
Curso
Projetando Sistemas Agentes com LangChain
3 h
12.1K
O GLM 4.7 Flash está rapidamente se tornando uma escolha popular para codificação de agentes locais. Muitos desenvolvedores estão usando isso com ferramentas como llama.cpp e LM Studio. Mas, muita gente ainda tem problemas na hora de configurar, fazer o modelo funcionar direito e garantir que a chamada da ferramenta funcione como esperado.
Este tutorial mostra a maneira mais simples e segura de rodar o GLM 4.7 Flash localmente usando o Claude Code com o Ollama. O objetivo é eliminar o atrito e ajudar você a obter uma configuração funcional sem complexidade desnecessária.
Este guia funciona em todos os sistemas operacionais. Não importa se você está usando Linux, Windows ou macOS. No final, você vai ter o GLM 4.7 Flash rodando localmente e integrado corretamente com o Claude Code através do Ollama.
Antes de começar, certifique-se de que seu sistema atenda aos requisitos mínimos de hardware e software abaixo.
Hardware:
Se você não tiver uma GPU, o modelo pode rodar em uma CPU, mas o desempenho vai ser bem mais lento e vai precisar de muita RAM.
Software:
Se o kit de ferramentas CUDA ou os drivers NVIDIA estiverem faltando ou forem incompatíveis, o Ollama vai voltar pro modo CPU, que é bem mais lento.
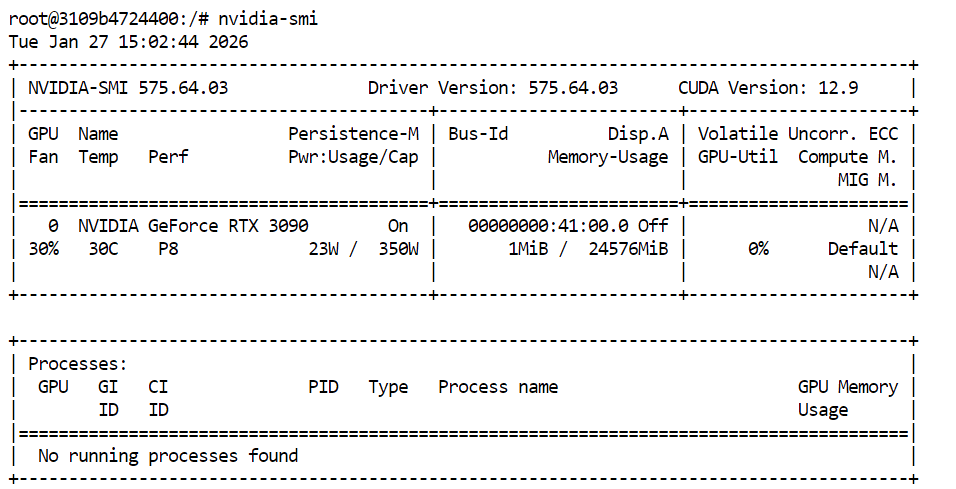
Pra conferir se os drivers da sua GPU e CUDA estão instalados direitinho, dá uma olhada no seguinte comando no seu terminal:
nvidia-smiSe tudo estiver configurado corretamente, você deverá ver sua GPU listada junto com a VRAM disponível e a versão CUDA.
O Ollama é o ambiente de execução que vamos usar pra rodar o GLM 4.7 Flash localmente e expô-lo de forma que o Claude Code possa interagir com ele de maneira confiável. A instalação é bem simples em todas as plataformas compatíveis.
No Linux, dá pra instalar o Ollama com um comando só:
curl -fsSL https://ollama.com/install.sh | shPara macOS e Windows, baixa o instalador direto do site da Ollama e siga as instruções na tela.

Fonte: Ollama
O Ollama funciona como um serviço em segundo plano e vai procurar atualizações automaticamente. Quando uma atualização estiver disponível, você pode aplicá-la selecionando “Reiniciar para atualizar” no menu do Ollama.
Depois de instalar, abra um terminal e veja se o Ollama tá instalado direitinho:
ollama -vVocê deve ver um resultado parecido com este:
ollama version is 0.15.2Se você vir um erro ao rodar ollama -v, geralmente quer dizer que o serviço Ollama ainda não está funcionando. Inicie o servidor Ollama manualmente:
ollama serveDeixe isso rodando, abra uma nova janela do terminal e execute:
ollama -vAssim que o comando version funcionar, o Ollama estará pronto para ser usado nas próximas etapas do tutorial.
Depois que o Ollama estiver instalado e funcionando, o próximo passo é baixar o modelo GLM 4.7 Flash e ver se ele tá funcionando direitinho. Essa etapa garante que o modelo funcione localmente antes de integrá-lo ao Claude Code.
Fonte: glm-4.7-flash
Comece baixando o modelo do registro da Ollama:
ollama pull glm-4.7-flashIsso vai baixar os arquivos do modelo e guardá-los no seu computador. Dependendo da velocidade da sua internet, isso pode demorar alguns minutos.
Depois que o download terminar, execute o modelo no modo de bate-papo interativo como uma rápida verificação de sanidade:
ollama run glm-4.7-flashDigite um comando simples, tipo uma saudação, e aperte Enter. Em alguns segundos, você deve receber uma resposta.
Se você estiver usando uma GPU, vai notar que as respostas são bem rápidas, e a saída pode incluir tokens de raciocínio interno ou traços de raciocínio, dependendo da configuração do modelo.

Você também pode testar o modelo através da API HTTP local do Ollama. Isso é útil para confirmar que as ferramentas externas podem se comunicar com o modelo.
Execute o seguinte comando:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role":"user","content":"Hello!"}]
}'O Claude Code e a maioria das ferramentas de codificação agentica funcionam melhor com janelas de contexto grandes, muitas vezes com até 64 mil tokens. Mas, com o GLM 4.7 Flash, escolher o comprimento de contexto certo é importante tanto para o desempenho quanto para a estabilidade.
Usar tamanhos de contexto muito grandes pode diminuir bastante a velocidade de geração. Na prática, a taxa de transferência de tokens pode cair de mais de 100 tokens por segundo para apenas 2 tokens por segundo. Às vezes, o modelo pode ficar preso em longos ciclos de reflexão se a janela de contexto estiver muito alta.
Testamos vários tamanhos de contexto e descobrimos que um contexto de 10k não era suficiente para os fluxos de trabalho do Claude Code. Um contexto de 20k proporcionou um bom equilíbrio. Era grande o suficiente para tarefas de codificação, mantendo tempos de resposta rápidos e reduzindo loops de pensamento desnecessários.
Primeiro, desligue o servidor Ollama. Você pode fazer isso pressionando “ Ctrl + C ” no terminal ou encerrando o processo.
Depois, reinicie o Ollama com um comprimento de contexto personalizado, definindo a variável de ambiente antes de iniciar o servidor:
OLLAMA_CONTEXT_LENGTH=20000 ollama serveIsso diz ao Ollama para carregar modelos com uma janela de contexto máxima de 20.000 tokens.
Em uma nova janela do terminal, execute:
ollama psIsso confirma que o GLM 4.7 Flash está rodando na GPU e que o comprimento do contexto foi definido corretamente. Neste momento, o modelo está configurado para uso estável e rápido com o Claude Code.
NAME ID SIZE PROCESSOR CONTEXT UNTIL
glm-4.7-flash:latest d1a8a26252f1 21 GB 100% GPU 20000 About a minute from now Claude Code é o agente de codificação baseado em terminal da Anthropic que ajuda você a escrever, editar, refatorar e entender código usando linguagem natural. Ele foi feito pra fluxos de trabalho de agentes e dá pra lidar com tarefas de codificação de várias etapas direto da sua linha de comando.
Quando combinado com o Ollama, o Claude Code pode ser facilmente usado com modelos locais, como o GLM 4.7 Flash, permitindo que você execute tudo localmente e mantenha seu código em sua máquina.
No macOS, Linux ou Windows usando WSL, instale o Claude Code usando o script instalador oficial:
curl -fsSL https://claude.ai/install.sh | bashEsse comando baixa e instala o Claude Code junto com as dependências necessárias. Quando a instalação terminar, o comando ` claude ` vai estar disponível no seu terminal.
Agora que o Ollama e o Claude Code estão instalados, o próximo passo é conectar o Claude Code ao seu servidor Ollama local e configurá-lo para usar o modelo GLM 4.7 Flash.
Comece criando um diretório de trabalho para o seu projeto. É aqui que o Claude Code vai operar e gerenciar os arquivos:
mkdir <project-name>
cd <project-name>O Ollama agora tem uma maneira integrada de abrir o Claude Code, que se configura automaticamente para se comunicar com o tempo de execução local do Ollama. Essa é a abordagem recomendada e mais confiável.
Para abrir o Claude Code de forma interativa usando o Ollama:
ollama launch claudePara iniciar diretamente o Claude Code usando o modelo GLM 4.7 Flash, execute:
ollama launch claude --model glm-4.7-flashIsso garante que o Claude Code use seu modelo GLM 4.7 Flash local em vez de um modelo remoto ou padrão.
Depois que tudo estiver configurado, você vai ver a interface do Claude Code direitinho no seu terminal.
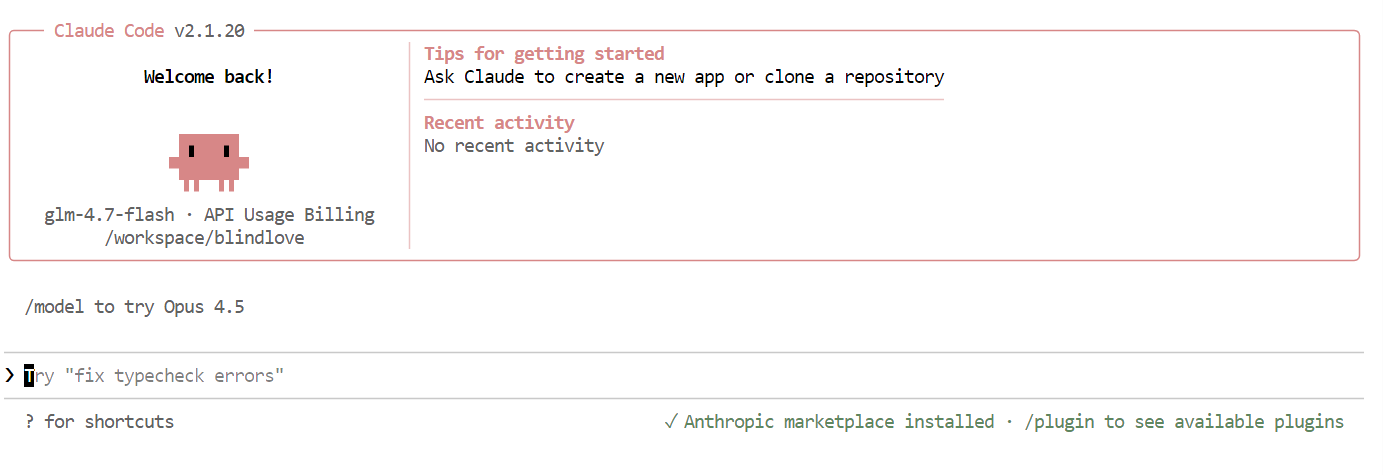
Dentro do Claude Code, use o seguinte comando para confirmar que ele está usando seu modelo local:
/modelSe a saída mostrar “ glm-4.7-flash ”, sua configuração está completa e o Claude Code está funcionando direitinho no seu modelo Ollama local.
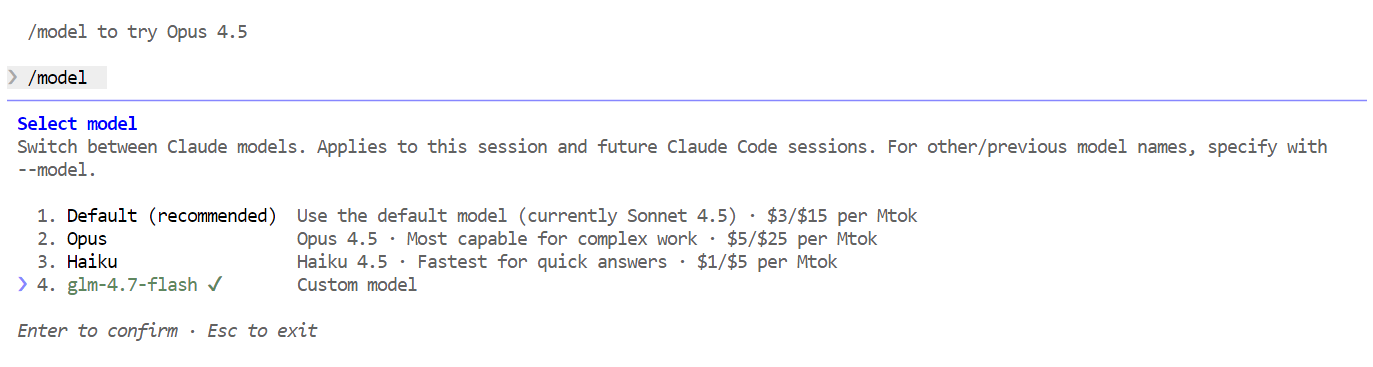
Com tudo configurado, agora você pode começar a usar o Claude Code com o seu modelo GLM 4.7 Flash local. A primeira coisa a tentar é uma saudação simples. Em um ou dois segundos, você deve receber uma resposta. A velocidade é bem rápida, principalmente quando tá rodando numa GPU.
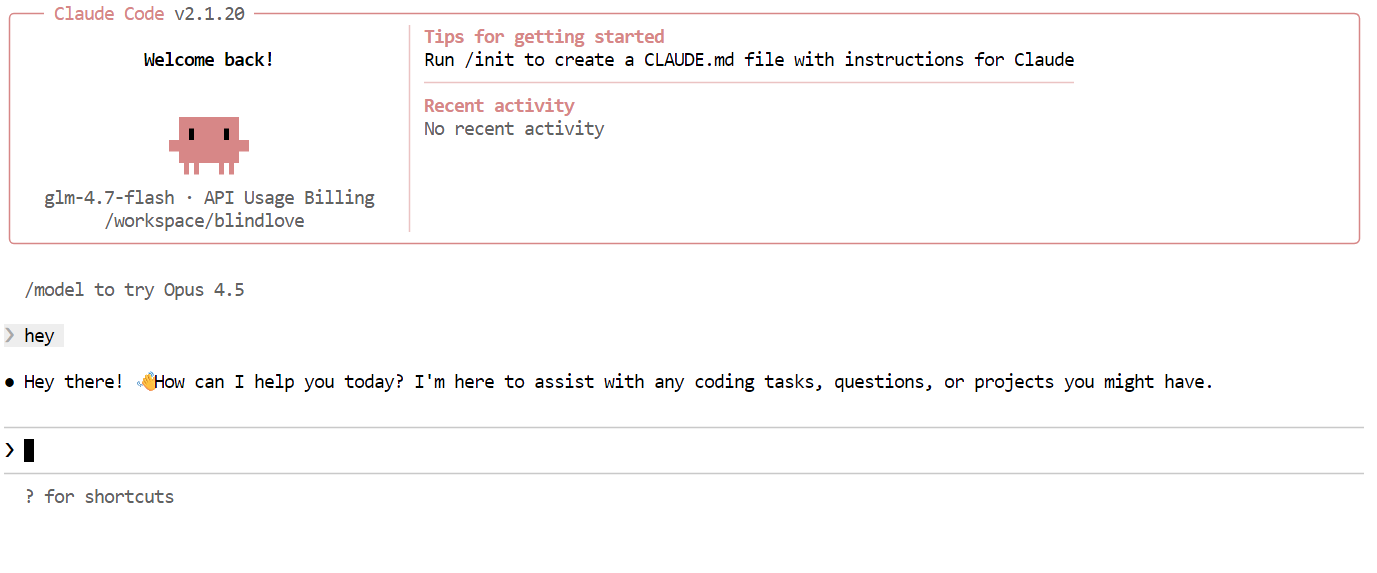
Depois, tente uma tarefa de programação mais realista. Peça ao Claude Code para criar um jogo Snake CLI em Python. Antes de gerar o código, mude para o modo de planejamento para que o modelo esboce sua abordagem primeiro. Você pode alternar o modo de planejamento pressionandoShift + Tab duas vezes.
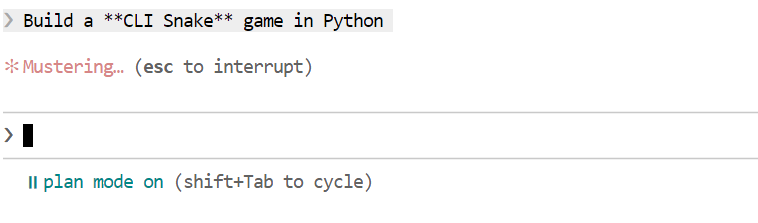 Depois que o plano estiver pronto, dá uma olhada nele. Se a abordagem parecer boa, diga ao Claude Code para colocar o plano em ação.
Depois que o plano estiver pronto, dá uma olhada nele. Se a abordagem parecer boa, diga ao Claude Code para colocar o plano em ação.
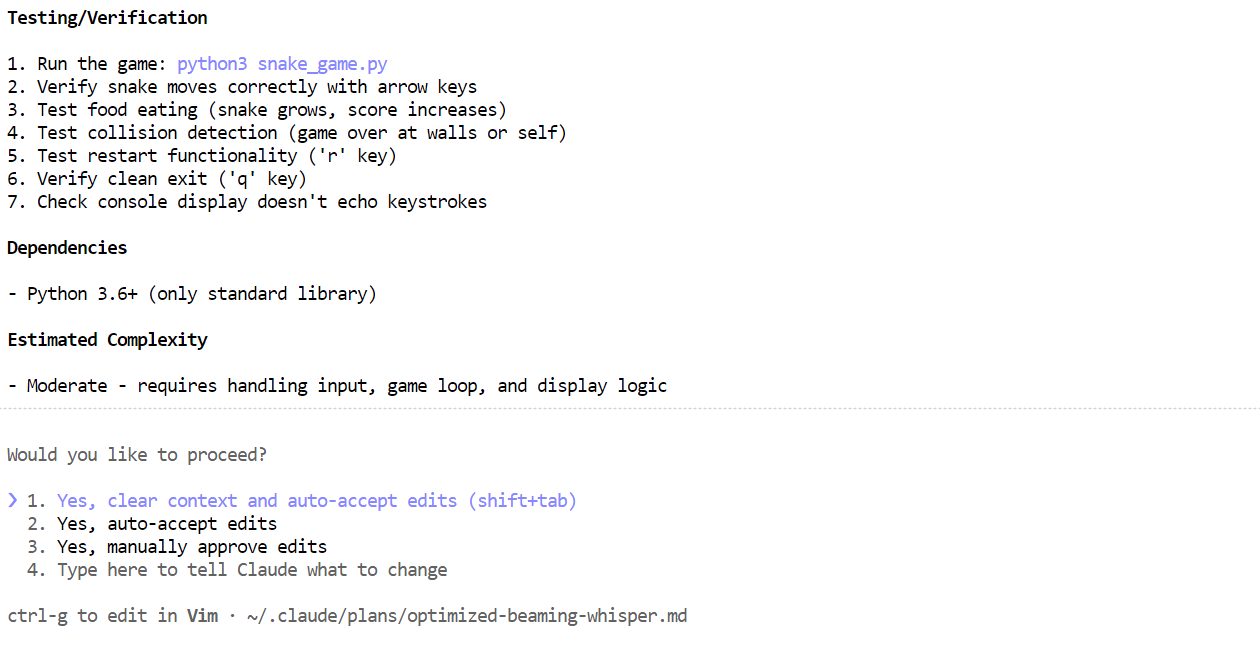 Em poucos minutos, ele criou os arquivos necessários, explicou o que o jogo Snake faz e forneceu instruções claras sobre como executá-lo.
Em poucos minutos, ele criou os arquivos necessários, explicou o que o jogo Snake faz e forneceu instruções claras sobre como executá-lo.
 Abra uma nova janela terminal e certifique-se de que você está no mesmo diretório do projeto. Então comece o jogo com:
Abra uma nova janela terminal e certifique-se de que você está no mesmo diretório do projeto. Então comece o jogo com:
python3 snake_game.pyO jogo funciona direto da caixa, sem precisar de nenhuma configuração extra. É um jogo Snake simples, tipo terminal, bem parecido com a versão clássica do Nokia 3310. Apesar de ser simples, é um ótimo exemplo de como a codificação local pode ser rápida e eficaz com o Claude Code e o Ollama.
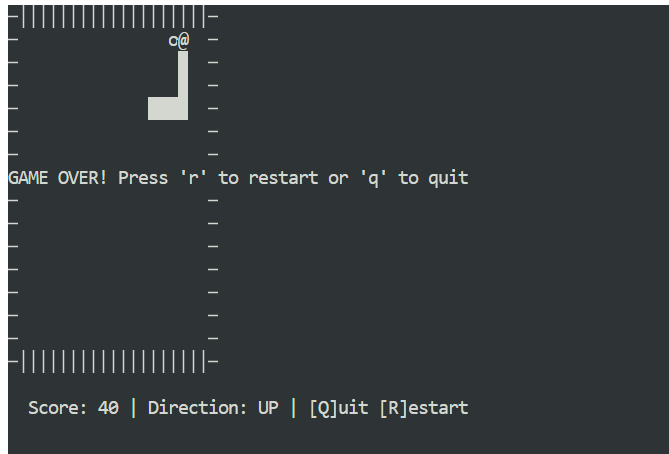
Executar o Claude Code com GLM 4.7 Flash no Ollama mostra o quanto a codificação local de agentes evoluiu. Você obtém respostas rápidas, geração de código robusta e controle total sobre seus dados, tudo isso sem depender de modelos hospedados na nuvem.
Depois de configurado, o fluxo de trabalho parece tranquilo e confiável, mesmo para tarefas de codificação com várias etapas.
Uma lição importante é que janelas de contexto maiores e configurações mais complexas nem sempre são melhores. Com as configurações padrão, a instalação toda leva uns cinco minutos, sem contar o tempo de download do modelo, que depende da sua conexão com a internet.
Se você já baixou o arquivo GGUF do modelo, a instalação vai ser ainda mais rápida. Nesse caso, você pode pular totalmente o download do modelo e só registrar o arquivo GGUF que já existe no Ollama, criando umarquivo de modelo .
Isso permite que você defina os parâmetros de geração uma vez e reutilize o modelo de forma consistente em todas as execuções e ferramentas.
Crie um arquivo chamado Modelfile no mesmo diretório do seu arquivo GGUF:
FROM ./glm-4.7-flash.gguf
PARAMETER temperature 0.8
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.0Você pode ajustar os parâmetros conforme necessário:
Cadastre o modelo no Ollama:
ollama create glm-4.7-flash-local -f ModelfileDepois que o modelo estiver pronto, você pode rodá-lo direto no modo de bate-papo:
ollama run glm-4.7-flash-localAgora, o modelo pode ser usado como qualquer outro modelo Ollama e integrado perfeitamente ao Claude Code.
Eu me diverti muito criando aplicativos e jogos usando o GLM 4.7 Flash dentro do Claude Code. É realmente empoderador trabalhar em um lugar remoto, sem internet ou com conexão instável. Tudo funciona localmente, nada dá errado e você ainda tem um poderoso agente de codificação ao seu alcance. É difícil superar essa sensação de controle e independência.
Se você quiser saber mais sobre as ferramentas que falamos neste artigo, recomendo os seguintes recursos:
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan


