
Kurs
Agentische Systeme mit LangChain entwerfen
3 Std.
12.1K
GLM 4.7 Flash wird schnell zu einer beliebten Wahl für die lokale agentenbasierte Codierung. Viele Entwickler nutzen es mit Tools wie llama.cpp und LM Studio. Viele Leute haben aber immer noch Probleme beim Einrichten, beim korrekten Ausführen des Modells und beim Sicherstellen, dass der Toolaufruf wie erwartet funktioniert.
Dieses Tutorial zeigt dir, wie du GLM 4.7 Flash am einfachsten und zuverlässigsten lokal mit Claude Code und Ollama laufen lassen kannst. Das Ziel ist, Probleme zu beseitigen und dir zu helfen, eine funktionierende Konfiguration ohne unnötige Komplexität zu bekommen.
Dieser Leitfaden funktioniert auf allen Betriebssystemen. Es ist egal, ob du Linux, Windows oder macOS benutzt. Am Ende hast du GLM 4.7 Flash lokal installiert und über Ollama richtig mit Claude Code verbunden.
Bevor du loslegst, check bitte, ob dein System die unten aufgeführten Mindestanforderungen an Hardware und Software erfüllt.
Hardware:
Wenn du keine GPU hast, kannst du das Modell auch auf einer CPU laufen lassen, aber die Leistung wird deutlich langsamer sein und du brauchst viel RAM.
Software:
Wenn das CUDA-Toolkit oder die NVIDIA-Treiber fehlen oder nicht passen, wechselt Ollama zum CPU-Modus, der echt langsam ist.
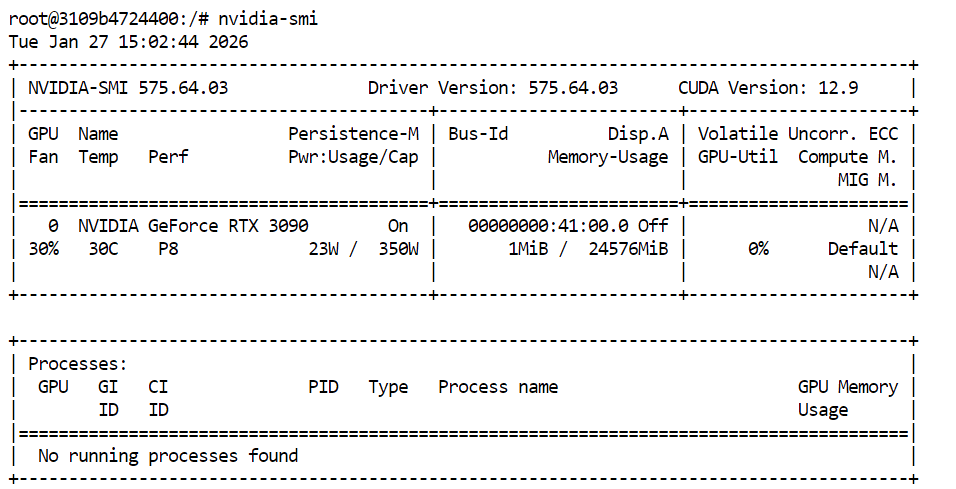
Um zu checken, ob deine GPU- und CUDA-Treiber richtig installiert sind, gib einfach den folgenden Befehl in dein Terminal ein:
nvidia-smiWenn alles richtig eingerichtet ist, solltest du deine GPU zusammen mit dem verfügbaren VRAM und der CUDA-Version sehen.
Ollama ist die Laufzeitumgebung, die wir nutzen werden, um GLM 4.7 Flash lokal auszuführen und so bereitzustellen, dass Claude Code zuverlässig damit interagieren kann. Die Installation ist auf allen unterstützten Plattformen ganz einfach.
Unter Linux kannst du Ollama mit einem einzigen Befehl installieren:
curl -fsSL https://ollama.com/install.sh | shFür macOS und Windows kannst du das Installationsprogramm direkt von der Ollama Website und folge den Anweisungen auf dem Bildschirm.

Quelle: Ollama
Ollama läuft im Hintergrund und sucht automatisch nach Updates. Wenn ein Update verfügbar ist, kannst du es installieren, indem du im Ollama-Menü „Zum Aktualisieren neu starten“ auswählst.
Öffne nach der Installation ein Terminal und schau nach, ob Ollama richtig installiert ist:
ollama -vDu solltest eine Ausgabe sehen, die ungefähr so aussieht:
ollama version is 0.15.2Wenn du beim Ausführen von „ ollama -v “ einen Fehler siehst, heißt das meistens, dass der Ollama-Dienst noch nicht läuft. Starte den Ollama-Server einfach so:
ollama serveLass das laufen, öffne ein neues Terminalfenster und führe dann Folgendes aus:
ollama -vSobald der Befehl „version“ funktioniert, kannst du Ollama in den nächsten Schritten des Tutorials benutzen.
Sobald Ollama installiert ist und läuft, musst du als Nächstes das GLM 4.7 Flash-Modell runterladen und checken, ob es richtig funktioniert. Dieser Schritt stellt sicher, dass das Modell lokal läuft, bevor es in Claude Code integriert wird.
Quelle: glm-4.7-flash
Lade zuerst das Modell aus dem Ollama-Register runter:
ollama pull glm-4.7-flashDadurch werden die Modelldateien runtergeladen und lokal gespeichert. Je nachdem, wie schnell dein Internet ist, kann das ein paar Minuten dauern.
Sobald der Download fertig ist, starte das Modell im interaktiven Chat-Modus, um schnell zu checken, ob alles klappt:
ollama run glm-4.7-flashGib einfach was ein, zum Beispiel einen Gruß, und drück die Eingabetaste. Innerhalb von ein paar Sekunden solltest du eine Antwort bekommen.
Wenn du auf einer GPU arbeitest, wirst du merken, dass die Antworten echt schnell sind, und die Ausgabe kann je nach Modellkonfiguration interne Denktoken oder Argumentationsspuren enthalten.

Du kannst das Modell auch über die lokale HTTP-API von Ollama testen. Das ist nützlich, um zu checken, ob externe Tools mit dem Modell klarkommen.
Mach mal den folgenden Befehl:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role":"user","content":"Hello!"}]
}'Claude Code und die meisten agentenbasierten Codierungswerkzeuge funktionieren am besten mit großen Kontextfenstern, oft bis zu 64k Tokens. Bei GLM 4.7 Flash ist es aber wichtig, die richtige Kontextlänge zu wählen, damit alles gut läuft und stabil bleibt.
Wenn du echt große Kontextgrößen nimmst, kann das die Generierungsgeschwindigkeit ziemlich runterziehen. In der Praxis kann der Token-Durchsatz von über 100 Token pro Sekunde auf nur noch 2 Token pro Sekunde sinken. Manchmal kann das Modell auch in langen Gedankenschleifen hängen bleiben, wenn das Kontextfenster zu hoch eingestellt ist.
Wir haben verschiedene Kontextgrößen getestet und festgestellt, dass ein Kontext von 10k für Claude Code-Workflows nicht ausreicht. Ein 20k-Kontext hat für eine gute Balance gesorgt. Es war groß genug für Programmieraufgaben, während es trotzdem schnelle Reaktionszeiten hatte und unnötige Gedankenschleifen vermied.
Halt zuerst den laufenden Ollama-Server an. Du kannst das machen, indem du im Terminal „ Ctrl + C “ eingibst oder den Prozess beendest.
Als Nächstes startest du Ollama mit einer benutzerdefinierten Kontextlänge neu, indem du vor dem Starten des Servers die Umgebungsvariable festlegst:
OLLAMA_CONTEXT_LENGTH=20000 ollama serveDamit wird Ollama gesagt, dass es Modelle mit einem maximalen Kontextfenster von 20.000 Tokens laden soll.
Mach in einem neuen Terminalfenster Folgendes:
ollama psDas zeigt, dass GLM 4.7 Flash auf der GPU läuft und die Kontextlänge richtig eingestellt ist. Im Moment ist das Modell so eingestellt, dass es mit Claude Code stabil und schnell läuft.
NAME ID SIZE PROCESSOR CONTEXT UNTIL
glm-4.7-flash:latest d1a8a26252f1 21 GB 100% GPU 20000 About a minute from now Claude Code ist der terminalbasierte Codierungsagent von Anthropic, der dir dabei hilft, Code mithilfe natürlicher Sprache zu schreiben, zu bearbeiten, umzugestalten und zu verstehen. Es ist für agentenbasierte Arbeitsabläufe gemacht und kann mehrstufige Codierungsaufgaben direkt über deine Befehlszeile erledigen.
Zusammen mit Ollama kannst du Claude Code ganz einfach mit lokalen Modellen wie GLM 4.7 Flash nutzen. So kannst du alles lokal ausführen und deinen Code auf deinem Rechner behalten.
Installiere Claude Code auf macOS, Linux oder Windows mit WSL über das offizielle Installationsskript:
curl -fsSL https://claude.ai/install.sh | bashDieser Befehl lädt Claude Code und die benötigten Abhängigkeiten runter und installiert sie. Sobald die Installation fertig ist, kannst du den Befehl „ claude “ in deinem Terminal benutzen.
Jetzt, wo sowohl Ollama als auch Claude Code installiert sind, musst du Claude Code mit deinem lokalen Ollama-Server verbinden und es so einrichten, dass es das GLM 4.7 Flash-Modell nutzt.
Mach zuerst ein Arbeitsverzeichnis für dein Projekt. Hier wird Claude Code Dateien bearbeiten und verwalten:
mkdir <project-name>
cd <project-name>Ollama hat jetzt eine eingebaute Funktion, um Claude Code zu starten, die automatisch so konfiguriert wird, dass sie mit der lokalen Ollama-Laufzeitumgebung kommuniziert. Das ist der beste und sicherste Weg.
So startest du Claude Code interaktiv mit Ollama:
ollama launch claudeUm Claude Code direkt mit dem GLM 4.7 Flash-Modell zu starten, mach Folgendes:
ollama launch claude --model glm-4.7-flashDadurch wird sichergestellt, dass Claude Code dein lokales GLM 4.7 Flash-Modell anstelle eines Remote- oder Standardmodells verwendet.
Sobald alles eingerichtet ist, siehst du die Claude Code-Oberfläche direkt in deinem Terminal.
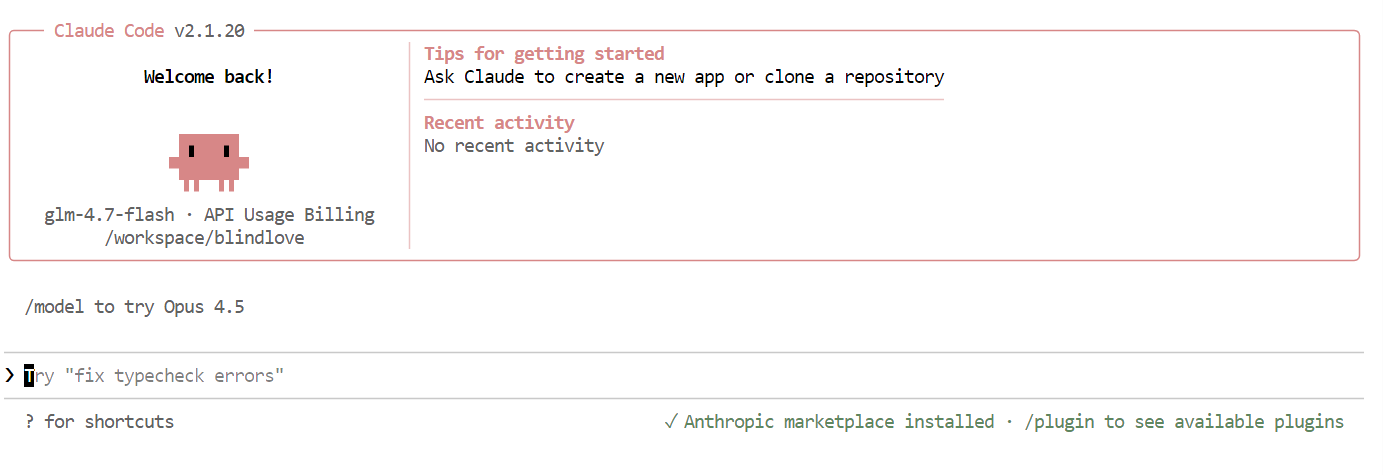
Verwendest du in Claude Code den folgenden Befehl, um zu checken, ob dein lokales Modell benutzt wird:
/modelWenn die Ausgabe „ glm-4.7-flash “ anzeigt, ist deine Einrichtung fertig und Claude Code läuft erfolgreich auf deinem lokalen Ollama-Modell.
Jetzt, wo alles eingerichtet ist, kannst du Claude Code mit deinem lokalen GLM 4.7 Flash-Modell nutzen. Das Erste, was du probieren solltest, ist eine einfache Begrüßung. Innerhalb von ein oder zwei Sekunden solltest du eine Antwort bekommen. Die Geschwindigkeit ist echt schnell, vor allem, wenn man auf einer GPU läuft.
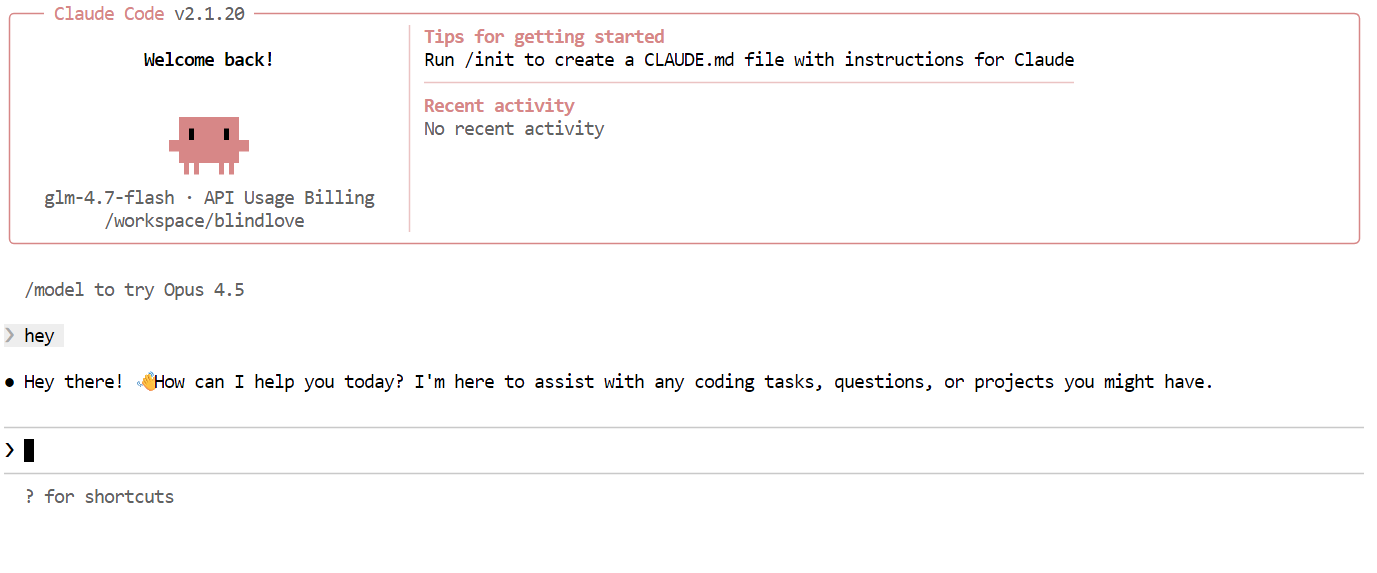
Probier als Nächstes eine realistischere Programmieraufgabe aus. Frag Claude Code, ob er ein CLI-Snake-Spiel in Python programmieren kann. Bevor du Code erstellst, schalte in den Planungsmodus, damit das Modell zuerst seinen Ansatz skizziert. Du kannst den Planungsmodus aktivieren, indem du zweimal auf die Tasten„ “ „Shift“ + „Tab“ drückst.
 -Wenn der Plan fertig ist, schau ihn dir an. Wenn der Plan gut aussieht, sag Claude Code, er soll ihn umsetzen.
-Wenn der Plan fertig ist, schau ihn dir an. Wenn der Plan gut aussieht, sag Claude Code, er soll ihn umsetzen.
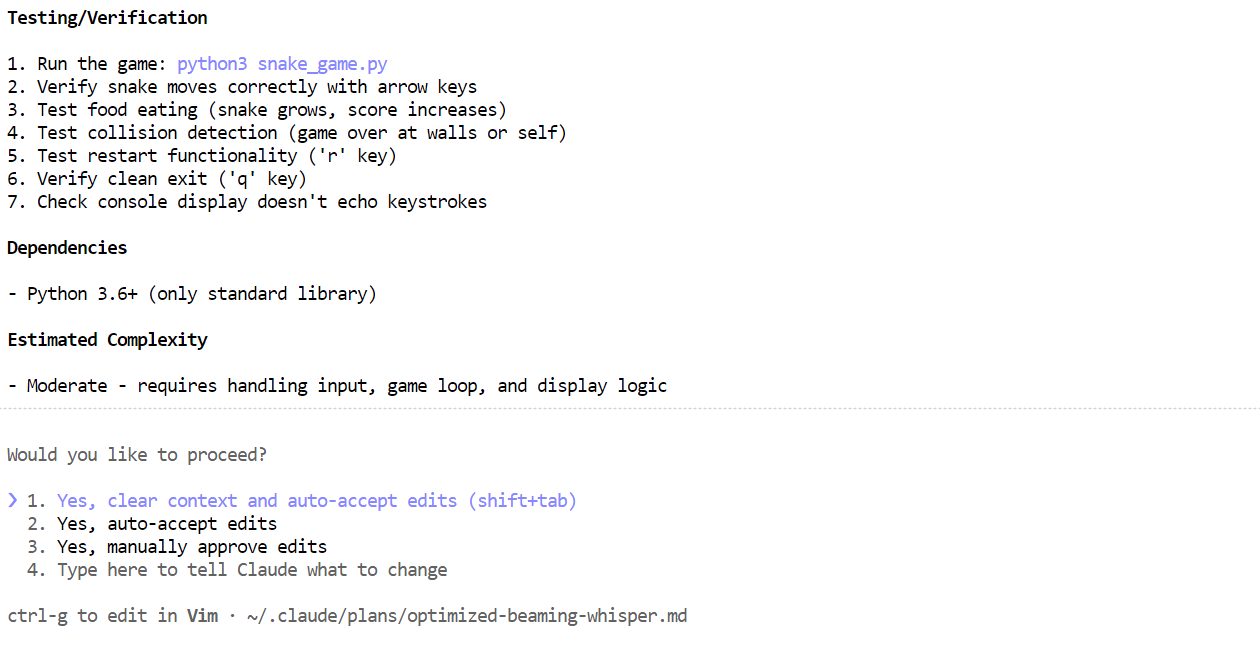 Innerhalb weniger Minuten hat es die benötigten Dateien erstellt, erklärt, was das Snake-Spiel macht, und klare Anweisungen gegeben, wie man es ausführt.
Innerhalb weniger Minuten hat es die benötigten Dateien erstellt, erklärt, was das Snake-Spiel macht, und klare Anweisungen gegeben, wie man es ausführt.
 Öffne ein neues Terminalfenster und stell sicher, dass du dich im selben Projektverzeichnis befindest. Dann startest du das Spiel mit:
Öffne ein neues Terminalfenster und stell sicher, dass du dich im selben Projektverzeichnis befindest. Dann startest du das Spiel mit:
python3 snake_game.pyDas Spiel läuft sofort, ohne dass du was extra einrichten musst. Es ist ein einfaches Snake-Spiel für den Terminal, das der klassischen Version für das Nokia 3310 echt ähnlich ist. Trotz seiner Einfachheit ist es ein super Beispiel dafür, wie schnell und effektiv die lokale agentenbasierte Codierung mit Claude Code und Ollama sein kann.
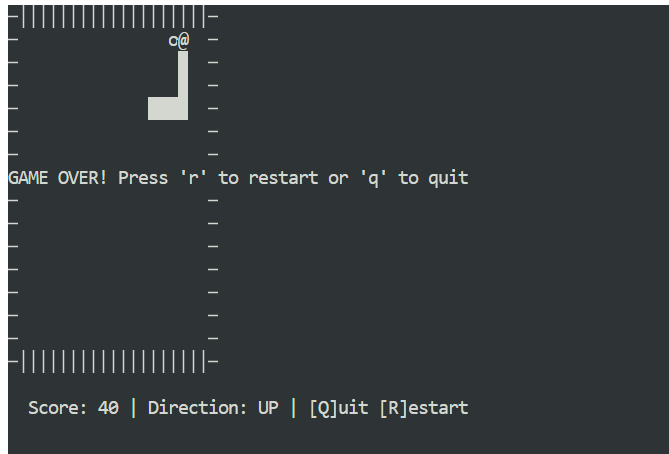
Wenn man Claude Code mit GLM 4.7 Flash auf Ollama ausführt, sieht man, wie weit die lokale agentenbasierte Codierung schon gekommen ist. Du bekommst schnelle Antworten, starke Codegenerierung und volle Kontrolle über deine Daten, ohne dich auf Cloud-gehostete Modelle verlassen zu müssen.
Sobald der Workflow eingerichtet ist, läuft alles reibungslos und zuverlässig, auch bei mehrstufigen Codierungsaufgaben.
Eine wichtige Erkenntnis ist, dass größere Kontextfenster und kompliziertere Setups nicht immer besser sind. Mit vernünftigen Standardeinstellungen dauert die ganze Einrichtung etwa fünf Minuten, ohne die Zeit für den Download des Modells, die von deiner Internetverbindung abhängt.
Wenn du die GGUF-Datei für das Modell schon runtergeladen hast, geht die Einrichtung noch schneller. In diesem Fall kannst du den Modell-Download komplett überspringen und einfach die vorhandene GGUF-Datei bei Ollama registrieren, indem du eineModelldatei „ “ erstellst.
Damit kannst du die Generierungsparameter einmal festlegen und das Modell dann bei allen Durchläufen und Tools immer wieder verwenden.
Mach eine Datei namens „ Modelfile ” im selben Verzeichnis wie deine GGUF-Datei:
FROM ./glm-4.7-flash.gguf
PARAMETER temperature 0.8
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.0Du kannst die Einstellungen nach Bedarf anpassen:
Registriere das Modell bei Ollama:
ollama create glm-4.7-flash-local -f ModelfileSobald das Modell erstellt ist, kannst du es direkt im Chat-Modus ausführen:
ollama run glm-4.7-flash-localDas Modell kann jetzt wie jedes andere Ollama-Modell verwendet und nahtlos in Claude Code integriert werden.
Ich hatte echt Spaß beim Erstellen von Apps und Spielen mit GLM 4.7 Flash in Claude Code. Es fühlt sich echt gut an, an einem abgelegenen Ort ohne Internet oder mit einer wackeligen Verbindung zu arbeiten. Alles läuft lokal, nichts geht kaputt, und du hast trotzdem einen leistungsstarken Coding-Agenten zur Hand. Dieses Gefühl von Kontrolle und Unabhängigkeit ist echt unschlagbar.
Wenn du mehr über die Tools erfahren willst, die wir in diesem Artikel vorgestellt haben, empfehle ich dir die folgenden Ressourcen:
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Kurtis Pykes
Tutorial
Mark Pedigo
Tutorial
Stephen Gruppetta
