
Programma
Ingegnere dell'apprendimento automatico
44 h
Il concetto di entropia incrociata affonda le sue radici nella teoria dell’informazione, dove l’entropia dell’informazione, nota anche come entropia di Shannon, è stata introdotta formalmente nel 1948 da Claude Shannon in un articolo intitolato “A Mathematical Theory of Communication.” Prima di affrontare l’entropia incrociata, vediamo l’entropia.
L’entropia calcola il grado di casualità o disordine all’interno di un sistema. Nel contesto della teoria dell’informazione, l’entropia di una variabile casuale è l’incertezza media, la sorpresa o l’informazione insita nei possibili esiti. In parole semplici, misura l’incertezza di un evento.
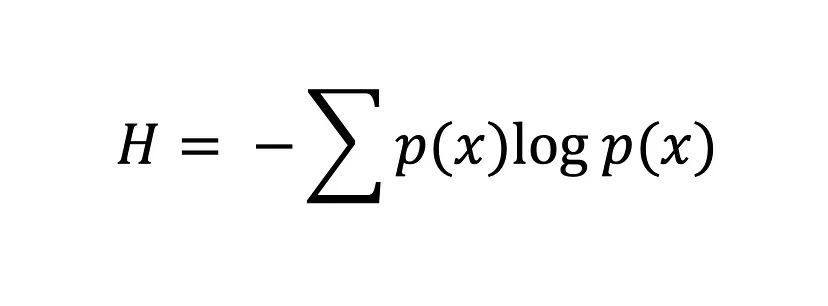
L’equazione dell’entropia di Shannon
Maggiore è il valore dell’entropia, H(x), maggiore è l’incertezza della distribuzione di probabilità; più piccolo è il valore, minore è l’incertezza.
L’entropia incrociata, nota anche come perdita logaritmica o log loss, è una funzione di perdita molto usata nel machine learning per misurare le prestazioni di un modello di classificazione.
Misura il numero medio di bit necessari per identificare un evento da una distribuzione di probabilità, p, usando il codice ottimale per un’altra distribuzione, q. In altre parole, l’entropia incrociata misura la differenza tra la distribuzione di probabilità appresa da un modello di classificazione e i valori previsti.
La funzione di perdita a entropia incrociata viene usata per trovare la soluzione ottimale regolando i pesi di un modello durante l’addestramento. L’obiettivo è minimizzare l’errore tra gli esiti reali e quelli previsti. Un valore più basso di entropia incrociata indica prestazioni migliori. Questa ottimizzazione avviene tramite la discesa del gradiente, in cui i gradienti della funzione di perdita guidano l’aggiornamento dei parametri.
Se conosci la divergenza di Kullback-Leibler (KL), potresti chiederti: “Qual è la differenza tra entropia incrociata e divergenza KL?” È una domanda legittima. Entrambi i concetti sono ampiamente usati per misurare le differenze o somiglianze tra distribuzioni di probabilità. Sebbene condividano alcune somiglianze, servono a scopi diversi.
Come accennato, l’entropia incrociata misura il numero medio di bit necessari per identificare un evento da una distribuzione P usando il codice ottimale per una distribuzione Q, ed è tipicamente usata nel machine learning per valutare le prestazioni di un modello quando l’obiettivo è minimizzare l’errore tra la distribuzione di probabilità prevista e quella reale.
Al contrario, la divergenza KL misura la differenza tra due distribuzioni di probabilità, P e Q. In particolare, quantifica la quantità di informazione persa quando Q viene usata per approssimare P. Questo è estremamente utile nei compiti di apprendimento non supervisionato, in cui l’obiettivo è scoprire la struttura nei dati minimizzando la divergenza tra le distribuzioni reali e quelle apprese.
Nel machine learning, le funzioni di perdita aiutano i modelli a capire quanto stanno sbagliando e a migliorarsi sulla base di questo errore. Sono funzioni matematiche che quantificano la differenza tra valori previsti e valori reali in un modello, ma non si limitano a questo.
La misura dell’errore di una funzione di perdita funge anche da guida durante il processo di ottimizzazione, fornendo al modello un feedback su quanto bene si adatta ai dati. Di conseguenza, la maggior parte dei modelli implementa una funzione di perdita nella fase di ottimizzazione, in cui i parametri vengono scelti per aiutare il modello a minimizzare l’errore e raggiungere una soluzione ottimale – minore è l’errore, migliore è il modello.
Possiamo misurare l’errore tra due distribuzioni di probabilità usando la funzione di perdita a entropia incrociata. Per esempio, supponiamo di svolgere un compito di classificazione binaria (una classificazione con due classi, 0 e 1).
In questo caso, dobbiamo usare la binary cross-entropy, che è l’entropia incrociata media su tutti i campioni di dati:

Formula della binary cross-entropy [Fonte: Cross-Entropy Loss Function]
Se volessimo calcolare la perdita di un singolo punto dati in cui il valore corretto è y=1, ecco come apparirebbe la nostra equazione:
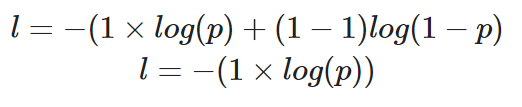
Calcolo della binary cross-entropy per una singola istanza in cui il valore reale è 1
La probabilità prevista, p, determina il valore della perdita, l. Se il valore di p è alto, il modello viene premiato per la previsione corretta – questo si riflette in un valore di perdita, l, basso.
Al contrario, una probabilità prevista, p, bassa implica che il modello ha sbagliato, e la funzione di perdita binary cross-entropy lo rifletterà con un valore di l più alto.
Per un compito di classificazione multi-classe, l’entropia incrociata (o categorical cross-entropy, come spesso viene chiamata) può essere estesa come segue. In questo caso, lo strato di output usa tipicamente una funzione di attivazione softmax per produrre una distribuzione di probabilità su tutte le classi:
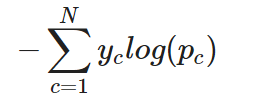
Entropia incrociata categorica per una singola istanza
In altre parole, per applicare l’entropia incrociata a un compito di classificazione multi-classe, la perdita per ciascuna classe viene calcolata separatamente e poi sommata per determinare la perdita totale.
La perdita a entropia incrociata è la scelta standard per i compiti di classificazione, ma capire quando usare ogni variante ti aiuta a costruire modelli migliori:
| Funzione di perdita | Caso d’uso | Attivazione in uscita | Esempio |
|---|---|---|---|
| Binary Cross-Entropy | Due classi (0 o 1) | Sigmoid | Rilevamento spam, diagnosi medica |
| Categorical Cross-Entropy | Classi multiple e mutuamente esclusive | Softmax | Classificazione di immagini, analisi del sentiment |
| Binary Cross-Entropy (multi-label) | Più etichette per campione | Sigmoid (per output) | Tagging di immagini, categorizzazione di documenti |
In questa parte del tutorial, vedremo come usare la funzione di perdita a entropia incrociata in TensorFlow e PyTorch.
Iniziamo creando il dataset. Useremo la funzione make_classification di Scikit-learn per aiutarci:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training data
X, y = make_classification(
n_samples=10000,
n_informative=10,
random_state=2022
)
# split into train and test
X_new, X_test = X[:9000, :], X[9000:, ]
y_new, y_test = y[:9000], y[9000:]
X_train, X_val, y_train, y_val = train_test_split(
X_new, y_new,
test_size=0.3
)
print(f"Train data: {X_train.shape}\n\
Train labels: {y_train.shape}\n\
Test data: {X_test.shape}\n\
Test labels: {y_test.shape}")
"""
Train data: (6300, 20)
Train labels: (6300,)
Test data: (1000, 20)
Test labels: (1000,)
"""Il modello che costruiremo sarà composto da un livello di input, uno nascosto e uno di output.
Poiché si tratta di una classificazione binaria, useremo la binary cross-entropy come funzione di perdita. Il livello di output usa una funzione di attivazione sigmoid per produrre probabilità tra 0 e 1.
import tensorflow as tf
# Build and train model
model = tf.keras.Sequential([
tf.keras.layers.Dense(10,
input_shape=(X_train.shape[1],),
activation="relu"),
tf.keras.layers.Dense(10,
activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(
loss="binary_crossentropy", # loss function here
optimizer="adam",
metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=20, validation_data=[X_val, y_val], verbose=0)Successivamente, tracceremo la perdita per vedere se il modello sta migliorando – cioè se l’errore diminuisce a ogni epoca finché non può più migliorare.
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()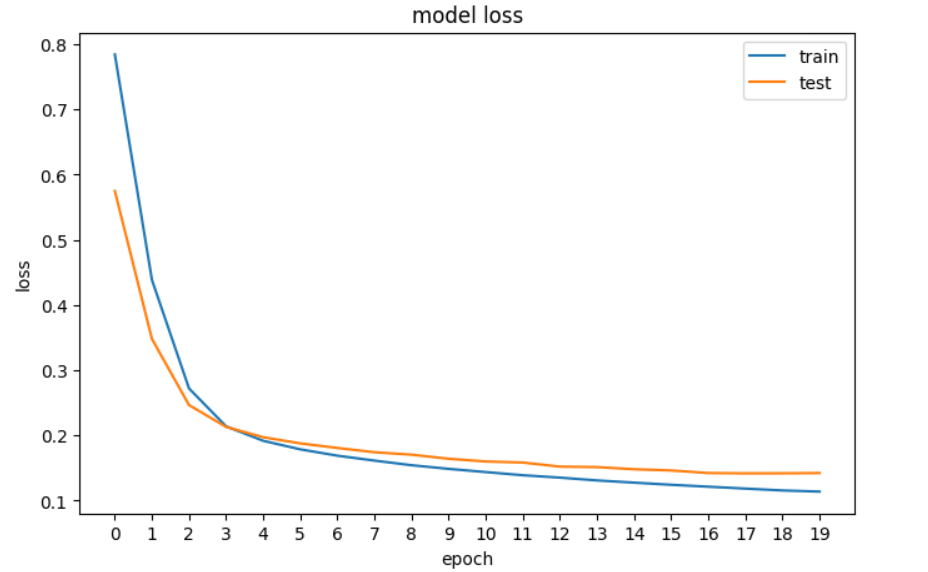
Grafico della perdita della nostra rete neurale in TensorFlow.
In PyTorch, input, output e parametri del modello sono codificati tramite tensori, quindi dobbiamo convertire i nostri array Numpy in tensori. È la prima operazione nel codice qui sotto; poi costruiamo la rete neurale e ne stampiamo le dimensioni.
import torch
import torch.nn as nn
import torch.optim as optim
# Convert numpy arrays to tensors
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_val_tensor = torch.tensor(X_val, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
y_val_tensor = torch.tensor(y_val, dtype=torch.float32).reshape(-1, 1)
# Build the model
input_dim = X_train.shape[1]
hidden_dim = 10
output_dim = 1
model = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)
print(model)
"""
Sequential(
(0): Linear(in_features=20, out_features=10, bias=True)
(1): ReLU()
(2): Linear(in_features=10, out_features=10, bias=True)
(3): ReLU()
(4): Linear(in_features=10, out_features=1, bias=True)
(5): Sigmoid()
)
"""Poi definiamo la funzione di perdita binary cross-entropy e l’ottimizzatore:
loss_fn = nn.BCELoss() # binary cross entropy
optimizer = optim.Adam(model.parameters(), lr=0.001)Ora dobbiamo addestrare il modello. Ecco il ciclo di training:
# Training loop
n_epochs = 20
train_loss = []
val_loss = []
for epoch in range(n_epochs):
# Training
model.train()
y_pred = model(X_train_tensor)
loss = loss_fn(y_pred, y_train_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# Validation
model.eval()
with torch.no_grad():
y_val_pred = model(X_val_tensor)
v_loss = loss_fn(y_val_pred, y_val_tensor)
val_loss.append(v_loss.item())E ora il grafico della perdita:
# plotting the loss of the models
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.xticks(np.arange(0,20, step=1))
plt.legend(['train', 'test'], loc='upper right')
plt.show()
Grafico della perdita della nostra rete neurale in PyTorch
Ecco un rapido riepilogo di ciò che abbiamo imparato sulla perdita a entropia incrociata:
Per continuare a imparare, dai un’occhiata alle nostre risorse:
Inizia oggi il tuo percorso nel machine learning!
Programma
Programma
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

