
Curso
Diseño de sistemas agénticos con LangChain
3 h
12.1K
GLM 4.7 Flash se está convirtiendo rápidamente en una opción popular para la codificación de agentes locales. Muchos programadores lo están utilizando con herramientas como llama.cpp y LM Studio. Sin embargo, muchas personas siguen teniendo problemas durante la configuración, para que el modelo funcione correctamente y para asegurarse de que la llamada a las herramientas funciona como se espera.
Este tutorial se centra en la forma más sencilla y fiable de ejecutar GLM 4.7 Flash localmente utilizando Claude Code con Ollama. El objetivo es eliminar las fricciones y ayudarte a conseguir una configuración funcional sin complicaciones innecesarias.
Esta guía funciona en todos los sistemas operativos. No importa si utilizas Linux, Windows o macOS. Al final, tendrás GLM 4.7 Flash ejecutándose localmente y correctamente integrado con Claude Code a través de Ollama.
Antes de comenzar, asegúrate de que tu sistema cumpla con los requisitos mínimos de hardware y software que se indican a continuación.
Hardware:
Si no dispones de una GPU, el modelo puede ejecutarse en una CPU, pero el rendimiento será significativamente más lento y se requerirá una gran cantidad de RAM.
Software:
Si faltan o son incompatibles el kit de herramientas CUDA o los controladores NVIDIA, Ollama volverá al modo CPU, que es mucho más lento.
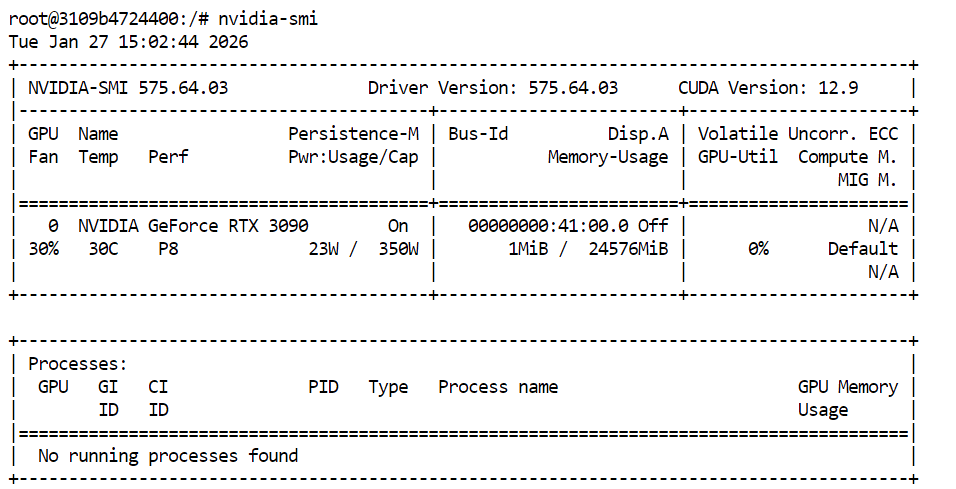
Para verificar que los controladores de la GPU y CUDA estén instalados correctamente, ejecuta el siguiente comando en tu terminal:
nvidia-smiSi todo está configurado correctamente, deberías ver tu GPU en la lista junto con la VRAM disponible y la versión de CUDA.
Ollama es el tiempo de ejecución que utilizaremos para ejecutar GLM 4.7 Flash localmente y exponerlo de manera que Claude Code pueda interactuar con él de forma fiable. La instalación es sencilla en todas las plataformas compatibles.
En Linux, puedes instalar Ollama con un solo comando:
curl -fsSL https://ollama.com/install.sh | shPara macOS y Windows, descarguen el instalador directamente desde sitio web de Ollama y sigue las instrucciones que aparecen en pantalla.

Fuente: Ollama
Ollama se ejecuta como un servicio en segundo plano y comprueba automáticamente si hay actualizaciones. Cuando haya una actualización disponible, podrás aplicarla seleccionando «Reiniciar para actualizar» en el menú de Ollama.
Después de la instalación, abre un terminal y comprueba que Ollama se ha instalado correctamente:
ollama -vDeberías ver un resultado similar al siguiente:
ollama version is 0.15.2Si ves un error al ejecutar ollama -v, normalmente significa que el servicio Ollama aún no se está ejecutando. Inicia el servidor Ollama manualmente:
ollama serveDeja esto en ejecución, abre una nueva ventana de terminal y, a continuación, ejecuta:
ollama -vUna vez que el comando version funcione, Ollama estará listo para utilizarse en los siguientes pasos del tutorial.
Una vez que Ollama esté instalado y en funcionamiento, el siguiente paso es descargar el modelo GLM 4.7 Flash y verificar que funciona correctamente. Este paso garantiza que el modelo se ejecute localmente antes de integrarlo con Claude Code.
Fuente: glm-4.7-flash
Empieza descargando el modelo del registro de Ollama:
ollama pull glm-4.7-flashEsto descargará los archivos del modelo y los almacenará localmente. Dependiendo de la velocidad de tu conexión a Internet, esto puede tardar unos minutos.
Una vez completada la descarga, ejecuta el modelo en modo de chat interactivo como una rápida comprobación de funcionamiento:
ollama run glm-4.7-flashEscribe un mensaje sencillo, como un saludo, y pulsa Intro. En unos segundos, deberías recibir una respuesta.
Si estás ejecutando en una GPU, notarás que las respuestas son muy rápidas y que el resultado puede incluir tokens de pensamiento interno o rastros de razonamiento, dependiendo de la configuración del modelo.

También puedes probar el modelo a través de la API HTTP local de Ollama. Esto resulta útil para confirmar que las herramientas externas pueden comunicarse con el modelo.
Ejecuta el siguiente comando:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role":"user","content":"Hello!"}]
}'Claude Code y la mayoría de las herramientas de codificación agentica funcionan mejor con ventanas de contexto grandes, a menudo de hasta 64 000 tokens. Sin embargo, con GLM 4.7 Flash, elegir la longitud de contexto adecuada es importante tanto para el rendimiento como para la estabilidad.
El uso de tamaños de contexto muy grandes puede ralentizar significativamente la velocidad de generación. En la práctica, el rendimiento de los tokens puede caer de más de 100 tokens por segundo a tan solo 2 tokens por segundo. En algunos casos, el modelo también puede quedarse atascado en largos bucles de reflexión si la ventana de contexto se establece demasiado alta.
Probamos varios tamaños de contexto y descubrimos que un contexto de 10 000 no era suficiente para los flujos de trabajo de Claude Code. Un contexto de 20 000 palabras proporcionaba un buen equilibrio. Era lo suficientemente grande como para realizar tareas de programación, al tiempo que mantenía tiempos de respuesta rápidos y reducía los bucles de pensamiento innecesarios.
En primer lugar, detén el servidor Ollama en ejecución. Para ello, pulsa « Ctrl + C » en la terminal o finaliza el proceso.
A continuación, reinicia Ollama con una longitud de contexto personalizada configurando la variable de entorno antes de iniciar el servidor:
OLLAMA_CONTEXT_LENGTH=20000 ollama serveEsto le indica a Ollama que cargue modelos con una ventana de contexto máxima de 20 000 tokens.
En una nueva ventana de terminal, ejecuta:
ollama psEsto confirma que GLM 4.7 Flash se está ejecutando en la GPU y que la longitud del contexto se ha configurado correctamente. En este punto, el modelo está configurado para un uso estable y rápido con Claude Code.
NAME ID SIZE PROCESSOR CONTEXT UNTIL
glm-4.7-flash:latest d1a8a26252f1 21 GB 100% GPU 20000 About a minute from now Claude Code es el agente de codificación basado en terminal de Anthropic que te ayuda a escribir, editar, refactorizar y comprender código utilizando lenguaje natural. Está diseñado para flujos de trabajo de agentes y puede gestionar tareas de codificación de varios pasos directamente desde la línea de comandos.
Cuando se combina con Ollama, Claude Code se puede utilizar fácilmente con modelos locales como GLM 4.7 Flash, lo que te permite ejecutar todo localmente y mantener tu código en tu máquina.
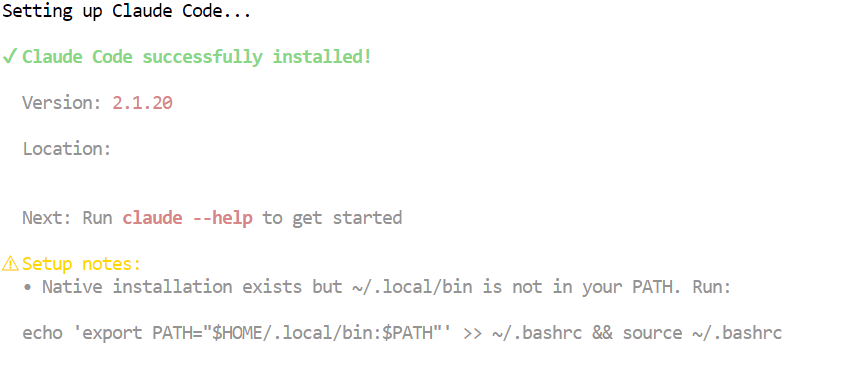
En macOS, Linux o Windows con WSL, instala Claude Code utilizando el script de instalación oficial:
curl -fsSL https://claude.ai/install.sh | bashEste comando descarga e instala Claude Code junto con las dependencias necesarias. Una vez completada la instalación, el comando « claude » estará disponible en tu terminal.
Ahora que ya tienes instalados tanto Ollama como Claude Code, el siguiente paso es conectar Claude Code a tu servidor Ollama local y configurarlo para que utilice el modelo GLM 4.7 Flash.
Comienza creando un directorio de trabajo para tu proyecto. Aquí es donde Claude Code operará y gestionará los archivos:
mkdir <project-name>
cd <project-name>Ollama ahora ofrece una forma integrada de iniciar Claude Code que lo configura automáticamente para comunicarse con el tiempo de ejecución local de Ollama. Este es el enfoque recomendado y más fiable.
Para iniciar Claude Code de forma interactiva utilizando Ollama:
ollama launch claudePara iniciar directamente Claude Code utilizando el modelo GLM 4.7 Flash, ejecuta:
ollama launch claude --model glm-4.7-flashEsto garantiza que Claude Code utilice tu modelo Flash GLM 4.7 local en lugar de un modelo remoto o predeterminado.
Una vez que todo esté configurado, verás la interfaz de Claude Code directamente en tu terminal.
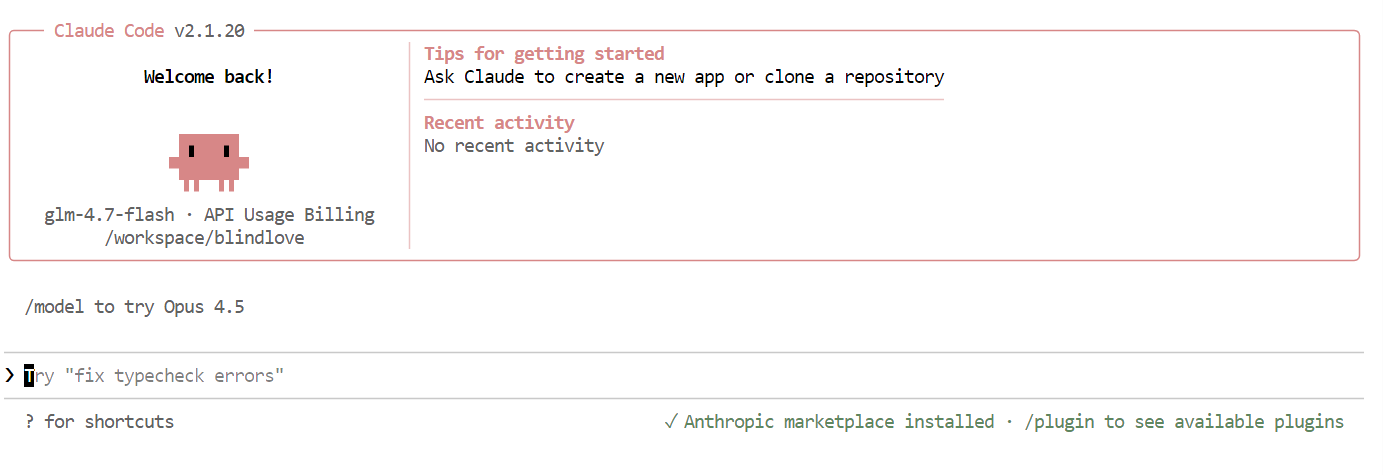
Dentro de Claude Code, utiliza el siguiente comando para confirmar que está utilizando tu modelo local:
/modelSi la salida muestra « glm-4.7-flash », la configuración está completa y Claude Code se está ejecutando correctamente en tu modelo Ollama local.
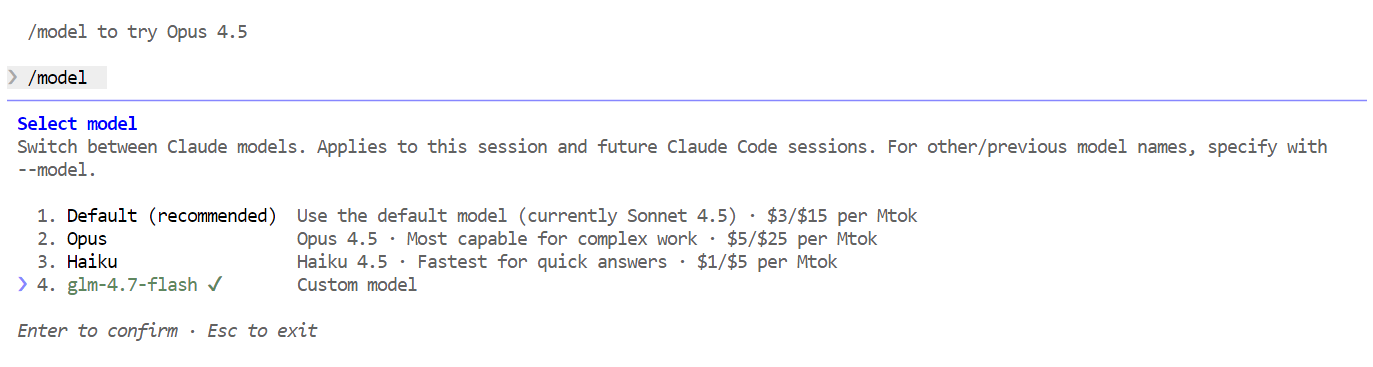
Una vez configurado todo, ya puedes empezar a utilizar Claude Code con tu modelo Flash GLM 4.7 local. Lo primero que hay que intentar es un simple saludo. En uno o dos segundos, deberías recibir una respuesta. La velocidad es notablemente rápida, especialmente cuando se ejecuta en una GPU.
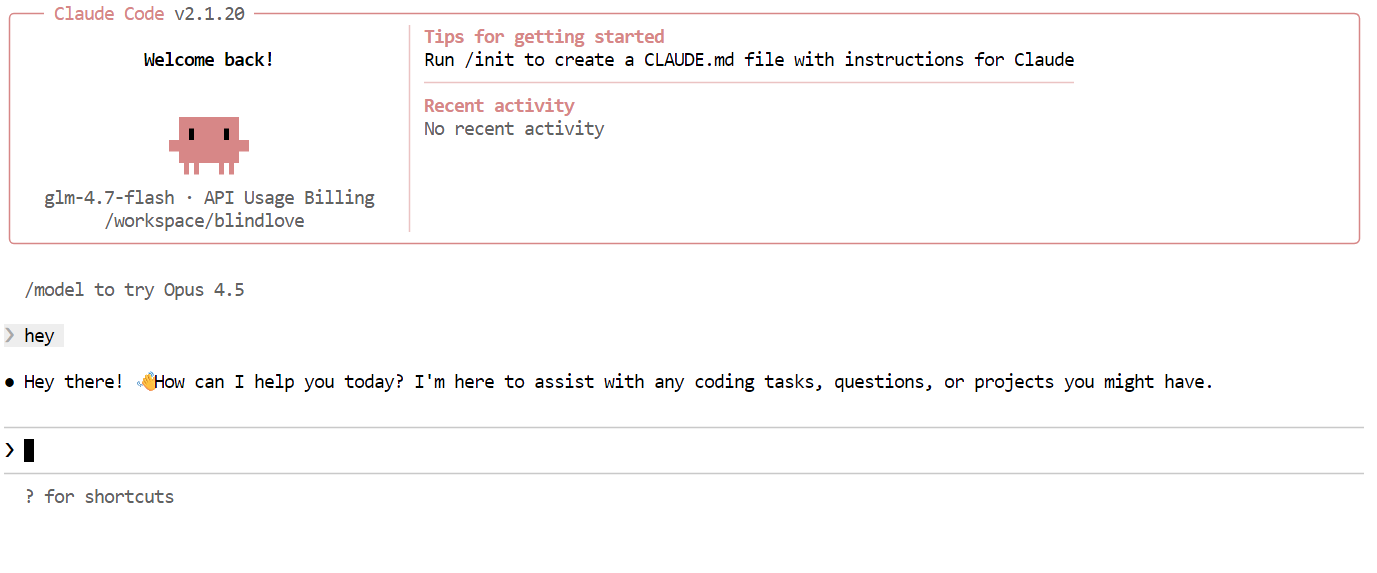
A continuación, prueba con una tarea de programación más realista. Pídele a Claude Code que cree un juego Snake CLI en Python. Antes de generar código, cambia al modo de planificación para que el modelo describa primero su enfoque. Puedes activar o desactivar el modo de planificación pulsando dos veces Shift + Tab.
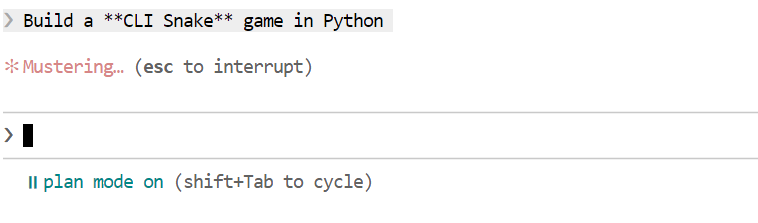 Una vez generado el plan, revísalo. Si el enfoque parece bueno, dile a Claude Code que ejecute el plan.
Una vez generado el plan, revísalo. Si el enfoque parece bueno, dile a Claude Code que ejecute el plan.
 En pocos minutos, ha creado los archivos necesarios, ha explicado cómo funciona el juego Snake y ha proporcionado instrucciones claras sobre cómo ejecutarlo.
En pocos minutos, ha creado los archivos necesarios, ha explicado cómo funciona el juego Snake y ha proporcionado instrucciones claras sobre cómo ejecutarlo.
 Abre una nueva ventana de terminal y asegúrate de que estás en el mismo directorio del proyecto. A continuación, inicia el juego con:
Abre una nueva ventana de terminal y asegúrate de que estás en el mismo directorio del proyecto. A continuación, inicia el juego con:
python3 snake_game.pyEl juego funciona nada más instalarlo, sin necesidad de configuración adicional. Es un sencillo juego Snake basado en terminal, muy similar a la versión clásica del Nokia 3310. A pesar de su simplicidad, es un gran ejemplo de lo rápido y eficaz que puede ser el codificado local con Claude Code y Ollama.
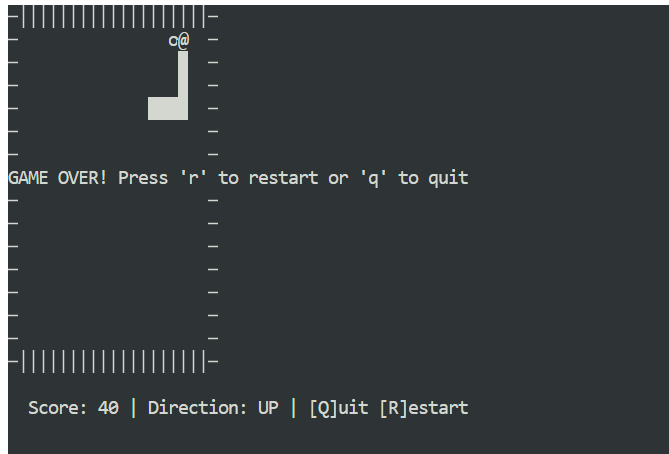
La ejecución de Claude Code con GLM 4.7 Flash en Ollama muestra lo lejos que ha llegado la codificación agencial local. Obtienes respuestas rápidas, una potente generación de código y un control total sobre tus datos, todo ello sin depender de modelos alojados en la nube.
Una vez configurado, el flujo de trabajo resulta fluido y fiable, incluso para tareas de codificación de varios pasos.
Una conclusión importante es que las ventanas de contexto más grandes y las configuraciones más complejas no siempre son mejores. Con los valores predeterminados razonables, la configuración completa tarda unos cinco minutos, sin contar el tiempo de descarga del modelo, que depende de tu conexión a Internet.
Si ya tienes descargado el archivo GGUF del modelo, la configuración será aún más rápida. En este caso, puedes omitir por completo la descarga del modelo y simplemente registrar el archivo GGUF existente con Ollama creando unarchivo de modelo .
Esto te permite definir los parámetros de generación una sola vez y reutilizar el modelo de forma coherente en todas las ejecuciones y herramientas.
Crea un archivo llamado Modelfile en el mismo directorio que tu archivo GGUF:
FROM ./glm-4.7-flash.gguf
PARAMETER temperature 0.8
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.0Puedes ajustar los parámetros según sea necesario:
Registra el modelo en Ollama:
ollama create glm-4.7-flash-local -f ModelfileUna vez creado el modelo, puedes ejecutarlo directamente en el modo de chat:
ollama run glm-4.7-flash-localAhora, el modelo se puede utilizar como cualquier otro modelo de Ollama e integrarse perfectamente con Claude Code.
Me lo pasé muy bien creando aplicaciones y juegos con GLM 4.7 Flash dentro de Claude Code. Realmente te hace sentir empoderado trabajar en un lugar remoto sin Internet o con una conexión inestable. Todo funciona localmente, nada falla y sigues teniendo un potente agente de codificación al alcance de la mano. Esa sensación de control e independencia es difícil de superar.
Si deseas obtener más información sobre las herramientas que hemos tratado en este artículo, te recomiendo los siguientes recursos:
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze

