
Programa
Engenheiro de machine learning
44 h
O conceito de entropia cruzada tem suas raízes no campo da teoria da informação, onde a entropia da informação, também conhecida como entropia de Shannon, foi formalmente introduzida em 1948 por Claude Shannon em um artigo intitulado "A Mathematical Theory of Communication". Antes de abordarmos a entropia cruzada, vamos tratar da entropia.
A entropia calcula o grau de aleatoriedade ou desordem em um sistema. No contexto da teoria da informação, a entropia de uma variável aleatória é a incerteza média, a surpresa ou as informações inerentes aos possíveis resultados. Para simplificar, ele mede a incerteza de um evento.
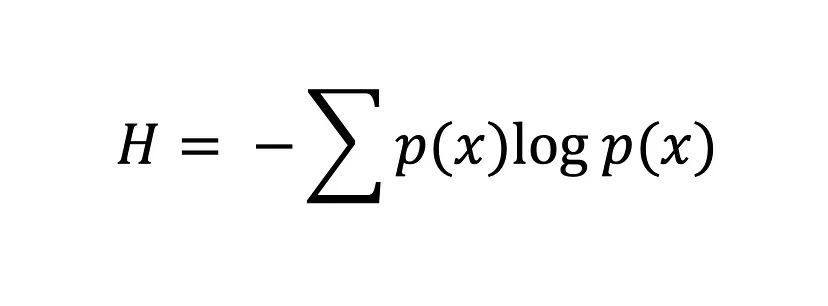
A equação da entropia de Shannon
Quanto maior for o valor da entropia, H(x), maior será a incerteza da distribuição de probabilidade, e quanto menor for o valor, menor será a incerteza.
A entropia cruzada, também conhecida como perda logarítmica ou perda de log, é uma função de perda popular usada no aprendizado de máquina para medir o desempenho de um modelo de classificação.
Ele mede o número médio de bits necessários para identificar um evento de uma distribuição de probabilidade, p, usando o código ideal para outra distribuição de probabilidade, q. Em outras palavras, a entropia cruzada mede a diferença entre a distribuição de probabilidade descoberta de um modelo de classificação e os valores previstos.
A função de perda de entropia cruzada é usada para encontrar a solução ideal, ajustando os pesos de um modelo de aprendizado de máquina durante o treinamento. O objetivo é minimizar o erro entre os resultados reais e os previstos. Um valor menor de entropia cruzada indica melhor desempenho.
Se você conhece a Divergência de Kullback-Leibler (KL), talvez se pergunte: "Qual é a diferença entre a entropia cruzada e a divergência KL?" E essa é uma pergunta justa. Ambos os conceitos são amplamente usados para medir as diferenças ou semelhanças das distribuições de probabilidade. Embora compartilhem algumas semelhanças, eles têm finalidades diferentes.
Conforme mencionado acima, a entropia cruzada mede o número médio de bits necessários para identificar um evento de uma distribuição de probabilidade, P, usando o código ideal para outra distribuição de probabilidade, Q, e é normalmente usada no aprendizado de máquina para avaliar o desempenho de um modelo em que o objetivo é minimizar o erro entre a distribuição de probabilidade prevista e a distribuição verdadeira.
Por outro lado, a divergência KL mede a diferença entre duas distribuições de probabilidade, P e Q. Ou seja, a divergência KL quantifica a quantidade de perda de informações quando Q é usado para aproximar P. Isso é incrivelmente útil em tarefas de aprendizado não supervisionado em que o objetivo é descobrir a estrutura nos dados, minimizando a divergência entre as distribuições de dados verdadeiras e aprendidas.
No aprendizado de máquina, as funções de perda ajudam os modelos a determinar o quanto estão errados e a se aperfeiçoar com base nesse erro. São funções matemáticas que quantificam a diferença entre os valores previstos e os reais em um modelo de aprendizado de máquina, mas não é só isso que elas fazem.
A medida de erro de uma função de perda também serve como guia durante o processo de otimização, fornecendo feedback ao modelo sobre a adequação aos dados. Por isso, a maioria dos modelos de aprendizado de máquina implementa uma função de perda durante a fase de otimização, em que os parâmetros do modelo são escolhidos para ajudar o modelo a minimizar o erro e chegar a uma solução ideal - quanto menor o erro, melhor o modelo.
Podemos medir o erro entre duas distribuições de probabilidade usando a função de perda de entropia cruzada. Por exemplo, vamos supor que estejamos realizando uma tarefa de classificação binária (uma tarefa de classificação com duas classes, 0 e 1).
Nesse caso, devemos usar a entropia cruzada binária, que é a entropia cruzada média em todas as amostras de dados:

Fórmula de entropia cruzada binária [Fonte: Função de perda de entropia cruzada]
Se tivéssemos que calcular a perda de um único ponto de dados em que o valor correto é y=1, nossa equação seria a seguinte
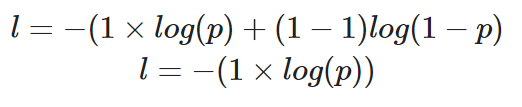
Cálculo da entropia cruzada binária para uma única instância em que o valor verdadeiro é 1
A probabilidade prevista, p, determina o valor da perda, l. Se o valor de p for alto, o modelo será recompensado por fazer uma previsão correta - isso será ilustrado com um valor baixo de perda, l.
No entanto, uma baixa probabilidade prevista, p, inferiria que o modelo está incorreto, e a função de perda de entropia cruzada binária refletirá isso aumentando o valor de l.
Para uma tarefa de classificação multiclasse, a entropia cruzada (ou entropia cruzada categórica, como é frequentemente chamada) pode ser simplesmente estendida da seguinte forma:
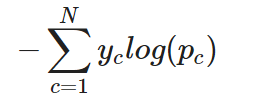
Entropia cruzada categórica para uma única instância
Em outras palavras, para aplicar a entropia cruzada a uma tarefa de classificação multiclasse, a perda de cada classe é calculada separadamente e, em seguida, somada para determinar a perda total.
Nesta parte do tutorial, aprenderemos a usar a função de perda de entropia cruzada no TensorFlow e no PyTorch.
Vamos começar criando o conjunto de dados. Usaremos a função make_classification do Scikit Learns para nos ajudar:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# create training data
X, y = make_classification(
n_samples=10000,
n_informative=10,
random_state=2022
)
# split into train and test
X_new, X_test = X[:9000, :], X[9000:, ]
y_new, y_test = y[:9000], y[9000:]
X_train, X_val, y_train, y_val = train_test_split(
X_new, y_new,
test_size=0.3
)
print(f"Train data: {X_train.shape}\n\
Train labels: {y_train.shape}\n\
Test data: {X_test.shape}\n\
Test labels: {y_test.shape}")
"""
Train data: (6300, 20)
Train labels: (6300,)
Test data: (1000, 20)
Test labels: (1000,)
"""O modelo que criaremos consistirá em uma camada de entrada, uma camada oculta e uma camada de saída.
Como essa é uma tarefa de classificação binária, usaremos a entropia cruzada binária como nossa função de perda.
# building and training model
model = tf.keras.Sequential([
tf.keras.layers.Dense(10,
input_shape=(X_train.shape[1],),
activation="relu"),
tf.keras.layers.Dense(10,
activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(
loss="binary_crossentropy", # loss function here
optimizer="adam",
metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=20, validation_data=[X_val, y_val], verbose=0)Em seguida, traçaremos o gráfico da perda para ver se o modelo está melhorando, o que significa que o erro diminui a cada época até que não possa mais melhorar.
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()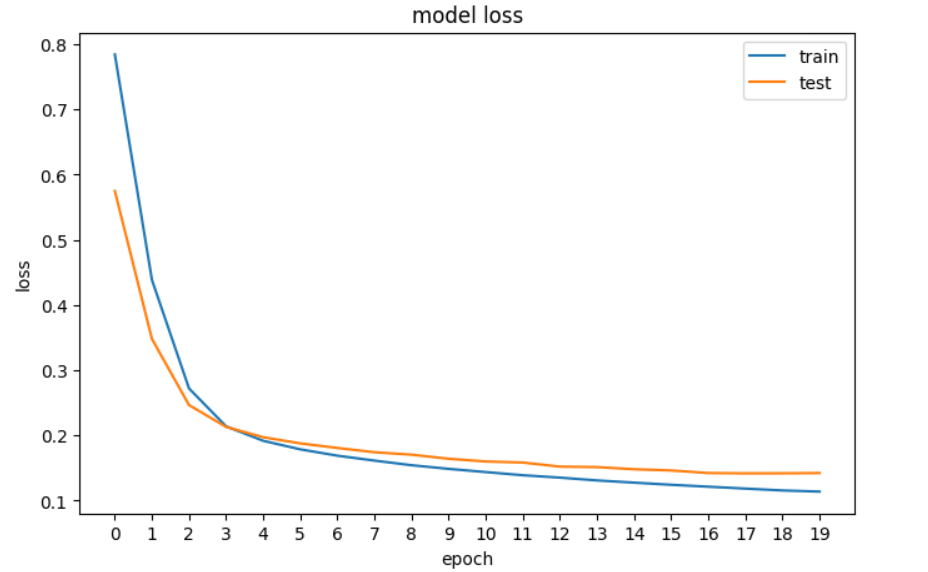
Um gráfico da perda de nossa rede neural no TensorFlow.
No PyTorch, as entradas, saídas e parâmetros do modelo são codificados usando tensores, o que significa que devemos converter nossas matrizes Numpy em tensores. Essa é a primeira coisa que fazemos no código abaixo e, em seguida, criamos a rede neural e imprimimos suas dimensões.
# convert numpy arrays to tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_val_tensor = torch.tensor(X_val, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
y_val_tensor = torch.tensor(y_val, dtype=torch.float32).reshape(-1, 1)
# build the model
input_dim = X_train.shape[1]
hidden_dim = 10
output_dim = 1
model = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)
print(model)
"""
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=10, bias=True)
(3): ReLU()
(4): Linear(in_features=10, out_features=1, bias=True)
(5): Sigmoid()
)
"""Em seguida, definimos a função de perda de entropia cruzada binária e o otimizador:
loss_fn = nn.BCELoss() # binary cross entropy
optimizer = optim.Adam(model.parameters(), lr=0.001)E agora você vai planejar a perda:
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()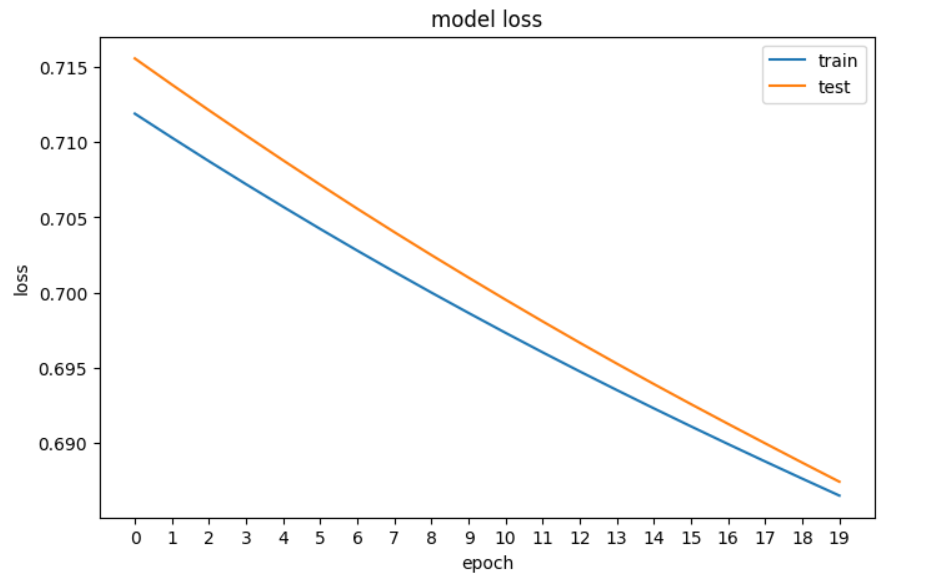
Um gráfico da perda de nossa rede neural no PyTorch
Aqui está uma rápida recapitulação do que aprendemos sobre a perda de entropia cruzada:
Para continuar seu aprendizado, confira nossos recursos:
Comece sua jornada de aprendizado de máquina hoje mesmo!
Programa
Programa
Curso
blog
Abid Ali Awan
7 min
Tutorial
Richmond Alake
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal
Tutorial
Avinash Navlani
Tutorial
Bex Tuychiev



