
Courses
Thiết kế Hệ thống Agentic với LangChain
3 giờ
12.9K
GLM 4.7 Flash đang nhanh chóng trở thành lựa chọn phổ biến cho lập trình agentic cục bộ. Nhiều nhà phát triển đang dùng nó với các công cụ như llama.cpp và LM Studio. Tuy nhiên, nhiều người vẫn gặp vấn đề trong quá trình thiết lập, chạy mô hình đúng cách và đảm bảo việc gọi công cụ hoạt động như mong đợi.
Hướng dẫn này tập trung vào cách đơn giản và đáng tin cậy nhất để chạy GLM 4.7 Flash cục bộ bằng Claude Code với Ollama. Mục tiêu là loại bỏ rào cản và giúp bạn có một bản thiết lập hoạt động mà không phức tạp không cần thiết.
Hướng dẫn này dùng được trên mọi hệ điều hành. Không quan trọng bạn dùng Linux, Windows hay macOS. Kết thúc bài, bạn sẽ chạy GLM 4.7 Flash cục bộ và tích hợp đúng với Claude Code thông qua Ollama.
Trước khi bắt đầu, hãy đảm bảo hệ thống của bạn đáp ứng các yêu cầu phần cứng và phần mềm tối thiểu dưới đây.
Phần cứng:
Nếu bạn không có GPU, mô hình có thể chạy trên CPU, nhưng hiệu năng sẽ chậm hơn đáng kể và cần RAM cao.
Phần mềm:
Nếu thiếu bộ công cụ CUDA hoặc driver NVIDIA không tương thích, Ollama sẽ chuyển sang chế độ CPU, vốn chậm hơn rất nhiều.
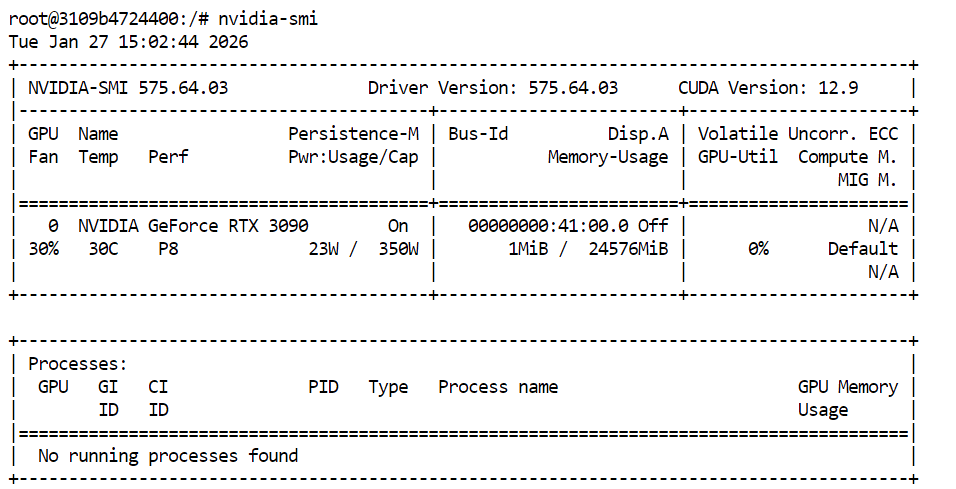
Để xác minh GPU và driver CUDA được cài đúng, hãy chạy lệnh sau trong terminal:
nvidia-smiNếu mọi thứ được thiết lập đúng, bạn sẽ thấy GPU của mình cùng VRAM khả dụng và phiên bản CUDA.
Ollama là môi trường chạy mà chúng ta sẽ dùng để chạy GLM 4.7 Flash cục bộ và phơi bày nó theo cách Claude Code có thể tương tác một cách đáng tin cậy. Việc cài đặt đơn giản trên tất cả nền tảng được hỗ trợ.
Trên Linux, bạn có thể cài Ollama với một lệnh:
curl -fsSL https://ollama.com/install.sh | shVới macOS và Windows, tải trình cài đặt trực tiếp từ trang web Ollama và làm theo hướng dẫn trên màn hình.

Nguồn: Ollama
Ollama chạy như một dịch vụ nền và sẽ tự động kiểm tra bản cập nhật. Khi có bản cập nhật, bạn có thể áp dụng bằng cách chọn “Khởi động lại để cập nhật” từ menu Ollama.
Sau khi cài đặt, mở terminal và kiểm tra Ollama được cài đúng chưa:
ollama -vBạn sẽ thấy đầu ra tương tự:
ollama version is 0.15.2Nếu bạn thấy lỗi khi chạy ollama -v, thường là do dịch vụ Ollama chưa chạy. Khởi động máy chủ Ollama thủ công:
ollama serveGiữ tiến trình này chạy, mở một cửa sổ terminal mới, rồi chạy:
ollama -vKhi lệnh kiểm tra phiên bản hoạt động, Ollama đã sẵn sàng cho các bước tiếp theo của hướng dẫn.
Khi Ollama đã được cài và chạy, bước tiếp theo là tải mô hình GLM 4.7 Flash và xác minh nó hoạt động đúng. Bước này đảm bảo mô hình chạy cục bộ trước khi tích hợp với Claude Code.
Nguồn: glm-4.7-flash
Bắt đầu bằng cách tải mô hình từ registry của Ollama:
ollama pull glm-4.7-flashLệnh này sẽ tải các tệp mô hình và lưu cục bộ. Tùy tốc độ mạng, có thể mất vài phút.
Sau khi tải xong, chạy mô hình ở chế độ chat tương tác như một phép thử nhanh:
ollama run glm-4.7-flashGõ một lời chào đơn giản rồi nhấn enter. Trong vài giây, bạn sẽ nhận được phản hồi.
Nếu bạn chạy trên GPU, bạn sẽ thấy phản hồi rất nhanh, và đầu ra có thể bao gồm các token suy nghĩ nội bộ hoặc dấu vết lập luận tùy cấu hình mô hình.

Bạn cũng có thể thử mô hình thông qua API HTTP cục bộ của Ollama. Điều này hữu ích để xác nhận công cụ bên ngoài có thể giao tiếp với mô hình.
Chạy lệnh sau:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role":"user","content":"Hello!"}]
}'Claude Code và hầu hết công cụ lập trình agentic hoạt động tốt nhất với cửa sổ ngữ cảnh lớn, thường lên tới 64k token. Tuy nhiên, với GLM 4.7 Flash, chọn độ dài ngữ cảnh phù hợp rất quan trọng cho cả hiệu năng và độ ổn định.
Dùng kích thước ngữ cảnh rất lớn có thể làm chậm đáng kể tốc độ sinh token. Trên thực tế, thông lượng token có thể giảm từ hơn 100 token/giây xuống chỉ còn khoảng 2 token/giây. Trong một số trường hợp, mô hình cũng có thể mắc kẹt trong các vòng suy nghĩ dài nếu cửa sổ ngữ cảnh đặt quá cao.
Chúng tôi đã thử nhiều kích thước ngữ cảnh và thấy rằng 10k là không đủ cho quy trình làm việc của Claude Code. 20k cho cân bằng tốt: đủ lớn cho tác vụ lập trình trong khi vẫn giữ tốc độ phản hồi nhanh và giảm các vòng suy nghĩ không cần thiết.
Trước tiên, dừng máy chủ Ollama đang chạy. Bạn có thể làm điều này bằng cách nhấn Ctrl + C trong terminal hoặc kết thúc tiến trình.
Tiếp theo, khởi động lại Ollama với độ dài ngữ cảnh tùy chỉnh bằng cách đặt biến môi trường trước khi chạy máy chủ:
OLLAMA_CONTEXT_LENGTH=20000 ollama serveĐiều này báo cho Ollama tải các mô hình với cửa sổ ngữ cảnh tối đa 20.000 token.
Trong một cửa sổ terminal mới, chạy:
ollama psĐiều này xác nhận GLM 4.7 Flash đang chạy trên GPU và độ dài ngữ cảnh đã được đặt đúng. Tại thời điểm này, mô hình đã được cấu hình để dùng với Claude Code một cách ổn định và nhanh.
NAME ID SIZE PROCESSOR CONTEXT UNTIL
glm-4.7-flash:latest d1a8a26252f1 21 GB 100% GPU 20000 About a minute from now Claude Code là tác nhân lập trình dựa trên terminal của Anthropic, giúp bạn viết, chỉnh sửa, tái cấu trúc và hiểu mã bằng ngôn ngữ tự nhiên. Nó được xây dựng cho quy trình agentic và có thể xử lý các tác vụ lập trình nhiều bước trực tiếp từ dòng lệnh của bạn.
Kết hợp với Ollama, Claude Code có thể dễ dàng dùng với các mô hình cục bộ như GLM 4.7 Flash, cho phép bạn chạy mọi thứ cục bộ và giữ mã nguồn trên máy của mình.
Trên macOS, Linux hoặc Windows dùng WSL, cài Claude Code bằng script cài đặt chính thức:
curl -fsSL https://claude.ai/install.sh | bashLệnh này tải và cài Claude Code cùng các phụ thuộc cần thiết. Sau khi cài xong, lệnh claude sẽ khả dụng trong terminal của bạn.
Giờ khi cả Ollama và Claude Code đã được cài, bước tiếp theo là kết nối Claude Code với máy chủ Ollama cục bộ và cấu hình để dùng mô hình GLM 4.7 Flash.
Bắt đầu bằng cách tạo thư mục làm việc cho dự án. Đây là nơi Claude Code sẽ hoạt động và quản lý tệp:
mkdir <project-name>
cd <project-name>Ollama hiện cung cấp cách tích hợp sẵn để khởi chạy Claude Code, tự động cấu hình để trò chuyện với runtime Ollama cục bộ. Đây là cách được khuyến nghị và đáng tin cậy nhất.
Để khởi chạy Claude Code tương tác bằng Ollama:
ollama launch claudeĐể khởi chạy trực tiếp Claude Code với mô hình GLM 4.7 Flash, chạy:
ollama launch claude --model glm-4.7-flashĐiều này đảm bảo Claude Code dùng mô hình GLM 4.7 Flash cục bộ thay vì mô hình từ xa hay mặc định.
Khi mọi thứ đã thiết lập xong, bạn sẽ thấy giao diện Claude Code trực tiếp trong terminal.
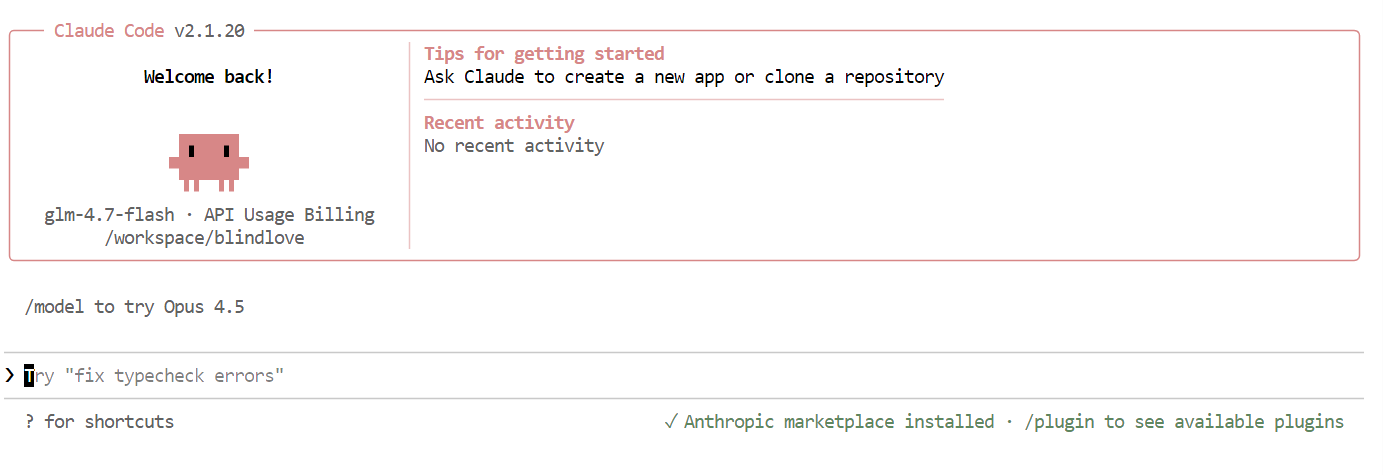
Trong Claude Code, dùng lệnh sau để xác nhận nó đang dùng mô hình cục bộ:
/modelNếu đầu ra hiển thị glm-4.7-flash, cấu hình của bạn đã hoàn tất và Claude Code đang chạy thành công trên mô hình Ollama cục bộ.
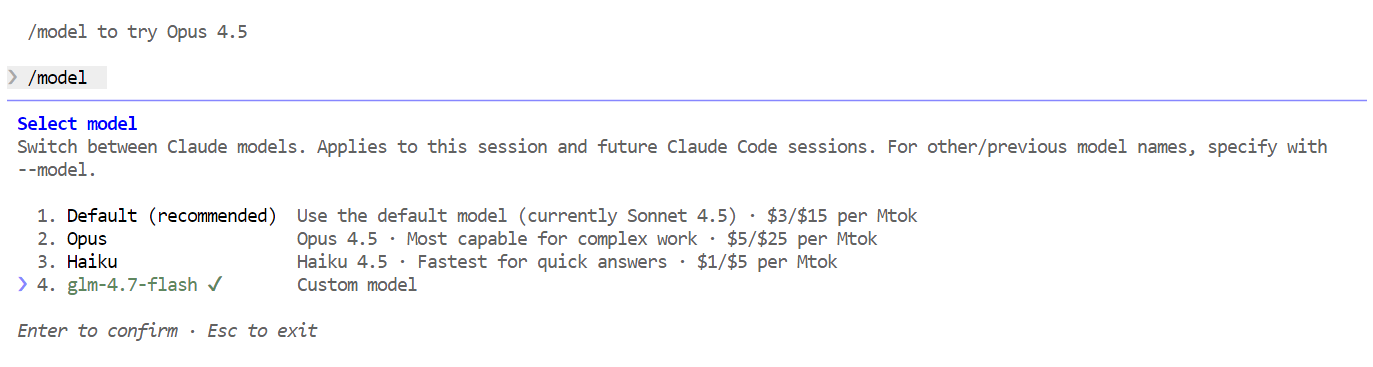
Khi đã thiết lập xong, bạn có thể bắt đầu dùng Claude Code được vận hành bởi mô hình GLM 4.7 Flash cục bộ. Việc đầu tiên nên thử là một lời chào đơn giản. Trong khoảng một hai giây, bạn sẽ nhận được phản hồi. Tốc độ rất đáng chú ý, đặc biệt khi chạy trên GPU.
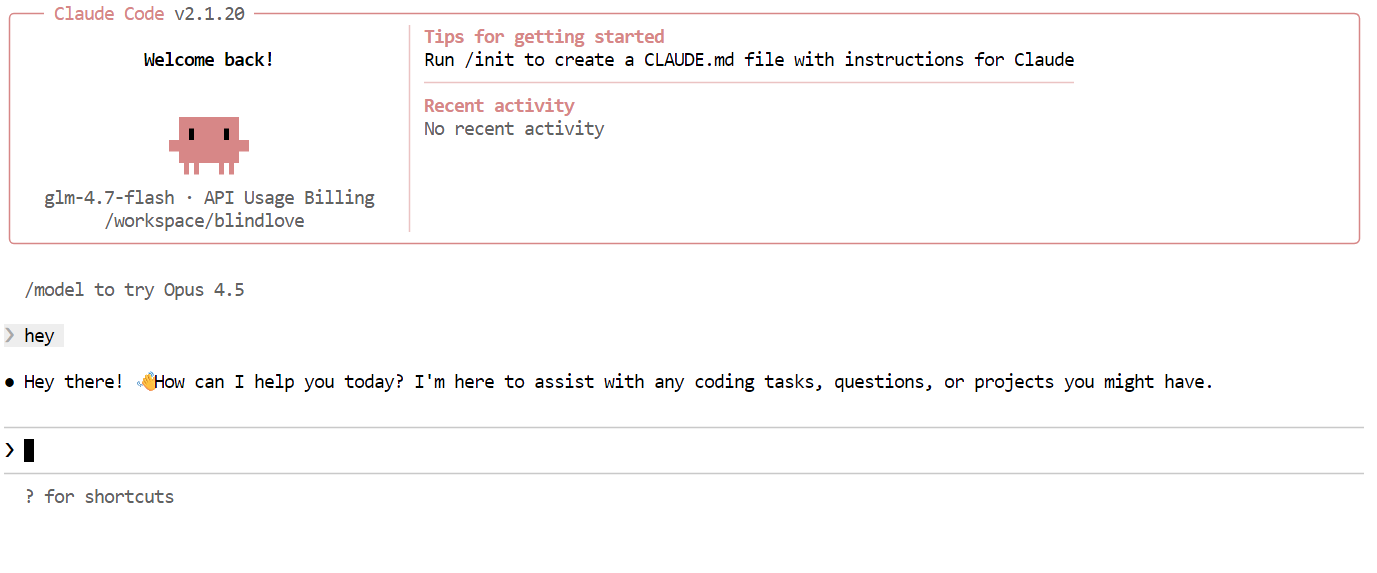
Tiếp theo, thử một tác vụ lập trình thực tế hơn. Yêu cầu Claude Code xây dựng trò chơi Rắn săn mồi (Snake) dạng CLI bằng Python. Trước khi sinh mã, chuyển sang chế độ lập kế hoạch để mô hình phác thảo cách tiếp cận trước. Bạn có thể bật chế độ lập kế hoạch bằng cách nhấn Shift + Tab hai lần.
 Khi kế hoạch được tạo, hãy xem lại. Nếu cách tiếp cận ổn, yêu cầu Claude Code thực thi kế hoạch.
Khi kế hoạch được tạo, hãy xem lại. Nếu cách tiếp cận ổn, yêu cầu Claude Code thực thi kế hoạch.
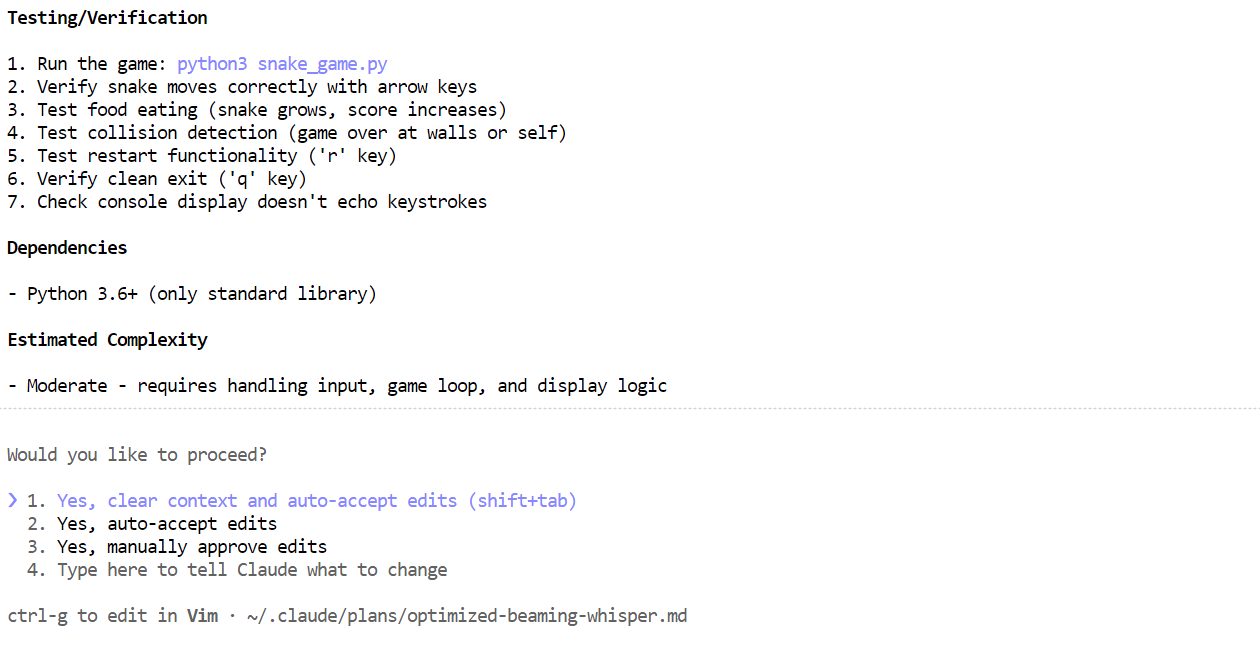 Trong vài phút, nó đã tạo các tệp cần thiết, giải thích trò chơi Snake làm gì và cung cấp hướng dẫn rõ ràng về cách chạy.
Trong vài phút, nó đã tạo các tệp cần thiết, giải thích trò chơi Snake làm gì và cung cấp hướng dẫn rõ ràng về cách chạy.
 Mở một cửa sổ terminal mới và đảm bảo bạn đang ở cùng thư mục dự án. Sau đó khởi động trò chơi với:
Mở một cửa sổ terminal mới và đảm bảo bạn đang ở cùng thư mục dự án. Sau đó khởi động trò chơi với:
python3 snake_game.pyTrò chơi chạy ngay không cần thiết lập thêm. Đây là trò Snake trên terminal đơn giản, rất giống phiên bản trên Nokia 3310 cổ điển. Dù đơn giản, nó là ví dụ tuyệt vời cho việc lập trình agentic cục bộ nhanh và hiệu quả với Claude Code và Ollama.
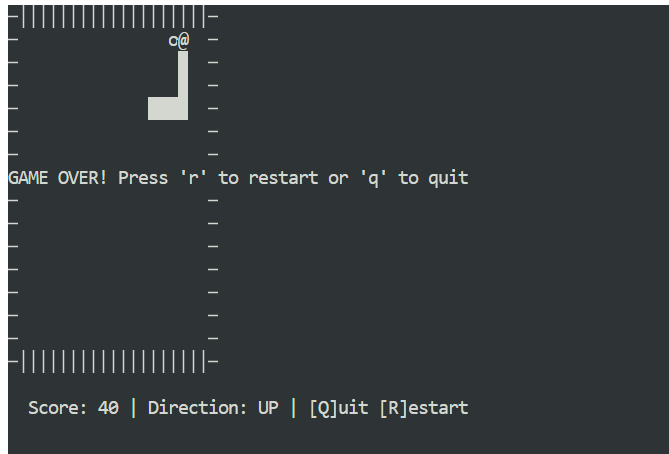
Chạy Claude Code với GLM 4.7 Flash trên Ollama cho thấy lập trình agentic cục bộ đã tiến xa thế nào. Bạn nhận được phản hồi nhanh, khả năng sinh mã mạnh mẽ và toàn quyền kiểm soát dữ liệu, tất cả mà không cần dựa vào mô hình lưu trữ trên đám mây.
Khi đã cấu hình xong, quy trình làm việc mượt mà và đáng tin cậy, kể cả với các tác vụ lập trình nhiều bước.
Điều rút ra quan trọng là cửa sổ ngữ cảnh lớn hơn và thiết lập phức tạp hơn không phải lúc nào cũng tốt hơn. Với các giá trị mặc định hợp lý, toàn bộ thiết lập mất khoảng năm phút, không tính thời gian tải mô hình (phụ thuộc vào kết nối internet của bạn).
Nếu bạn đã có tệp GGUF của mô hình, thiết lập còn nhanh hơn. Trong trường hợp này, bạn có thể bỏ qua việc tải mô hình và chỉ cần đăng ký tệp GGUF hiện có với Ollama bằng cách tạo một Modelfile.
Điều này cho phép bạn định nghĩa tham số sinh một lần và tái sử dụng mô hình nhất quán trong các lần chạy và công cụ khác nhau.
Tạo tệp tên Modelfile trong cùng thư mục với tệp GGUF của bạn:
FROM ./glm-4.7-flash.gguf
PARAMETER temperature 0.8
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.0Bạn có thể điều chỉnh các tham số khi cần:
Đăng ký mô hình với Ollama:
ollama create glm-4.7-flash-local -f ModelfileKhi mô hình đã được tạo, bạn có thể chạy nó trực tiếp ở chế độ chat:
ollama run glm-4.7-flash-localGiờ đây mô hình có thể dùng như bất kỳ mô hình Ollama nào khác và tích hợp liền mạch với Claude Code.
Tôi đã có rất nhiều niềm vui khi xây dựng ứng dụng và trò chơi bằng GLM 4.7 Flash trong Claude Code. Thực sự cảm giác rất “đã” khi làm việc ở nơi xa xôi không có internet hoặc kết nối chập chờn. Mọi thứ chạy cục bộ, không bị gián đoạn, và bạn vẫn có một tác nhân lập trình mạnh mẽ ngay trong tầm tay. Cảm giác kiểm soát và độc lập đó thật khó sánh được.
Nếu bạn muốn tìm hiểu thêm về các công cụ được đề cập trong bài, tôi khuyến nghị các tài nguyên sau:
Khóa học hàng đầu trên DataCamp
Courses
Courses
Courses