
Kursus
Merancang Sistem Agentic dengan LangChain
3 Hr
13K
GLM 4.7 Flash dengan cepat menjadi pilihan populer untuk pengodean agen lokal. Banyak pengembang menggunakannya dengan alat seperti llama.cpp dan LM Studio. Namun, banyak orang masih mengalami masalah saat penyiapan, membuat model berjalan dengan benar, dan memastikan pemanggilan alat berfungsi sebagaimana mestinya.
Tutorial ini berfokus pada cara paling sederhana dan andal untuk menjalankan GLM 4.7 Flash secara lokal menggunakan Claude Code dengan Ollama. Tujuannya adalah menghilangkan hambatan dan membantu Anda mendapatkan penyiapan yang berfungsi tanpa kompleksitas yang tidak perlu.
Panduan ini berfungsi di semua sistem operasi. Tidak masalah apakah Anda menggunakan Linux, Windows, atau macOS. Pada akhirnya, Anda akan menjalankan GLM 4.7 Flash secara lokal dan terintegrasi dengan benar dengan Claude Code melalui Ollama.
Sebelum memulai, pastikan sistem Anda memenuhi persyaratan perangkat keras dan perangkat lunak minimum di bawah ini.
Perangkat keras:
Jika Anda tidak memiliki GPU, model dapat dijalankan pada CPU, tetapi kinerjanya akan jauh lebih lambat, dan membutuhkan RAM tinggi.
Perangkat lunak:
Jika toolkit CUDA atau driver NVIDIA tidak ada atau tidak kompatibel, Ollama akan beralih ke mode CPU, yang jauh lebih lambat.
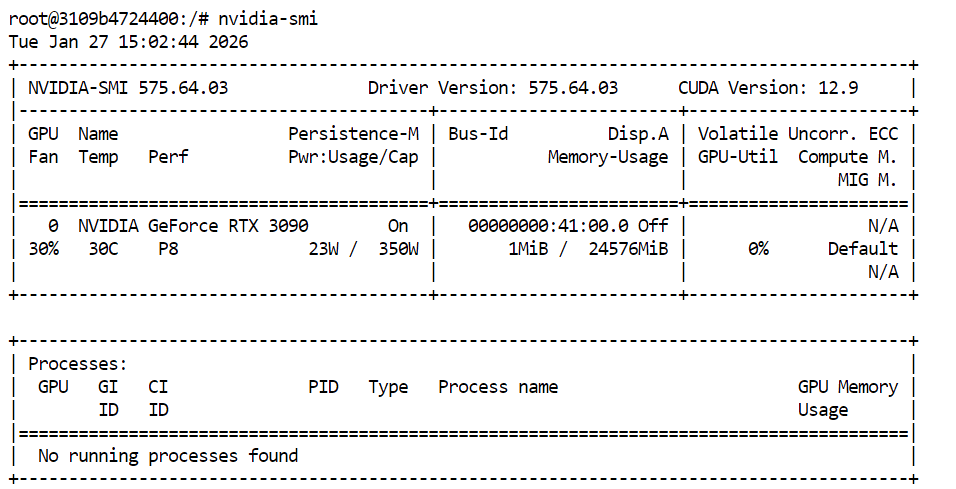
Untuk memverifikasi bahwa GPU dan driver CUDA Anda terinstal dengan benar, jalankan perintah berikut di terminal Anda:
nvidia-smiJika semuanya disiapkan dengan benar, Anda akan melihat GPU Anda terdaftar bersama VRAM yang tersedia dan versi CUDA.
Ollama adalah runtime yang akan kita gunakan untuk menjalankan GLM 4.7 Flash secara lokal dan mengeksposnya agar Claude Code dapat berinteraksi secara andal. Instalasinya sederhana di semua platform yang didukung.
Di Linux, Anda dapat menginstal Ollama dengan satu perintah:
curl -fsSL https://ollama.com/install.sh | shUntuk macOS dan Windows, unduh penginstal langsung dari situs web Ollama dan ikuti instruksi di layar.

Sumber: Ollama
Ollama berjalan sebagai layanan latar belakang dan akan secara otomatis memeriksa pembaruan. Saat pembaruan tersedia, Anda dapat menerapkannya dengan memilih “Restart to update” dari menu Ollama.
Setelah instalasi, buka terminal dan periksa bahwa Ollama terinstal dengan benar:
ollama -vAnda akan melihat keluaran serupa dengan:
ollama version is 0.15.2Jika Anda melihat kesalahan saat menjalankan ollama -v, biasanya berarti layanan Ollama belum berjalan. Mulai server Ollama secara manual:
ollama serveBiarkan ini berjalan, buka jendela terminal baru, lalu jalankan:
ollama -vSetelah perintah versi berhasil, Ollama siap digunakan pada langkah berikutnya dari tutorial.
Setelah Ollama terinstal dan berjalan, langkah berikutnya adalah mengunduh model GLM 4.7 Flash dan memverifikasi bahwa model berfungsi dengan benar. Langkah ini memastikan model berjalan secara lokal sebelum mengintegrasikannya dengan Claude Code.
Sumber: glm-4.7-flash
Mulailah dengan mengunduh model dari registri Ollama:
ollama pull glm-4.7-flashIni akan mengunduh file model dan menyimpannya secara lokal. Bergantung pada kecepatan internet Anda, ini mungkin memerlukan beberapa menit.
Setelah unduhan selesai, jalankan model dalam mode chat interaktif sebagai pemeriksaan cepat:
ollama run glm-4.7-flashKetik prompt sederhana, seperti salam, lalu tekan enter. Dalam beberapa detik, Anda akan menerima respons.
Jika Anda menjalankan di GPU, Anda akan menyadari bahwa respons sangat cepat, dan keluaran mungkin menyertakan token pemikiran internal atau jejak penalaran tergantung pada konfigurasi model.

Anda juga dapat menguji model melalui API HTTP lokal Ollama. Ini berguna untuk memastikan bahwa alat eksternal dapat berkomunikasi dengan model.
Jalankan perintah berikut:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role":"user","content":"Hello!"}]
}'Claude Code dan sebagian besar alat pengodean agen bekerja paling baik dengan jendela konteks besar, sering kali hingga 64k token. Namun, dengan GLM 4.7 Flash, memilih panjang konteks yang tepat penting untuk kinerja dan stabilitas.
Menggunakan ukuran konteks yang sangat besar dapat secara signifikan memperlambat kecepatan generasi. Dalam praktiknya, throughput token dapat turun dari lebih dari 100 token per detik menjadi serendah 2 token per detik. Dalam beberapa kasus, model juga dapat macet dalam loop berpikir panjang jika jendela konteks disetel terlalu tinggi.
Kami menguji beberapa ukuran konteks dan menemukan bahwa konteks 10k tidak memadai untuk alur kerja Claude Code. Konteks 20k memberikan keseimbangan yang baik. Cukup besar untuk tugas pemrograman sambil tetap mempertahankan waktu respons cepat dan mengurangi loop berpikir yang tidak perlu.
Pertama, hentikan server Ollama yang berjalan. Anda dapat melakukannya dengan menekan Ctrl + C di terminal atau dengan menghentikan prosesnya.
Selanjutnya, mulai ulang Ollama dengan panjang konteks kustom dengan menyetel variabel lingkungan sebelum meluncurkan server:
OLLAMA_CONTEXT_LENGTH=20000 ollama serveIni memberi tahu Ollama untuk memuat model dengan jendela konteks maksimum 20.000 token.
Di jendela terminal baru, jalankan:
ollama psIni mengonfirmasi bahwa GLM 4.7 Flash berjalan di GPU dan panjang konteks telah diatur dengan benar. Pada titik ini, model dikonfigurasi untuk penggunaan yang stabil dan cepat dengan Claude Code.
NAME ID SIZE PROCESSOR CONTEXT UNTIL
glm-4.7-flash:latest d1a8a26252f1 21 GB 100% GPU 20000 About a minute from now Claude Code adalah agen pengodean berbasis terminal dari Anthropic yang membantu Anda menulis, mengedit, merapikan, dan memahami kode menggunakan bahasa alami. Ini dibuat untuk alur kerja agen dan dapat menangani tugas pengodean multi-langkah langsung dari baris perintah Anda.
Jika digabungkan dengan Ollama, Claude Code dapat dengan mudah digunakan dengan model lokal seperti GLM 4.7 Flash, memungkinkan Anda menjalankan semuanya secara lokal dan menjaga kode tetap berada di mesin Anda.
Di macOS, Linux, atau Windows menggunakan WSL, instal Claude Code menggunakan skrip penginstal resmi:
curl -fsSL https://claude.ai/install.sh | bashPerintah ini mengunduh dan memasang Claude Code beserta dependensi yang diperlukan. Setelah instalasi selesai, perintah claude akan tersedia di terminal Anda.
Sekarang setelah Ollama dan Claude Code terinstal, langkah selanjutnya adalah menghubungkan Claude Code ke server Ollama lokal Anda dan mengonfigurasinya untuk menggunakan model GLM 4.7 Flash.
Mulailah dengan membuat direktori kerja untuk proyek Anda. Di sinilah Claude Code akan beroperasi dan mengelola file:
mkdir <project-name>
cd <project-name>Ollama kini menyediakan cara bawaan untuk meluncurkan Claude Code yang secara otomatis mengonfigurasinya agar berbicara dengan runtime Ollama lokal. Ini adalah pendekatan yang direkomendasikan dan paling andal.
Untuk meluncurkan Claude Code secara interaktif menggunakan Ollama:
ollama launch claudeUntuk langsung memulai Claude Code menggunakan model GLM 4.7 Flash, jalankan:
ollama launch claude --model glm-4.7-flashIni memastikan Claude Code menggunakan model GLM 4.7 Flash lokal Anda alih-alih model jarak jauh atau default.
Setelah semuanya disiapkan, Anda akan melihat antarmuka Claude Code langsung di terminal Anda.
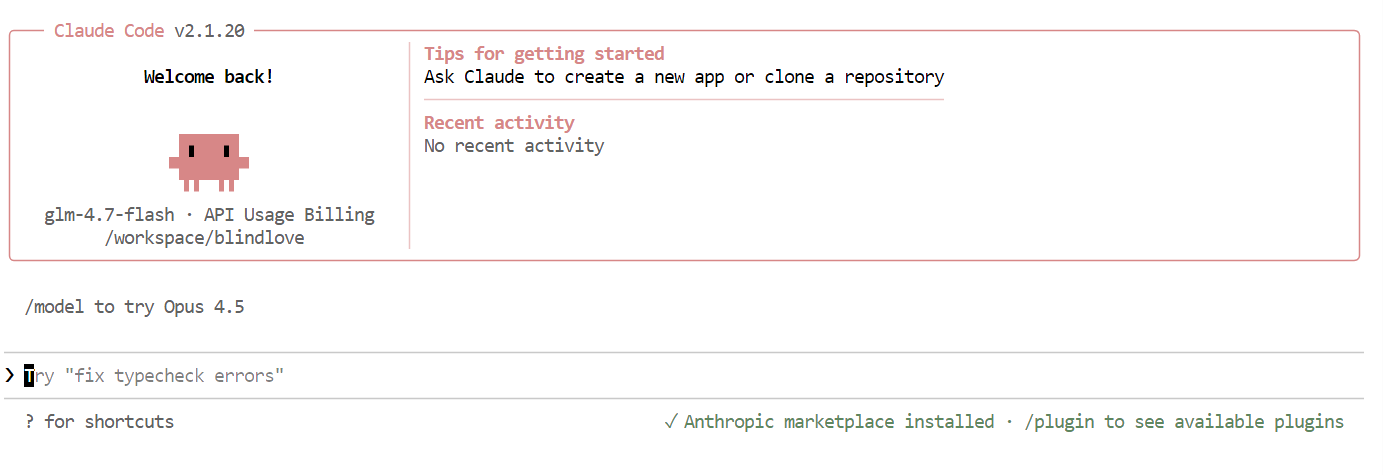
Di dalam Claude Code, gunakan perintah berikut untuk memastikan bahwa ia menggunakan model lokal Anda:
/modelJika keluarannya menampilkan glm-4.7-flash, penyiapan Anda selesai, dan Claude Code berhasil berjalan pada model Ollama lokal Anda.
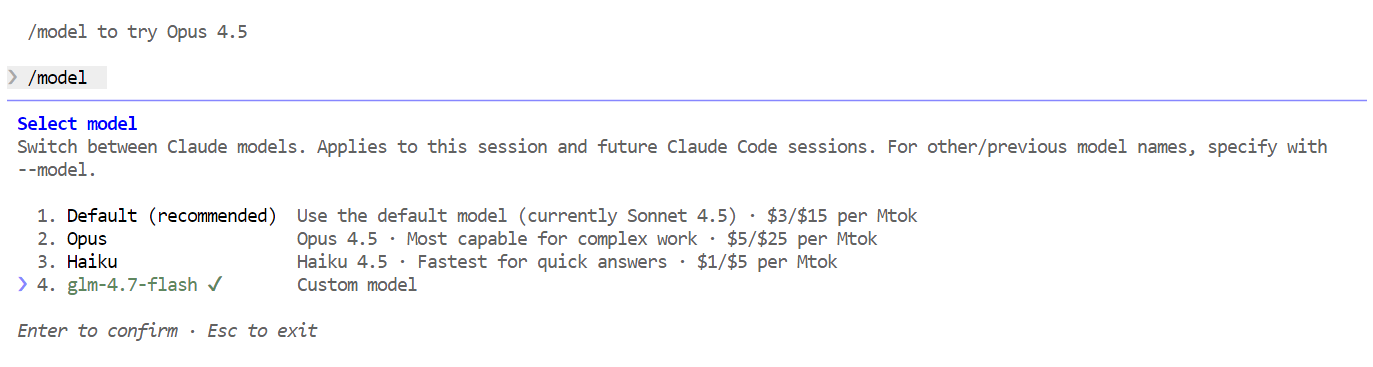
Dengan semuanya siap, Anda sekarang dapat mulai menggunakan Claude Code yang didukung oleh model GLM 4.7 Flash lokal Anda. Hal pertama yang bisa dicoba adalah salam sederhana. Dalam satu atau dua detik, Anda akan menerima respons. Kecepatan terasa sangat cepat, terutama saat berjalan di GPU.
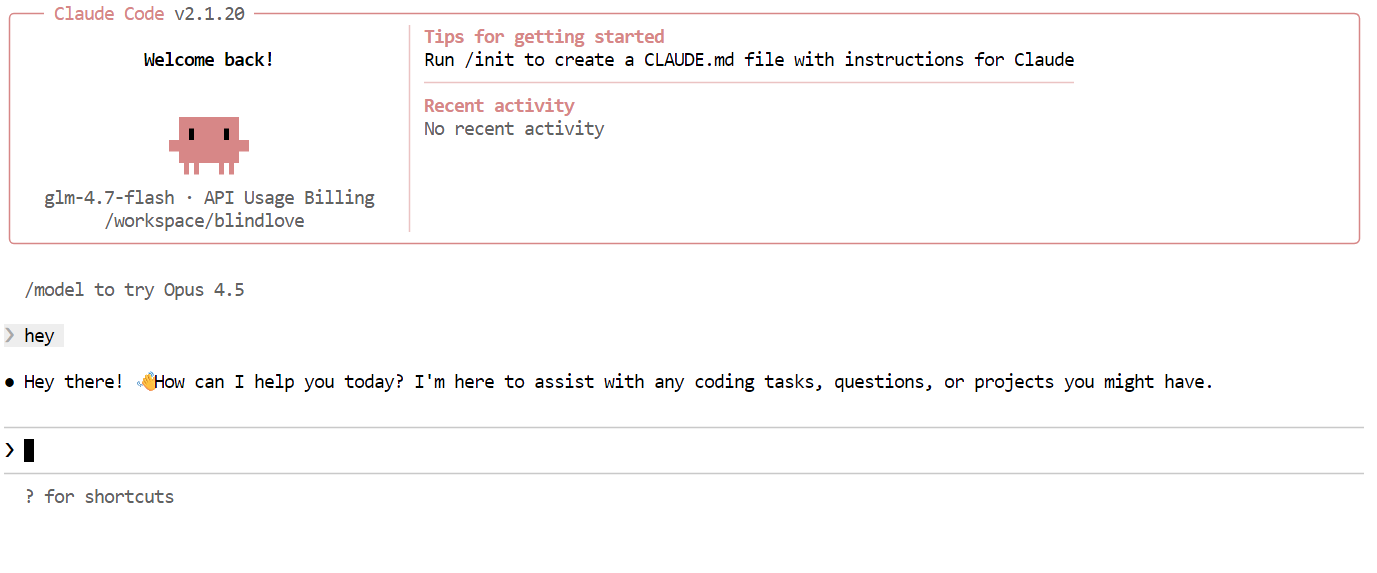
Selanjutnya, coba tugas pemrograman yang lebih realistis. Minta Claude Code membangun gim Snake CLI dalam Python. Sebelum menghasilkan kode, beralihlah ke mode perencanaan agar model menguraikan pendekatannya terlebih dahulu. Anda dapat mengaktifkan mode perencanaan dengan menekan Shift + Tab dua kali.
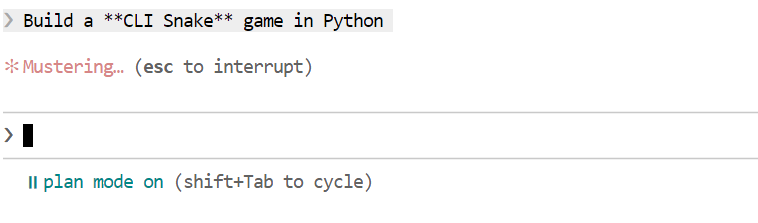 Setelah rencana dibuat, tinjau. Jika pendekatannya terlihat bagus, minta Claude Code untuk mengeksekusi rencana tersebut.
Setelah rencana dibuat, tinjau. Jika pendekatannya terlihat bagus, minta Claude Code untuk mengeksekusi rencana tersebut.
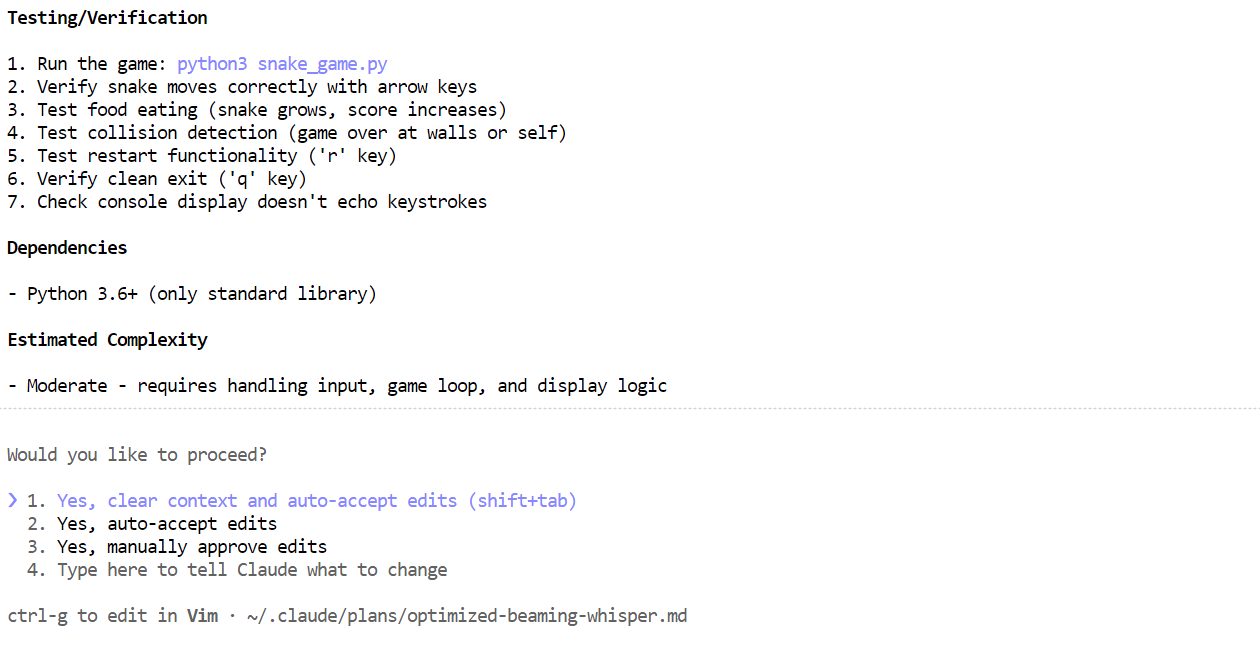 Dalam beberapa menit, ia telah membuat file yang diperlukan, menjelaskan apa yang dilakukan gim Snake, dan memberikan instruksi jelas tentang cara menjalankannya.
Dalam beberapa menit, ia telah membuat file yang diperlukan, menjelaskan apa yang dilakukan gim Snake, dan memberikan instruksi jelas tentang cara menjalankannya.
 Buka jendela terminal baru dan pastikan Anda berada di direktori proyek yang sama. Lalu mulai gim dengan:
Buka jendela terminal baru dan pastikan Anda berada di direktori proyek yang sama. Lalu mulai gim dengan:
python3 snake_game.pyGim berjalan langsung tanpa penyiapan tambahan. Ini adalah gim Snake berbasis terminal sederhana, sangat mirip dengan versi klasik Nokia 3310. Meski sederhana, ini adalah contoh yang bagus tentang betapa cepat dan efektifnya pengodean agen lokal dengan Claude Code dan Ollama.
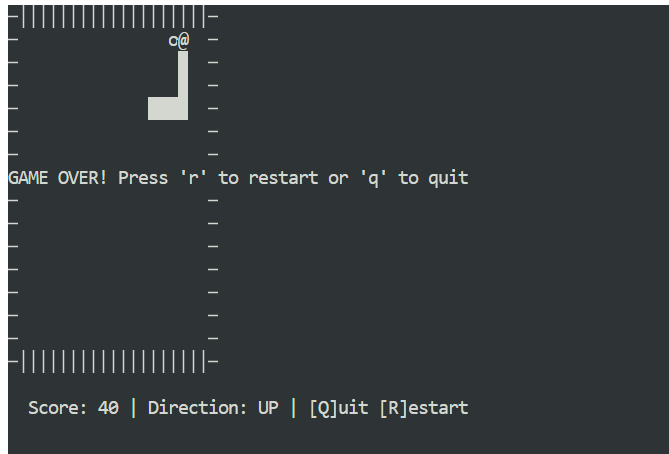
Menjalankan Claude Code dengan GLM 4.7 Flash di Ollama menunjukkan sejauh mana pengodean agen lokal telah berkembang. Anda mendapatkan respons cepat, kemampuan pembuatan kode yang kuat, dan kontrol penuh atas data Anda, semuanya tanpa bergantung pada model yang dihosting di cloud.
Setelah dikonfigurasi, alur kerjanya terasa mulus dan andal, bahkan untuk tugas pengodean multi-langkah.
Satu hal penting adalah bahwa jendela konteks yang lebih besar dan penyiapan yang lebih kompleks tidak selalu lebih baik. Dengan default yang masuk akal, keseluruhan penyiapan memakan waktu sekitar lima menit, tidak termasuk waktu unduh model yang bergantung pada koneksi internet Anda.
Jika Anda sudah memiliki file GGUF untuk model yang diunduh, penyiapan menjadi lebih cepat. Dalam kasus ini, Anda dapat melewati unduhan model sepenuhnya dan cukup mendaftarkan file GGUF yang ada ke Ollama dengan membuat sebuah Modelfile.
Ini memungkinkan Anda mendefinisikan parameter generasi sekali dan menggunakan model secara konsisten di berbagai sesi dan alat.
Buat file bernama Modelfile di direktori yang sama dengan file GGUF Anda:
FROM ./glm-4.7-flash.gguf
PARAMETER temperature 0.8
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.0Anda dapat menyesuaikan parameter sesuai kebutuhan:
Daftarkan model ke Ollama:
ollama create glm-4.7-flash-local -f ModelfileSetelah model dibuat, Anda dapat menjalankannya langsung dalam mode chat:
ollama run glm-4.7-flash-localModel sekarang dapat digunakan seperti model Ollama lainnya dan terintegrasi mulus dengan Claude Code.
Saya sangat menikmati membangun aplikasi dan gim menggunakan GLM 4.7 Flash di dalam Claude Code. Rasanya benar-benar memberdayakan untuk bekerja di tempat terpencil tanpa internet atau konektivitas tidak stabil. Semuanya berjalan secara lokal, tidak ada yang rusak, dan Anda tetap memiliki agen pengodean yang kuat di ujung jari Anda. Rasa kontrol dan kemandirian itu sulit ditandingi.
Jika Anda ingin mempelajari lebih lanjut tentang alat yang kita bahas dalam artikel ini, saya merekomendasikan sumber berikut:
Kursus Teratas DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
