train.shape}\n\
Test data: {X_test.shape}\n\
Test labels: {y_test.shape}")
"""
Train data: (6300, 20)
Train labels: (6300,)
Test data: (1000, 20)
Test labels: (1000,)
"""El modelo que construiremos constará de una capa de entrada, una capa oculta y una capa de salida.
Como se trata de una tarea de clasificación binaria, utilizaremos la entropía cruzada binaria como función de pérdida.
# building and training model
model = tf.keras.Sequential([
tf.keras.layers.Dense(10,
input_shape=(X_train.shape[1],),
activation="relu"),
tf.keras.layers.Dense(10,
activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(
loss="binary_crossentropy", # loss function here
optimizer="adam",
metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=20, validation_data=[X_val, y_val], verbose=0)A continuación, trazaremos la pérdida para ver si el modelo está mejorando, es decir, si el error disminuye con cada época hasta que ya no puede mejorar.
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()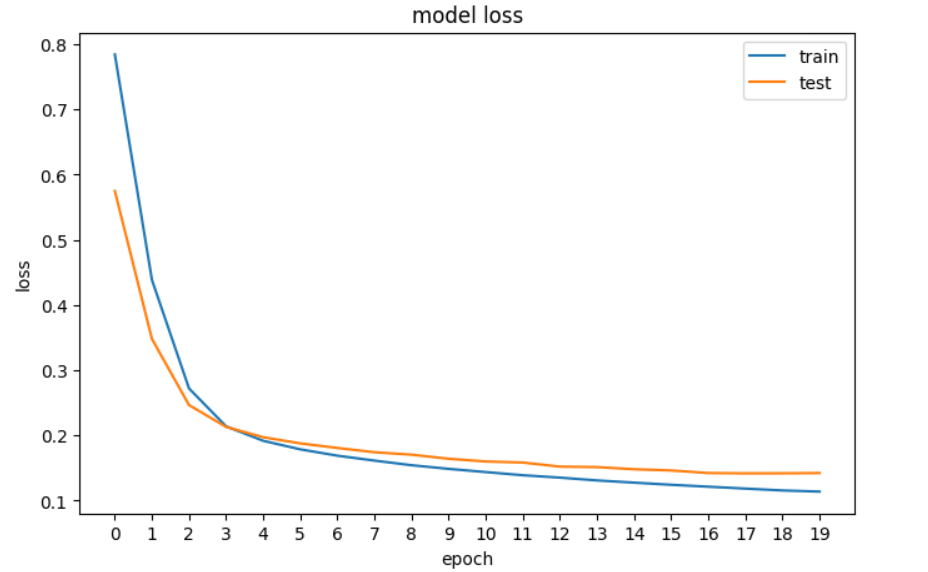
Un gráfico de la pérdida de nuestra red neuronal en TensorFlow.
En PyTorch, las entradas, salidas y parámetros del modelo se codifican mediante tensores, lo que significa que debemos convertir nuestras matrices Numpy en tensores. Eso es lo primero que hacemos en el código siguiente, y luego construimos la red neuronal e imprimimos sus dimensiones.
# convert numpy arrays to tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_val_tensor = torch.tensor(X_val, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
y_val_tensor = torch.tensor(y_val, dtype=torch.float32).reshape(-1, 1)
# build the model
input_dim = X_train.shape[1]
hidden_dim = 10
output_dim = 1
model = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)
print(model)
"""
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=10, bias=True)
(3): ReLU()
(4): Linear(in_features=10, out_features=1, bias=True)
(5): Sigmoid()
)
"""A continuación, definimos la función de pérdida de entropía cruzada binaria y el optimizador:
loss_fn = nn.BCELoss() # binary cross entropy
optimizer = optim.Adam(model.parameters(), lr=0.001)Y ahora a tramar la pérdida:
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()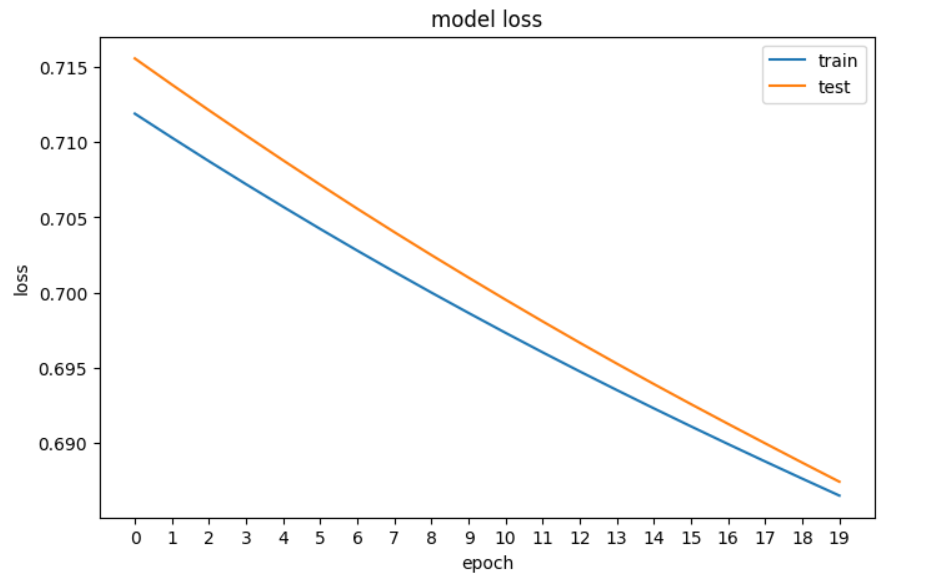
Un gráfico de la pérdida de nuestra red neuronal en PyTorch
He aquí un rápido resumen de lo que hemos aprendido sobre la pérdida de entropía cruzada:
Para seguir aprendiendo, consulta nuestros recursos:
¡Empieza hoy tu viaje de aprendizaje automático!
programa
programa
Curso
blog
Abid Ali Awan
7 min
Tutorial
Richmond Alake
Tutorial
Bex Tuychiev
Tutorial
Joanne Xiong
Tutorial
Abid Ali Awan
Tutorial
Moez Ali



