
Cursus
Agentic Systems ontwerpen met LangChain
3 Hr
12.9K
GLM 4.7 Flash wordt snel een populaire keuze voor lokaal agentisch coden. Veel ontwikkelaars gebruiken het met tools zoals llama.cpp en LM Studio. Toch lopen veel mensen nog tegen problemen aan bij de installatie, het model correct laten draaien en ervoor zorgen dat tool-calls werken zoals verwacht.
Deze tutorial richt zich op de eenvoudigste en meest betrouwbare manier om GLM 4.7 Flash lokaal te draaien met Claude Code en Ollama. Het doel is om wrijving weg te nemen en je zonder onnodige complexiteit een werkende setup te geven.
Deze gids werkt op alle besturingssystemen. Het maakt niet uit of je Linux, Windows of macOS gebruikt. Aan het einde heb je GLM 4.7 Flash lokaal draaien en correct geïntegreerd met Claude Code via Ollama.
Zorg voordat je begint dat je systeem aan de minimale hardware- en softwarevereisten hieronder voldoet.
Hardware:
Als je geen GPU hebt, kan het model op een CPU draaien, maar de prestaties zijn aanzienlijk trager en er is veel RAM nodig.
Software:
Als de CUDA-toolkit of NVIDIA-drivers ontbreken of incompatibel zijn, schakelt Ollama over naar CPU-modus, wat veel trager is.
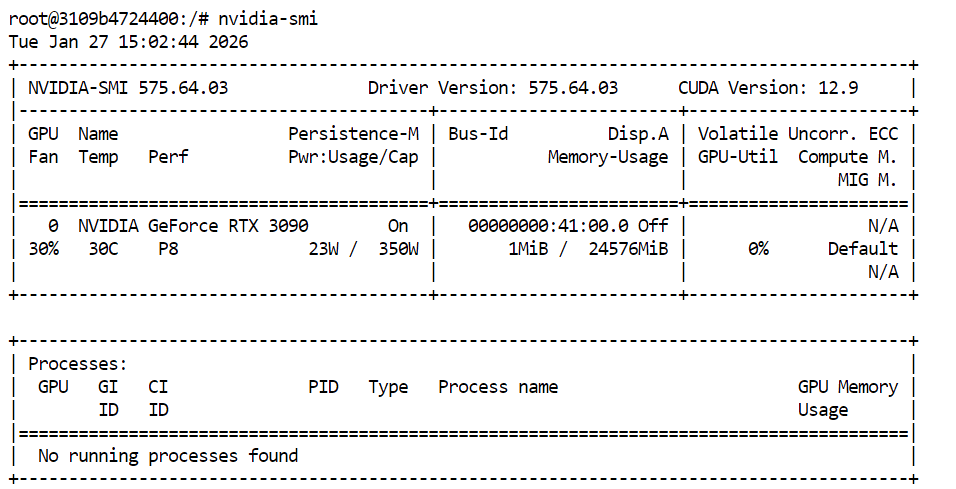
Om te verifiëren dat je GPU en CUDA-drivers correct zijn geïnstalleerd, voer je de volgende opdracht uit in je terminal:
nvidia-smiAls alles goed is ingesteld, zie je je GPU vermeld, samen met de beschikbare VRAM en CUDA-versie.
Ollama is de runtime die we gebruiken om GLM 4.7 Flash lokaal te draaien en het zo aan te bieden dat Claude Code er betrouwbaar mee kan communiceren. Installatie is eenvoudig op alle ondersteunde platforms.
Op Linux kun je Ollama installeren met één opdracht:
curl -fsSL https://ollama.com/install.sh | shVoor macOS en Windows download je de installer rechtstreeks van de Ollama-website en volg je de instructies op het scherm.

Bron: Ollama
Ollama draait als een achtergrondservice en controleert automatisch op updates. Wanneer er een update beschikbaar is, kun je die toepassen door in het Ollama-menu "Opnieuw starten om te updaten" te selecteren.
Open na de installatie een terminal en controleer of Ollama correct is geïnstalleerd:
ollama -vJe zou uitvoer moeten zien zoals:
ollama version is 0.15.2Als je een fout ziet bij het uitvoeren van ollama -v, betekent dit meestal dat de Ollama-service nog niet draait. Start de Ollama-server handmatig:
ollama serveLaat dit draaien, open een nieuw terminalvenster en voer vervolgens uit:
ollama -vZodra de versie-opdracht werkt, is Ollama klaar voor gebruik in de volgende stappen van de tutorial.
Zodra Ollama is geïnstalleerd en draait, is de volgende stap het downloaden van het GLM 4.7 Flash-model en controleren of het correct werkt. Deze stap zorgt ervoor dat het model lokaal draait voordat je het met Claude Code integreert.
Bron: glm-4.7-flash
Begin met het downloaden van het model uit het register van Ollama:
ollama pull glm-4.7-flashDit downloadt de modelfiles en slaat ze lokaal op. Afhankelijk van je internetsnelheid kan dit enkele minuten duren.
Na het voltooien van de download, voer je het model uit in interactieve chatmodus als snelle sanity check:
ollama run glm-4.7-flashTyp een eenvoudige prompt, zoals een begroeting, en druk op enter. Binnen enkele seconden zou je een reactie moeten krijgen.
Als je op een GPU draait, merk je dat reacties erg snel zijn en dat de output afhankelijk van de modelconfiguratie interne denktokens of redeneertraces kan bevatten.

Je kunt het model ook testen via de lokale HTTP-API van Ollama. Dit is handig om te bevestigen dat externe tools met het model kunnen communiceren.
Voer de volgende opdracht uit:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role":"user","content":"Hello!"}]
}'Claude Code en de meeste agentische codingtools werken het best met grote contextvensters, vaak tot 64k tokens. Met GLM 4.7 Flash is het echter belangrijk om de juiste contextlengte te kiezen voor zowel prestaties als stabiliteit.
Zeer grote contextgroottes kunnen de generatiesnelheid aanzienlijk vertragen. In de praktijk kan de token-throughput dalen van meer dan 100 tokens per seconde tot slechts 2 tokens per seconde. In sommige gevallen kan het model ook vastlopen in lange denkloops als het contextvenster te hoog is ingesteld.
We hebben meerdere contextgroottes getest en ontdekten dat een context van 10k niet voldoende was voor Claude Code-workflows. Een context van 20k bood een goede balans. Die was groot genoeg voor codetaken, met behoud van snelle responstijden en minder onnodige denkloops.
Stop eerst de draaiende Ollama-server. Dit kan door in de terminal op Ctrl + C te drukken of het proces te beëindigen.
Start daarna Ollama opnieuw met een aangepaste contextlengte door de omgevingsvariabele in te stellen voordat je de server start:
OLLAMA_CONTEXT_LENGTH=20000 ollama serveDit vertelt Ollama om modellen te laden met een maximaal contextvenster van 20.000 tokens.
Voer in een nieuw terminalvenster uit:
ollama psDit bevestigt dat GLM 4.7 Flash op de GPU draait en dat de contextlengte correct is ingesteld. Op dit punt is het model geconfigureerd voor stabiel en snel gebruik met Claude Code.
NAME ID SIZE PROCESSOR CONTEXT UNTIL
glm-4.7-flash:latest d1a8a26252f1 21 GB 100% GPU 20000 About a minute from now Claude Code is Anthropics terminalgebaseerde codeagent die je helpt code te schrijven, bewerken, refactoren en begrijpen in natuurlijke taal. Het is gebouwd voor agentische workflows en kan meerstaps codetaken rechtstreeks vanaf je command line uitvoeren.
In combinatie met Ollama kun je Claude Code eenvoudig gebruiken met lokale modellen zoals GLM 4.7 Flash, zodat je alles lokaal draait en je code op je eigen machine blijft.
Op macOS, Linux of Windows met WSL installeer je Claude Code met het officiële installatiescript:
curl -fsSL https://claude.ai/install.sh | bashDeze opdracht downloadt en installeert Claude Code samen met de vereiste afhankelijkheden. Zodra de installatie is voltooid, is het claude-commando beschikbaar in je terminal.
Nu zowel Ollama als Claude Code geïnstalleerd zijn, is de volgende stap om Claude Code te verbinden met je lokale Ollama-server en te configureren om het GLM 4.7 Flash-model te gebruiken.
Begin met het aanmaken van een werkmap voor je project. Dit is waar Claude Code zal werken en bestanden beheert:
mkdir <project-name>
cd <project-name>Ollama biedt nu een ingebouwde manier om Claude Code te starten die het automatisch configureert om met de lokale Ollama-runtime te praten. Dit is de aanbevolen en meest betrouwbare aanpak.
Om Claude Code interactief te starten met Ollama:
ollama launch claudeOm Claude Code direct te starten met het GLM 4.7 Flash-model, voer je uit:
ollama launch claude --model glm-4.7-flashDit zorgt ervoor dat Claude Code je lokale GLM 4.7 Flash-model gebruikt in plaats van een extern of standaardmodel.
Zodra alles is ingesteld, zie je de interface van Claude Code direct in je terminal.
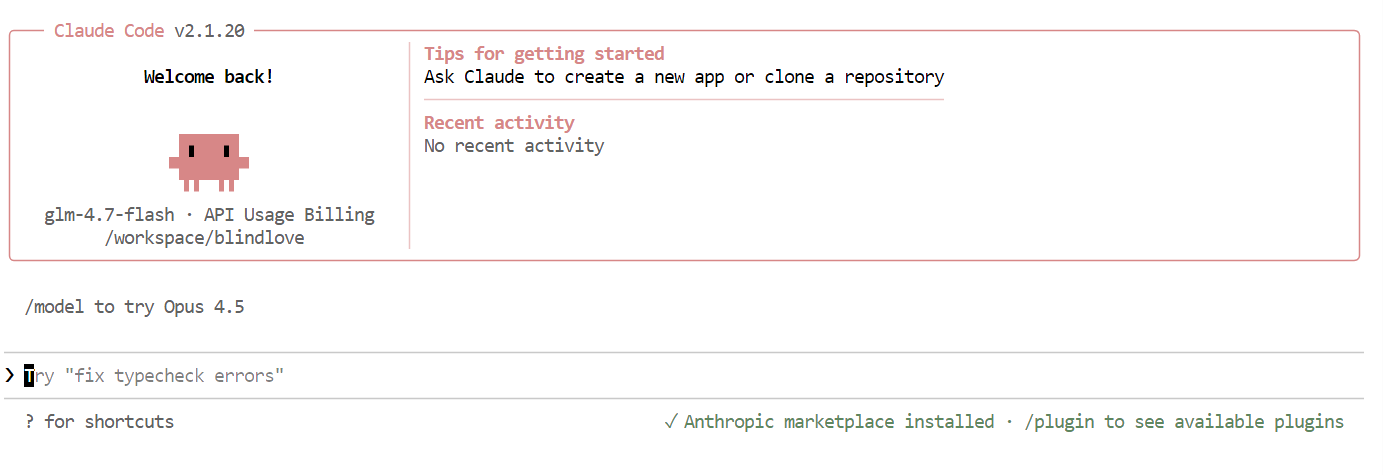
Gebruik binnen Claude Code het volgende commando om te bevestigen dat je lokale model wordt gebruikt:
/modelAls de output glm-4.7-flash toont, is je setup compleet en draait Claude Code succesvol op je lokale Ollama-model.
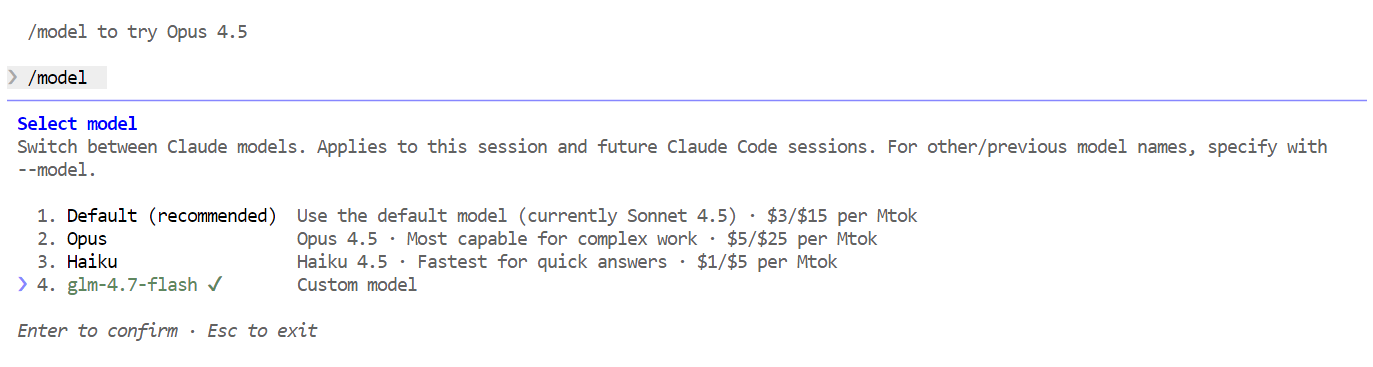
Nu alles is ingesteld, kun je Claude Code gebruiken, aangedreven door je lokale GLM 4.7 Flash-model. Probeer eerst een simpele begroeting. Binnen een seconde of twee zou je een reactie moeten krijgen. De snelheid is duidelijk merkbaar, vooral op een GPU.
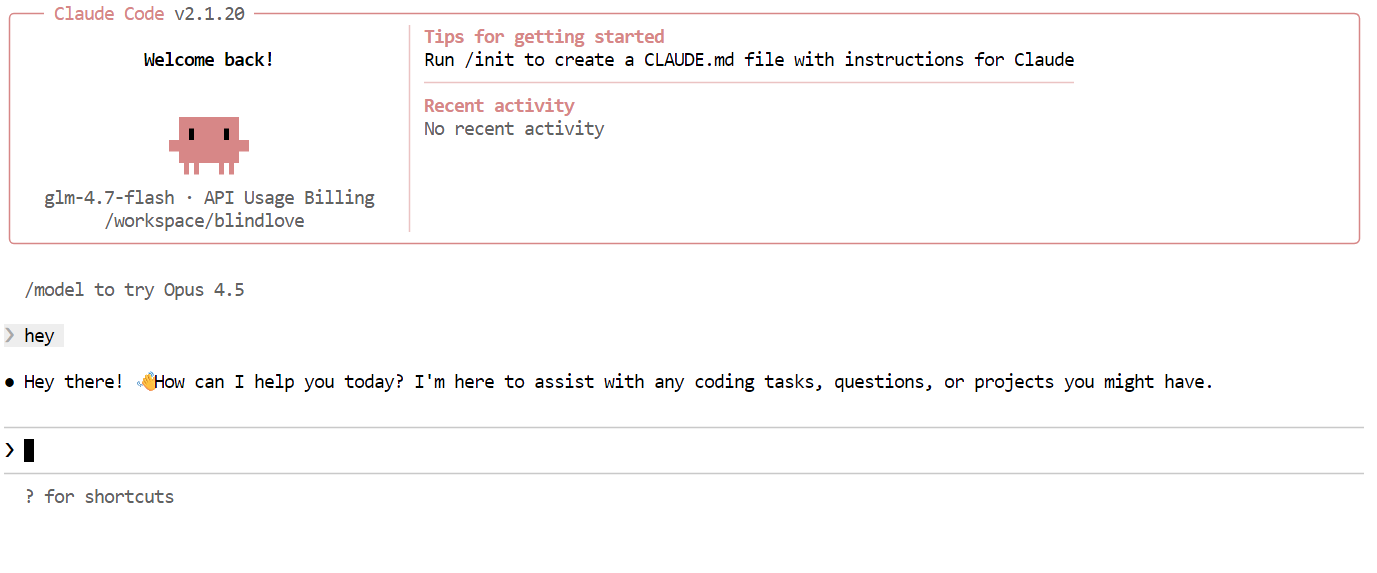
Probeer daarna een realistischer codetask. Vraag Claude Code om een CLI Snake-game in Python te bouwen. Schakel voor het genereren van code eerst over naar de planningsmodus zodat het model zijn aanpak schetst. Je schakelt de planningsmodus in door Shift + Tab twee keer in te drukken.
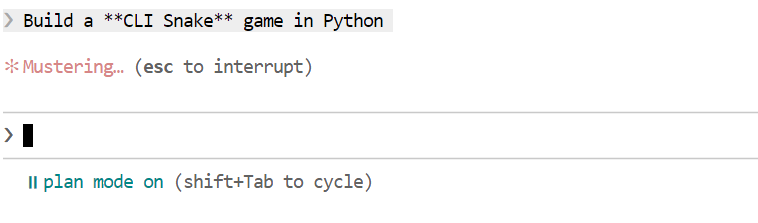 Zodra het plan is gegenereerd, bekijk je het. Als de aanpak goed lijkt, vraag Claude Code dan het plan uit te voeren.
Zodra het plan is gegenereerd, bekijk je het. Als de aanpak goed lijkt, vraag Claude Code dan het plan uit te voeren.
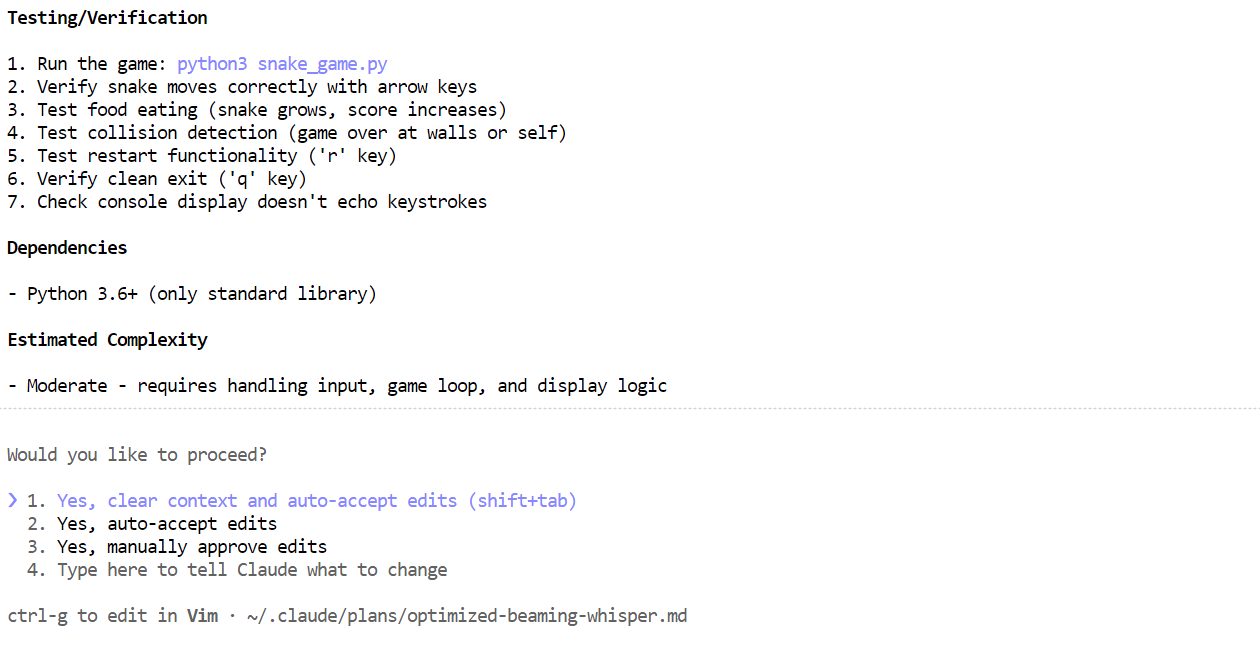 Binnen een paar minuten zijn de benodigde bestanden aangemaakt, is uitgelegd wat de Snake-game doet en zijn duidelijke instructies gegeven om het te draaien.
Binnen een paar minuten zijn de benodigde bestanden aangemaakt, is uitgelegd wat de Snake-game doet en zijn duidelijke instructies gegeven om het te draaien.
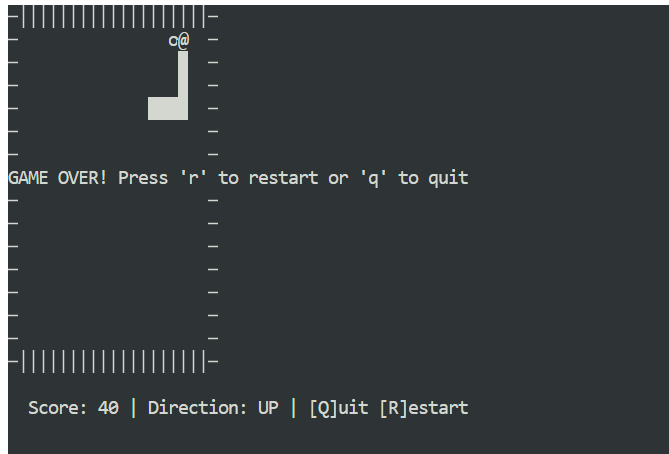
 Open een nieuw terminalvenster en zorg dat je in dezelfde projectmap zit. Start vervolgens de game met:
Open een nieuw terminalvenster en zorg dat je in dezelfde projectmap zit. Start vervolgens de game met:
python3 snake_game.pyDe game draait out-of-the-box zonder extra setup. Het is een eenvoudige, terminalgebaseerde Snake-game, erg vergelijkbaar met de klassieke Nokia 3310-versie. Ondanks de eenvoud is het een goed voorbeeld van hoe snel en effectief lokaal agentisch coden kan zijn met Claude Code en Ollama.
Claude Code draaien met GLM 4.7 Flash op Ollama laat zien hoe ver lokaal agentisch coden is gekomen. Je krijgt snelle reacties, sterke codegeneratie en volledige controle over je data, allemaal zonder afhankelijk te zijn van cloudmodellen.
Eenmaal geconfigureerd voelt de workflow soepel en betrouwbaar, zelfs voor meerstaps codetaken.
Een belangrijke les is dat grotere contextvensters en complexere setups niet altijd beter zijn. Met verstandige defaults duurt de hele setup ongeveer vijf minuten, exclusief de tijd voor het downloaden van het model, wat afhangt van je internetverbinding.
Als je het GGUF-bestand voor het model al hebt gedownload, gaat de setup nog sneller. In dat geval kun je het downloaden van het model helemaal overslaan en het bestaande GGUF-bestand simpelweg registreren bij Ollama door een Modelfile te maken.
Hiermee definieer je de generatieparameters één keer en kun je het model consistent hergebruiken over runs en tools heen.
Maak een bestand met de naam Modelfile in dezelfde map als je GGUF-bestand:
FROM ./glm-4.7-flash.gguf
PARAMETER temperature 0.8
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.0Je kunt de parameters naar wens aanpassen:
Registreer het model bij Ollama:
ollama create glm-4.7-flash-local -f ModelfileZodra het model is aangemaakt, kun je het direct in chatmodus draaien:
ollama run glm-4.7-flash-localHet model kan nu worden gebruikt zoals elk ander Ollama-model en naadloos worden geïntegreerd met Claude Code.
Ik heb veel plezier gehad met het bouwen van apps en games met GLM 4.7 Flash in Claude Code. Het voelt oprecht krachtig om op een afgelegen plek te werken zonder internet of met instabiele verbinding. Alles draait lokaal, niets valt uit, en je hebt toch een krachtige codeagent binnen handbereik. Dat gevoel van controle en onafhankelijkheid is moeilijk te overtreffen.
Als je meer wilt leren over de tools die we in dit artikel hebben behandeld, raad ik de volgende resources aan:
Topcursussen op DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
