
Leerpad
Machine Learning Engineer
44 Hr
Het concept van cross-entropy vindt zijn oorsprong in de informatietheorie, waar informatieentropie, ook wel Shannon-entropie, in 1948 formeel werd geïntroduceerd door Claude Shannon in het artikel “A Mathematical Theory of Communication.” Voordat we cross-entropy bespreken, staan we eerst stil bij entropie.
Entropie berekent de mate van willekeur of wanorde binnen een systeem. In de context van informatietheorie is de entropie van een willekeurige variabele de gemiddelde onzekerheid, verrassing of informatie die eigen is aan de mogelijke uitkomsten. Simpel gezegd: het meet de onzekerheid van een gebeurtenis.
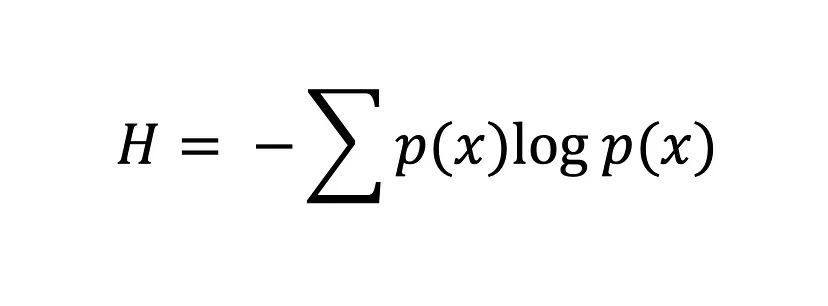
De Shannon-entropievergelijking
Hoe groter de waarde van de entropie, H(x), hoe groter de onzekerheid van de kansverdeling, en hoe kleiner de waarde, hoe minder onzekerheid.
Cross-entropy, ook bekend als logaritmisch verlies of log loss, is een populaire verliesfunctie in machine learning om de prestaties van een classificatiemodel te meten.
Het meet het gemiddelde aantal bits dat nodig is om een gebeurtenis uit de ene kansverdeling, p, te identificeren met behulp van de optimale code voor een andere kansverdeling, q. Met andere woorden: cross-entropy meet het verschil tussen de gevonden kansverdeling van een classificatiemodel en de voorspelde waarden.
De cross-entropy-verliesfunctie wordt gebruikt om de optimale oplossing te vinden door tijdens het trainen de gewichten van een machinelearningmodel aan te passen. Het doel is de fout tussen de werkelijke en voorspelde uitkomsten te minimaliseren. Een lagere cross-entropy-waarde duidt op betere prestaties. Deze optimalisatie gebeurt via gradient descent, waarbij de gradiënten van de verliesfunctie de parameterupdates sturen.
Als je bekend bent met de Kullback-Leibler (KL) Divergence, vraag je je wellicht af: “Wat is het verschil tussen cross-entropy en KL-divergentie?” Een terechte vraag. Beide concepten worden veel gebruikt om verschillen of overeenkomsten tussen kansverdelingen te meten. Hoewel ze overeenkomsten delen, dienen ze verschillende doelen.
Zoals hierboven genoemd, meet cross-entropy het gemiddelde aantal bits dat nodig is om een gebeurtenis uit een kansverdeling P te identificeren met de optimale code voor een andere verdeling Q, en wordt het doorgaans gebruikt in machine learning om de prestaties van een model te evalueren waarbij het doel is de fout tussen de voorspelde en de ware kansverdeling te minimaliseren.
Daarentegen meet KL-divergentie het verschil tussen twee kansverdelingen, P en Q. Concreet kwantificeert KL-divergentie de hoeveelheid informatieverlies wanneer Q wordt gebruikt om P te benaderen. Dit is bijzonder nuttig bij unsupervised learning-taken, waar het doel is om structuur in data te ontdekken door de divergentie tussen de ware en de geleerde dataverdelingen te minimaliseren.
In machine learning helpen verliesfuncties modellen te bepalen hoe fout ze zitten en zich te verbeteren op basis van die fout. Het zijn wiskundige functies die het verschil kwantificeren tussen voorspelde en werkelijke waarden in een machinelearningmodel, maar dat is niet alles wat ze doen.
De gemeten fout van een verliesfunctie dient ook als leidraad tijdens het optimalisatieproces door het model feedback te geven over hoe goed het bij de data past. Daarom implementeren de meeste machinelearningmodellen een verliesfunctie tijdens de optimalisatiefase, waarin de modelparameters zo worden gekozen dat het model de fout minimaliseert en tot een optimale oplossing komt – hoe kleiner de fout, hoe beter het model.
We kunnen de fout tussen twee kansverdelingen meten met de cross-entropy-verliesfunctie. Stel bijvoorbeeld dat we een binaire classificatietaak uitvoeren (een classificatietaak met twee klassen, 0 en 1).
In dat geval gebruiken we binaire cross-entropy, de gemiddelde cross-entropy over alle datapunten:

Formule voor binaire cross-entropy [Bron: Cross-Entropy Loss Function]
Als we het verlies voor één datapunt zouden berekenen waarbij de juiste waarde y=1 is, ziet onze vergelijking er zo uit:
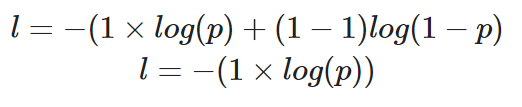
De binaire cross-entropy berekenen voor één instantie waar de werkelijke waarde 1 is
De voorspelde kans p bepaalt de waarde van het verlies l. Als de waarde van p hoog is, wordt het model beloond voor een juiste voorspelling — dat zie je terug in een lage verlieswaarde l.
Een lage voorspelde kans p impliceert daarentegen dat het model ongelijk had, en de binaire cross-entropy-verliesfunctie zal dit weerspiegelen door de waarde van l te verhogen.
Voor een multiclass-classificatietaak kan cross-entropy (vaak categorische cross-entropy genoemd) als volgt worden uitgebreid. In dit geval gebruikt de outputlaag doorgaans een softmax-activatiefunctie om een kansverdeling over alle klassen te produceren:
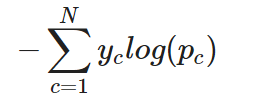
Categorische cross-entropy voor één instantie
Met andere woorden: om cross-entropy toe te passen op een multiclass-classificatietaak, wordt het verlies per klasse afzonderlijk berekend en daarna opgeteld om het totale verlies te bepalen.
Cross-entropy-verlies is de standaardkeuze voor classificatietaken, maar begrijpen wanneer je welke variant gebruikt, helpt je betere modellen te bouwen:
| Verliesfunctie | Usecase | Outputactivatie | Voorbeeld |
|---|---|---|---|
| Binaire cross-entropy | Twee klassen (0 of 1) | Sigmoid | Spamdetectie, medische diagnose |
| Categorische cross-entropy | Meerdere wederzijds exclusieve klassen | Softmax | Beeldclassificatie, sentimentanalyse |
| Binaire cross-entropy (multi-label) | Meerdere labels per sample | Sigmoid (per output) | Beeldtagging, documentcategorisatie |
In dit deel van de tutorial leren we hoe je de cross-entropy-verliesfunctie gebruikt in TensorFlow en PyTorch.
Laten we beginnen met het maken van de dataset. We gebruiken de functie make_classification van Scikit-learn om ons te helpen:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training data
X, y = make_classification(
n_samples=10000,
n_informative=10,
random_state=2022
)
# split into train and test
X_new, X_test = X[:9000, :], X[9000:, ]
y_new, y_test = y[:9000], y[9000:]
X_train, X_val, y_train, y_val = train_test_split(
X_new, y_new,
test_size=0.3
)
print(f"Train data: {X_train.shape}\n\
Train labels: {y_train.shape}\n\
Test data: {X_test.shape}\n\
Test labels: {y_test.shape}")
"""
Train data: (6300, 20)
Train labels: (6300,)
Test data: (1000, 20)
Test labels: (1000,)
"""Het model dat we bouwen bestaat uit een inputlaag, een verborgen laag en een outputlaag.
Omdat dit een binaire classificatietaak is, gebruiken we binaire cross-entropy als onze verliesfunctie. De outputlaag gebruikt een sigmoid-activatiefunctie om probabiliteiten tussen 0 en 1 te produceren.
import tensorflow as tf
# Build and train model
model = tf.keras.Sequential([
tf.keras.layers.Dense(10,
input_shape=(X_train.shape[1],),
activation="relu"),
tf.keras.layers.Dense(10,
activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(
loss="binary_crossentropy", # loss function here
optimizer="adam",
metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=20, validation_data=[X_val, y_val], verbose=0)Vervolgens plotten we het verlies om te zien of het model verbetert – met andere woorden: of de fout bij elke epoch afneemt totdat verdere verbetering uitblijft.
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()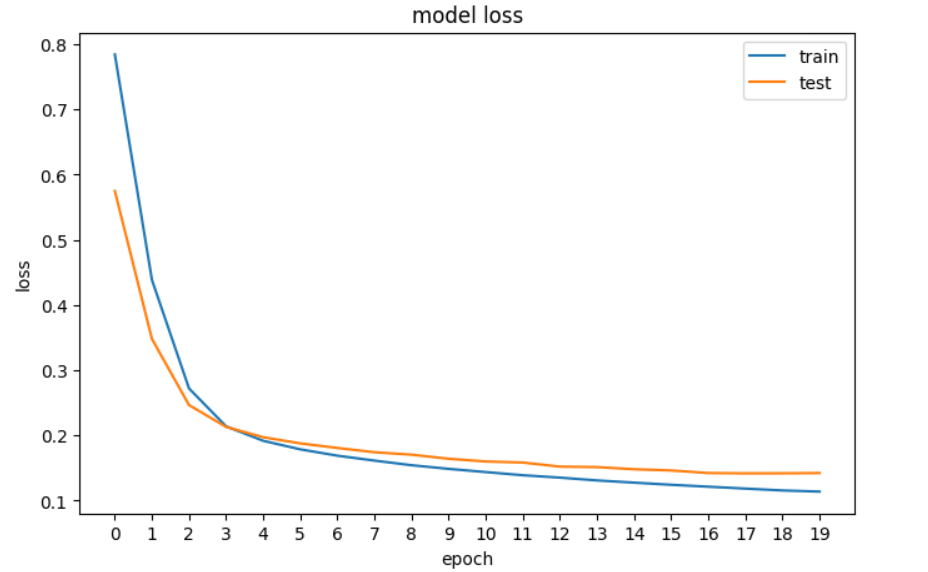
Een plot van het verlies van ons neurale netwerk in TensorFlow.
In PyTorch worden inputs, outputs en parameters van het model gecodeerd met tensors, wat betekent dat we onze Numpy-arrays moeten converteren naar tensors. Dat is het eerste wat we hieronder doen; daarna bouwen we het neurale netwerk en printen we de dimensies.
import torch
import torch.nn as nn
import torch.optim as optim
# Convert numpy arrays to tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_val_tensor = torch.tensor(X_val, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
y_val_tensor = torch.tensor(y_val, dtype=torch.float32).reshape(-1, 1)
# Build the model
input_dim = X_train.shape[1]
hidden_dim = 10
output_dim = 1
model = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)
print(model)
"""
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=10, bias=True)
(3): ReLU()
(4): Linear(in_features=10, out_features=1, bias=True)
(5): Sigmoid()
)
"""Vervolgens definiëren we de binaire cross-entropy-verliesfunctie en de optimizer:
loss_fn = nn.BCELoss() # binary cross entropy
optimizer = optim.Adam(model.parameters(), lr=0.001)Nu moeten we het model trainen. Dit is de trainingslus:
# Training loop
n_epochs = 20
train_loss = []
val_loss = []
for epoch in range(n_epochs):
# Training
model.train()
y_pred = model(X_train_tensor)
loss = loss_fn(y_pred, y_train_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# Validation
model.eval()
with torch.no_grad():
y_val_pred = model(X_val_tensor)
v_loss = loss_fn(y_val_pred, y_val_tensor)
val_loss.append(v_loss.item())En nu het verlies plotten:
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()
Een plot van het verlies van ons neurale netwerk in PyTorch
Hier is een korte samenvatting van wat we hebben geleerd over cross-entropy-verlies:
Wil je verder leren? Bekijk dan onze resources:
Begin vandaag nog aan je machine learning-reis!
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
