
Program
Makine Öğrenimi Mühendisi
44 sa
Çapraz entropi kavramının kökeni, bilgi kuramına dayanır; burada bilgi entropisi (Shannon entropisi olarak da bilinir), Claude Shannon tarafından 1948'de “A Mathematical Theory of Communication” başlıklı makalede resmen tanıtılmıştır. Çapraz entropiye geçmeden önce entropiyi ele alalım.
Entropi, bir sistemdeki rastgelelik ya da düzensizlik derecesini hesaplar. Bilgi kuramı bağlamında, bir rastgele değişkenin entropisi, olası sonuçlara özgü ortalama belirsizlik, şaşkınlık ya da bilgidir. Basitçe söylemek gerekirse, bir olayın belirsizliğini ölçer.
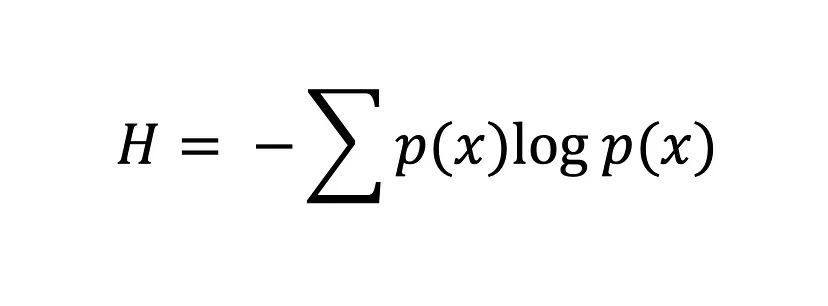
Shannon entropisi denklemi
Entropi değeri H(x) ne kadar büyükse, olasılık dağılımındaki belirsizlik o kadar fazladır; değer ne kadar küçükse belirsizlik o kadar azdır.
Çapraz entropi, logaritmik kayıp veya log kaybı olarak da bilinir ve bir sınıflandırma modelinin performansını ölçmek için makine öğreniminde kullanılan popüler bir kayıp fonksiyonudur.
Bir olasılık dağılımından, p, bir olayı tanımlamak için, başka bir olasılık dağılımı q için optimal kod kullanıldığında gereken ortalama bit sayısını ölçer. Başka bir deyişle, çapraz entropi bir sınıflandırma modelinin keşfedilen olasılık dağılımı ile tahmin edilen değerler arasındaki farkı ölçer.
Çapraz entropi kayıp fonksiyonu, eğitim sırasında bir makine öğrenimi modelinin ağırlıklarını ayarlayarak en iyi çözümü bulmak için kullanılır. Amaç, gerçek ve tahmin edilen sonuçlar arasındaki hatayı en aza indirmektir. Daha düşük bir çapraz entropi değeri daha iyi performansı işaret eder. Bu optimizasyon, kayıp fonksiyonunun gradyanlarının parametre güncellemelerini yönlendirdiği gradyan inişi yoluyla gerçekleşir.
Kullback-Leibler (KL) Ayrışımına aşinaysanız, “Çapraz entropi ile KL ayrışımı arasındaki fark nedir?” diye merak edebilirsiniz. Bu haklı bir sorudur. Her iki kavram da olasılık dağılımlarının farklarını veya benzerliklerini ölçmek için yaygın olarak kullanılır. Bazı benzerlikler taşımalarına rağmen farklı amaçlara hizmet ederler.
Yukarıda belirtildiği gibi, çapraz entropi, P olasılık dağılımından bir olayı tanımlamak için Q olasılık dağılımı için optimal kod kullanıldığında gereken ortalama bit sayısını ölçer ve genellikle, tahmin edilen olasılık dağılımı ile gerçek dağılım arasındaki hatayı en aza indirmeyi amaçlayan modellerin performansını değerlendirmek için makine öğreniminde kullanılır.
Buna karşılık, KL ayrışımı P ve Q olmak üzere iki olasılık dağılımı arasındaki farkı ölçer. Yani, KL ayrışımı, Q'nun P'yi yaklaştırmak için kullanılması halinde ortaya çıkan bilgi kaybının miktarını niceler. Bu, amacın gerçek ve öğrenilmiş veri dağılımları arasındaki ayrışmayı en aza indirerek verideki yapıyı ortaya çıkarmak olduğu gözetimsiz öğrenme görevlerinde son derece kullanışlıdır.
Makine öğreniminde kayıp fonksiyonları, modellerin ne kadar yanıldığını anlamasına ve bu yanılgıya göre kendini geliştirmesine yardımcı olur. Bunlar, bir makine öğrenimi modelinde tahmin edilen değerlerle gerçek değerler arasındaki farkı nicelendiren matematiksel fonksiyonlardır; ancak yaptıkları sadece bu değildir.
Bir kayıp fonksiyonundan elde edilen hata ölçüsü, optimizasyon sürecinde modele, veriye ne kadar iyi uyduğuna dair geri bildirim sağlayarak yol gösterir. Bu nedenle, çoğu makine öğrenimi modeli, optimizasyon aşamasında bir kayıp fonksiyonu uygular; burada model parametreleri, hatayı en aza indirmeye ve en iyi çözüme ulaşmaya yardımcı olacak şekilde seçilir – hata ne kadar küçükse model o kadar iyidir.
İki olasılık dağılımı arasındaki hatayı çapraz entropi kayıp fonksiyonunu kullanarak ölçebiliriz. Örneğin, ikili sınıflandırma görevi yürüttüğümüzü varsayalım (iki sınıflı bir sınıflandırma görevi, 0 ve 1).
Bu durumda, tüm veri örnekleri üzerindeki ortalama çapraz entropi olan ikili çapraz entropiyi kullanmalıyız:

İkili çapraz entropi formülü [Kaynak: Cross-Entropy Loss Function]
Doğru değerin y=1 olduğu tek bir veri noktasının kaybını hesaplayacak olursak, denklemimiz şöyle görünür:
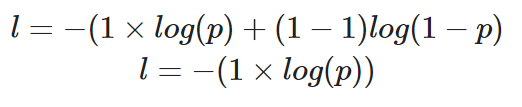
Gerçek değerin 1 olduğu tek bir örnek için ikili çapraz entropinin hesaplanması
Tahmin edilen olasılık p, kaybın l değerini belirler. p değeri yüksekse, model doğru bir tahmin yaptığı için ödüllendirilir — bu da düşük bir l kaybı değeriyle görülür.
Buna karşılık, düşük bir tahmin olasılığı p, modelin yanlış olduğunu ima eder ve ikili çapraz entropi kayıp fonksiyonu bunu l değerini yükselterek yansıtır.
Çok sınıflı bir sınıflandırma görevi için, çapraz entropi (sıklıkla kategorik çapraz entropi olarak anılır) aşağıdaki şekilde genişletilebilir. Bu durumda, çıktı katmanı tipik olarak tüm sınıflar arasında bir olasılık dağılımı üretmek için bir softmax aktivasyon fonksiyonu kullanır:
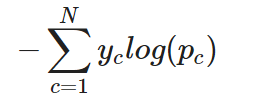
Tek bir örnek için kategorik çapraz entropi
Başka bir deyişle, çapraz entropiyi çok sınıflı bir sınıflandırma görevine uygulamak için, her sınıfın kaybı ayrı ayrı hesaplanır ve toplam kaybı belirlemek için toplanır.
Çapraz entropi kaybı, sınıflandırma görevleri için standart tercihtir; ancak her varyantın ne zaman kullanılacağını bilmek daha iyi modeller kurmanıza yardımcı olur:
| Kayıp Fonksiyonu | Kullanım Durumu | Çıktı Aktivasyonu | Örnek |
|---|---|---|---|
| İkili Çapraz Entropi | İki sınıf (0 veya 1) | Sigmoid | Spam tespiti, tıbbi teşhis |
| Kategorik Çapraz Entropi | Birbirini dışlayan birden çok sınıf | Softmax | Görüntü sınıflandırma, duygu analizi |
| İkili Çapraz Entropi (çok etiketli) | Örnek başına birden çok etiket | Sigmoid (çıktı başına) | Görüntü etiketleme, doküman sınıflandırma |
Bu eğitimin bu bölümünde, TensorFlow ve PyTorch içinde çapraz entropi kayıp fonksiyonunun nasıl kullanılacağını öğreneceğiz.
Veri kümesini oluşturarak başlayalım. Bize yardımcı olması için Scikit-learn'ün make_classification fonksiyonunu kullanacağız:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training data
X, y = make_classification(
n_samples=10000,
n_informative=10,
random_state=2022
)
# split into train and test
X_new, X_test = X[:9000, :], X[9000:, ]
y_new, y_test = y[:9000], y[9000:]
X_train, X_val, y_train, y_val = train_test_split(
X_new, y_new,
test_size=0.3
)
print(f"Train data: {X_train.shape}\n\
Train labels: {y_train.shape}\n\
Test data: {X_test.shape}\n\
Test labels: {y_test.shape}")
"""
Train data: (6300, 20)
Train labels: (6300,)
Test data: (1000, 20)
Test labels: (1000,)
"""Kuracağımız model bir giriş katmanı, bir gizli katman ve bir çıktı katmanından oluşacak.
Bu bir ikili sınıflandırma görevi olduğundan, kayıp fonksiyonu olarak ikili çapraz entropiyi kullanacağız. Çıktı katmanı, 0 ile 1 arasında olasılıklar üretmek için bir sigmoid aktivasyon fonksiyonu kullanır.
import tensorflow as tf
# Build and train model
model = tf.keras.Sequential([
tf.keras.layers.Dense(10,
input_shape=(X_train.shape[1],),
activation="relu"),
tf.keras.layers.Dense(10,
activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(
loss="binary_crossentropy", # loss function here
optimizer="adam",
metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=20, validation_data=[X_val, y_val], verbose=0)Sonraki adımda, model iyileşiyor mu görmek için kaybı görselleştireceğiz – yani hata, model artık daha fazla iyileşemeyene kadar her epoch'ta azalır.
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()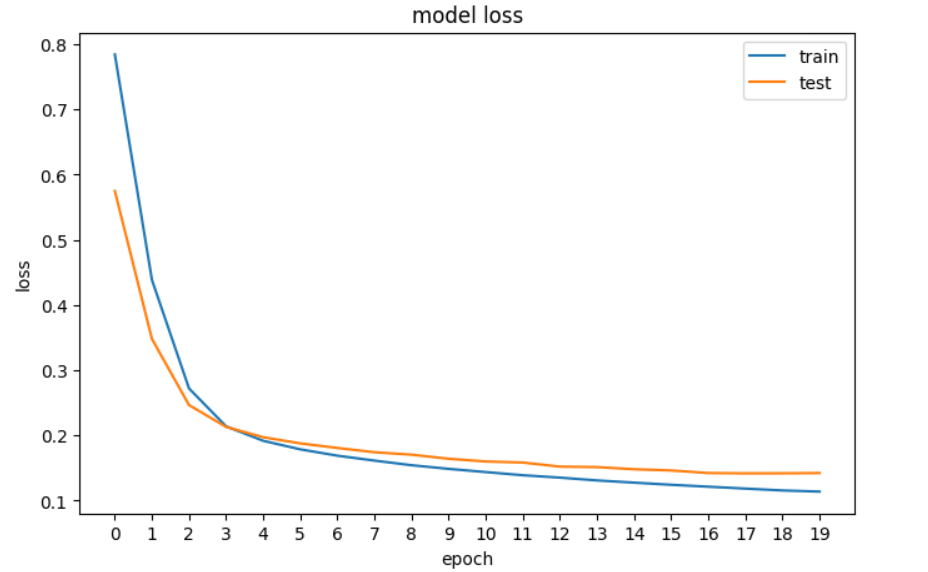
TensorFlow'daki sinir ağımızın kaybının grafiği.
PyTorch'ta modelin girdileri, çıktıları ve parametreleri tensörler kullanılarak kodlanır; bu da Numpy dizilerini tensörlere dönüştürmemiz gerektiği anlamına gelir. Aşağıdaki kodda ilk yaptığımız şey bu; ardından sinir ağını kuruyor ve boyutlarını yazdırıyoruz.
import torch
import torch.nn as nn
import torch.optim as optim
# Convert numpy arrays to tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_val_tensor = torch.tensor(X_val, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
y_val_tensor = torch.tensor(y_val, dtype=torch.float32).reshape(-1, 1)
# Build the model
input_dim = X_train.shape[1]
hidden_dim = 10
output_dim = 1
model = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)
print(model)
"""
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=10, bias=True)
(3): ReLU()
(4): Linear(in_features=10, out_features=1, bias=True)
(5): Sigmoid()
)
"""Sonraki adımda, ikili çapraz entropi kayıp fonksiyonunu ve optimize ediciyi tanımlıyoruz:
loss_fn = nn.BCELoss() # binary cross entropy
optimizer = optim.Adam(model.parameters(), lr=0.001)Şimdi modeli eğitmemiz gerekiyor. İşte eğitim döngüsü:
# Training loop
n_epochs = 20
train_loss = []
val_loss = []
for epoch in range(n_epochs):
# Training
model.train()
y_pred = model(X_train_tensor)
loss = loss_fn(y_pred, y_train_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# Validation
model.eval()
with torch.no_grad():
y_val_pred = model(X_val_tensor)
v_loss = loss_fn(y_val_pred, y_val_tensor)
val_loss.append(v_loss.item())Ve şimdi kaybı çizdirelim:
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()
PyTorch'taki Sinir ağımızın kaybının grafiği
Çapraz entropi kaybı hakkında öğrendiklerimizi kısaca özetleyelim:
Öğrenmeye devam etmek için kaynaklarımıza göz atın:
Makine Öğrenimi Yolculuğunuza Bugün Başlayın!
Program
Program
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
