
Tracks
Kỹ sư Học máy
44 giờ
Khái niệm cross-entropy bắt nguồn từ lý thuyết thông tin, nơi entropy thông tin, còn gọi là entropy Shannon, được Claude Shannon giới thiệu chính thức năm 1948 trong bài báo “A Mathematical Theory of Communication.” Trước khi bàn về cross-entropy, hãy nói về entropy.
Entropy tính mức độ ngẫu nhiên hay hỗn độn trong một hệ. Trong ngữ cảnh lý thuyết thông tin, entropy của một biến ngẫu nhiên là độ bất định, sự bất ngờ, hay lượng thông tin trung bình vốn có trong các kết quả khả dĩ. Nói đơn giản, nó đo lường mức độ bất định của một sự kiện.
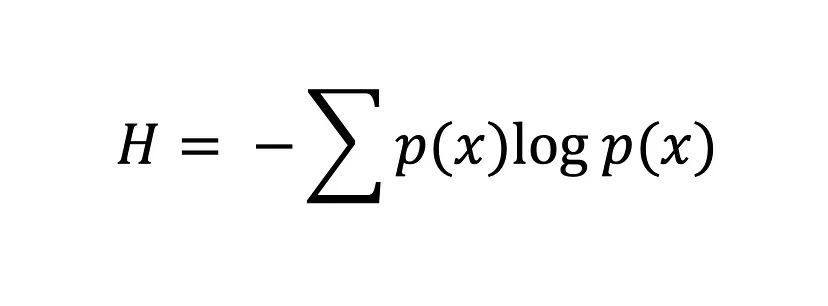
Phương trình entropy Shannon
Giá trị entropy H(x) càng lớn thì bất định của phân phối xác suất càng cao, và giá trị càng nhỏ thì mức bất định càng thấp.
Cross-entropy, còn gọi là logarithmic loss hoặc log loss, là một hàm mất mát phổ biến trong machine learning để đo hiệu năng của mô hình phân loại.
Nó đo số bit trung bình cần thiết để nhận diện một sự kiện từ phân phối xác suất p khi dùng mã tối ưu cho một phân phối xác suất khác q. Nói cách khác, cross-entropy đo sự khác biệt giữa phân phối xác suất mà mô hình phân loại học được và các giá trị dự đoán.
Hàm mất mát cross-entropy được dùng để tìm nghiệm tối ưu bằng cách điều chỉnh trọng số của mô hình trong quá trình huấn luyện. Mục tiêu là tối thiểu hóa sai số giữa kết quả thực và dự đoán. Giá trị cross-entropy thấp hơn cho thấy hiệu năng tốt hơn. Việc tối ưu diễn ra thông qua gradient descent, nơi gradient của hàm mất mát dẫn hướng cập nhật tham số.
Nếu bạn quen với phân kỳ Kullback-Leibler (KL), bạn có thể thắc mắc: “Khác biệt giữa cross-entropy và KL divergence là gì?” Câu hỏi rất xác đáng. Cả hai khái niệm đều được dùng rộng rãi để đo sự khác biệt hay tương đồng giữa các phân phối xác suất. Dù có điểm chung, chúng phục vụ mục đích khác nhau.
Như đã đề cập, cross-entropy đo số bit trung bình cần để nhận diện một sự kiện từ phân phối P khi dùng mã tối ưu cho phân phối Q, và thường được dùng trong machine learning để đánh giá hiệu năng mô hình, nơi mục tiêu là tối thiểu hóa sai số giữa phân phối xác suất dự đoán và phân phối thật.
Ngược lại, KL divergence đo sự khác biệt giữa hai phân phối xác suất P và Q. Cụ thể, KL divergence định lượng lượng thông tin bị mất khi dùng Q để xấp xỉ P. Điều này đặc biệt hữu ích trong các bài toán học không giám sát, nơi mục tiêu là khám phá cấu trúc dữ liệu bằng cách tối thiểu hóa độ lệch giữa phân phối thật và phân phối học được.
Trong machine learning, các hàm mất mát giúp mô hình biết mình sai ở đâu và cải thiện dựa trên mức độ sai đó. Chúng là các hàm toán học định lượng sự khác biệt giữa giá trị dự đoán và giá trị thực trong mô hình machine learning, nhưng không chỉ dừng ở đó.
Độ lỗi đo được từ hàm mất mát cũng đóng vai trò định hướng trong quá trình tối ưu hóa bằng cách phản hồi cho mô hình về mức độ phù hợp với dữ liệu. Vì vậy, hầu hết mô hình machine learning đều triển khai một hàm mất mát trong giai đoạn tối ưu, nơi các tham số được chọn để giúp mô hình giảm thiểu lỗi và đạt nghiệm tối ưu – lỗi càng nhỏ, mô hình càng tốt.
Chúng ta có thể đo lỗi giữa hai phân phối xác suất bằng hàm mất mát cross-entropy. Ví dụ, giả sử ta đang thực hiện một bài toán phân loại nhị phân (phân loại với hai lớp, 0 và 1).
Trong trường hợp này, ta cần dùng binary cross-entropy, tức trung bình cross-entropy trên tất cả các mẫu dữ liệu:

Công thức binary cross entropy [Nguồn: Cross-Entropy Loss Function]
Nếu tính mất mát cho một điểm dữ liệu đơn lẻ với giá trị đúng là y=1, phương trình sẽ như sau:
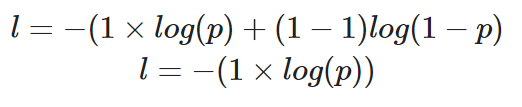
Tính binary cross-entropy cho một trường hợp có giá trị thật bằng 1
Xác suất dự đoán p quyết định giá trị mất mát l. Nếu p cao, mô hình sẽ được thưởng vì dự đoán đúng — thể hiện bằng giá trị mất mát l thấp.
Ngược lại, xác suất dự đoán p thấp ngụ ý mô hình dự đoán sai, và hàm mất mát binary cross-entropy sẽ phản ánh điều này bằng cách làm giá trị l cao hơn.
Với bài toán phân loại đa lớp, cross-entropy (thường gọi là categorical cross-entropy) có thể được mở rộng như sau. Khi đó, tầng đầu ra thường dùng hàm kích hoạt softmax để tạo phân phối xác suất trên tất cả các lớp:
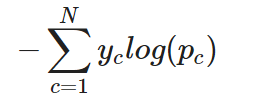
Categorical cross-entropy cho một trường hợp đơn lẻ
Nói cách khác, để áp dụng cross-entropy cho phân loại đa lớp, mất mát cho từng lớp được tính riêng rồi cộng lại để ra tổng mất mát.
Cross-entropy là lựa chọn tiêu chuẩn cho các bài toán phân loại, nhưng hiểu rõ khi nào dùng từng biến thể sẽ giúp bạn xây dựng mô hình tốt hơn:
| Hàm mất mát | Trường hợp sử dụng | Kích hoạt đầu ra | Ví dụ |
|---|---|---|---|
| Binary Cross-Entropy | Hai lớp (0 hoặc 1) | Sigmoid | Phát hiện spam, chẩn đoán y khoa |
| Categorical Cross-Entropy | Nhiều lớp loại trừ lẫn nhau | Softmax | Phân loại ảnh, phân tích cảm xúc |
| Binary Cross-Entropy (đa nhãn) | Nhiều nhãn cho mỗi mẫu | Sigmoid (mỗi đầu ra) | Gắn thẻ ảnh, phân loại tài liệu |
Trong phần này, chúng ta sẽ học cách dùng hàm mất mát cross-entropy trong TensorFlow và PyTorch.
Bắt đầu bằng việc tạo dữ liệu. Chúng ta sẽ dùng hàm make_classification của Scikit-learn để hỗ trợ:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training data
X, y = make_classification(
n_samples=10000,
n_informative=10,
random_state=2022
)
# split into train and test
X_new, X_test = X[:9000, :], X[9000:, ]
y_new, y_test = y[:9000], y[9000:]
X_train, X_val, y_train, y_val = train_test_split(
X_new, y_new,
test_size=0.3
)
print(f"Train data: {X_train.shape}\n\
Train labels: {y_train.shape}\n\
Test data: {X_test.shape}\n\
Test labels: {y_test.shape}")
"""
Train data: (6300, 20)
Train labels: (6300,)
Test data: (1000, 20)
Test labels: (1000,)
"""Mô hình chúng ta xây dựng sẽ gồm tầng vào, tầng ẩn và tầng ra.
Vì đây là bài toán phân loại nhị phân, ta sẽ dùng binary cross-entropy làm hàm mất mát. Tầng đầu ra dùng hàm kích hoạt sigmoid để sinh xác suất trong khoảng 0 đến 1.
import tensorflow as tf
# Build and train model
model = tf.keras.Sequential([
tf.keras.layers.Dense(10,
input_shape=(X_train.shape[1],),
activation="relu"),
tf.keras.layers.Dense(10,
activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(
loss="binary_crossentropy", # loss function here
optimizer="adam",
metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=20, validation_data=[X_val, y_val], verbose=0)Tiếp theo, ta sẽ vẽ đồ thị mất mát để xem mô hình có cải thiện hay không – tức là lỗi giảm dần theo từng epoch cho đến khi không thể cải thiện thêm.
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()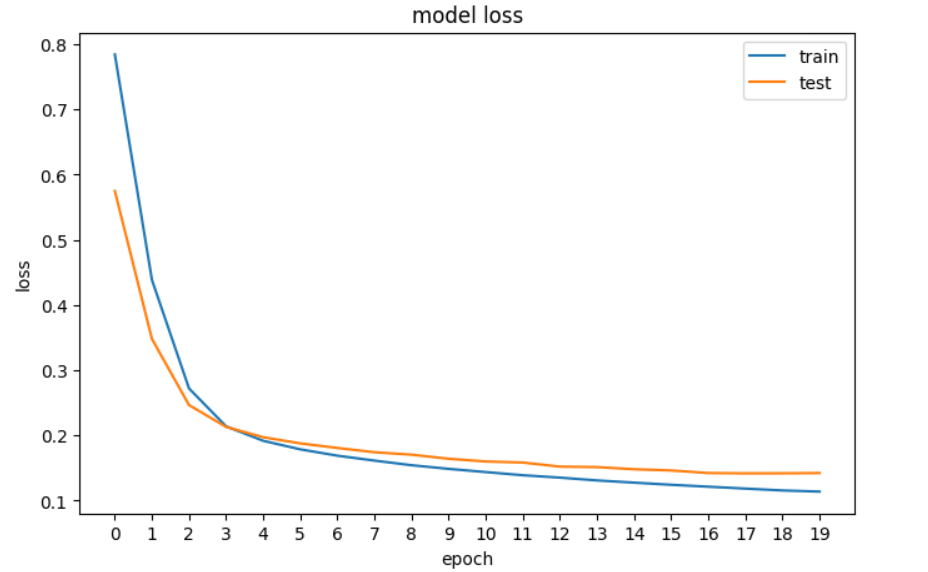
Đồ thị mất mát của mạng nơ-ron trong TensorFlow.
Trong PyTorch, đầu vào, đầu ra và tham số mô hình được mã hóa bằng tensor, nghĩa là ta cần chuyển mảng Numpy sang tensor. Đó là việc đầu tiên trong đoạn mã dưới đây, sau đó ta xây dựng mạng nơ-ron và in kích thước các tầng.
import torch
import torch.nn as nn
import torch.optim as optim
# Convert numpy arrays to tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_val_tensor = torch.tensor(X_val, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
y_val_tensor = torch.tensor(y_val, dtype=torch.float32).reshape(-1, 1)
# Build the model
input_dim = X_train.shape[1]
hidden_dim = 10
output_dim = 1
model = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)
print(model)
"""
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=10, bias=True)
(3): ReLU()
(4): Linear(in_features=10, out_features=1, bias=True)
(5): Sigmoid()
)
"""Tiếp theo, ta định nghĩa hàm mất mát binary cross-entropy và bộ tối ưu:
loss_fn = nn.BCELoss() # binary cross entropy
optimizer = optim.Adam(model.parameters(), lr=0.001)Giờ chúng ta cần huấn luyện mô hình. Đây là vòng lặp huấn luyện:
# Training loop
n_epochs = 20
train_loss = []
val_loss = []
for epoch in range(n_epochs):
# Training
model.train()
y_pred = model(X_train_tensor)
loss = loss_fn(y_pred, y_train_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# Validation
model.eval()
with torch.no_grad():
y_val_pred = model(X_val_tensor)
v_loss = loss_fn(y_val_pred, y_val_tensor)
val_loss.append(v_loss.item())Và bây giờ vẽ đồ thị mất mát:
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()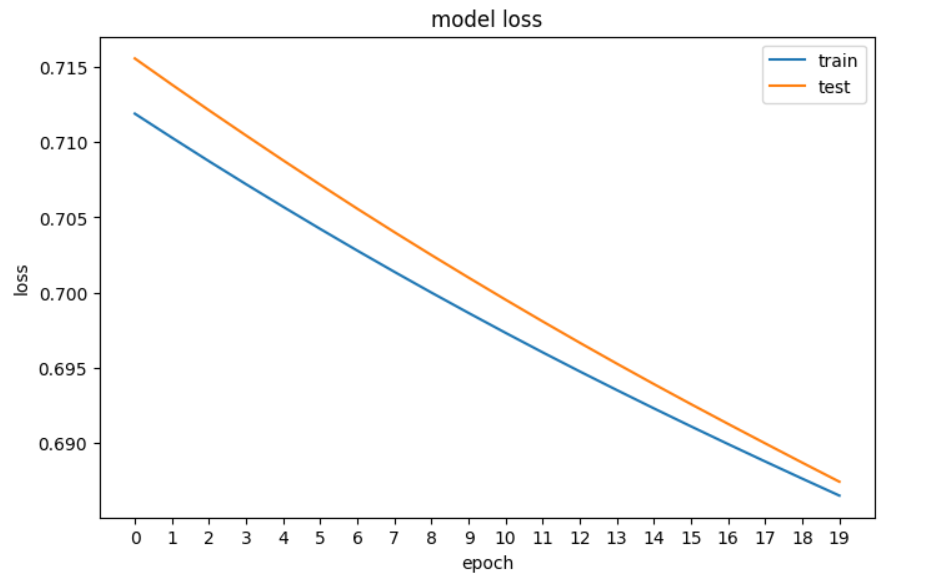
Đồ thị mất mát của mạng nơ-ron trong PyTorch
Tóm lược nhanh những gì chúng ta đã học về mất mát cross-entropy:
Để tiếp tục học, hãy xem thêm các tài nguyên của chúng tôi:
Bắt đầu hành trình Machine Learning của bạn ngay hôm nay!
Tracks
Tracks
Courses
blogs
Matt Crabtree
10 phút