
Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.1K
GLM 4.7 Flash est en train de devenir rapidement un choix populaire pour le codage agentique local. De nombreux développeurs l'utilisent avec des outils tels que llama.cpp et LM Studio. Cependant, de nombreuses personnes rencontrent encore des difficultés lors de la configuration, pour faire fonctionner correctement le modèle et s'assurer que l'appel des outils fonctionne comme prévu.
Ce tutoriel se concentre sur la méthode la plus simple et la plus fiable pour exécuter GLM 4.7 Flash localement à l'aide de Claude Code avec Ollama. L'objectif est d'éliminer les frictions et de vous aider à obtenir une configuration fonctionnelle sans complexité inutile.
Ce guide est applicable à tous les systèmes d'exploitation. Peu importe que vous utilisiez Linux, Windows ou macOS. À la fin, vous disposerez de GLM 4.7 Flash fonctionnant localement et correctement intégré à Claude Code via Ollama.
Avant de commencer, veuillez vous assurer que votre système répond aux exigences matérielles et logicielles minimales indiquées ci-dessous.
Matériel :
Si vous ne disposez pas d'un GPU, le modèle peut fonctionner sur un CPU, mais les performances seront considérablement ralenties et une mémoire RAM importante sera nécessaire.
Logiciel :
Si le kit d'outils CUDA ou les pilotes NVIDIA sont manquants ou incompatibles, Ollama passera en mode CPU, qui est beaucoup plus lent.
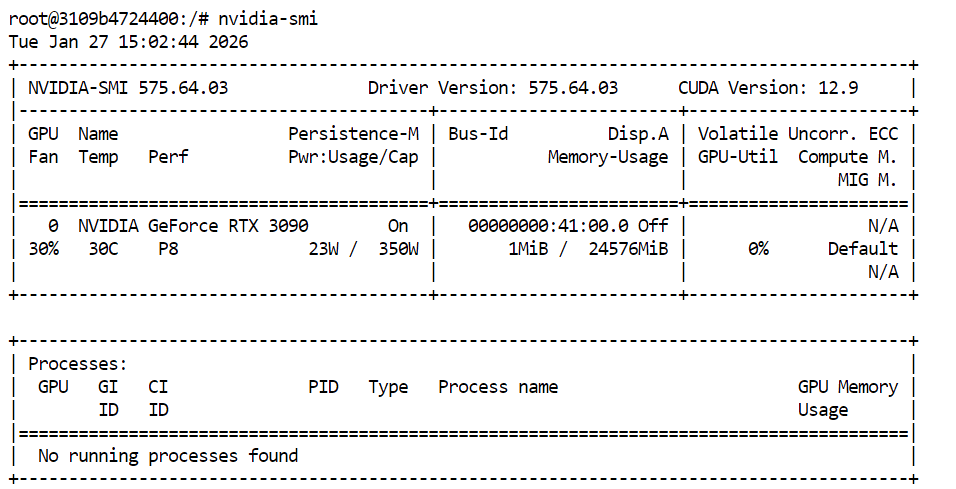
Pour vérifier que vos pilotes GPU et CUDA sont correctement installés, veuillez exécuter la commande suivante dans votre terminal :
nvidia-smiSi tout est correctement configuré, vous devriez voir votre GPU répertorié avec la VRAM disponible et la version CUDA.
Ollama est le moteur d'exécution que nous utiliserons pour exécuter GLM 4.7 Flash localement et l'exposer de manière à ce que Claude Code puisse interagir de manière fiable. L'installation est simple sur toutes les plateformes prises en charge.
Sous Linux, vous pouvez installer Ollama à l'aide d'une seule commande :
curl -fsSL https://ollama.com/install.sh | shPour macOS et Windows, veuillez télécharger le programme d'installation directement depuis le site site web d'Ollama et suivez les instructions à l'écran.

Source : Ollama
Ollama fonctionne en tant que service en arrière-plan et vérifie automatiquement les mises à jour. Lorsqu'une mise à jour est disponible, vous pouvez l'appliquer en sélectionnant « Redémarrer pour mettre à jour » dans le menu Ollama.
Après l'installation, veuillez ouvrir un terminal et vérifier que Ollama est correctement installé :
ollama -vVous devriez obtenir un résultat similaire à celui-ci :
ollama version is 0.15.2Si vous rencontrez une erreur lors de l'exécution de ollama -v, cela signifie généralement que le service Ollama n'est pas encore opérationnel. Veuillez démarrer le serveur Ollama manuellement :
ollama serveVeuillez laisser cela en cours d'exécution, ouvrez une nouvelle fenêtre de terminal, puis exécutez :
ollama -vUne fois que la commande version fonctionne, Ollama est prêt à être utilisé dans les étapes suivantes du tutoriel.
Une fois Ollama installé et opérationnel, l'étape suivante consiste à télécharger le modèle Flash GLM 4.7 et à vérifier qu'il fonctionne correctement. Cette étape garantit que le modèle fonctionne localement avant de l'intégrer à Claude Code.
Source : glm-4.7-flash
Veuillez commencer par télécharger le modèle à partir du registre Ollama :
ollama pull glm-4.7-flashCela permettra de télécharger les fichiers du modèle et de les enregistrer localement. En fonction de votre débit Internet, cela peut prendre quelques minutes.
Une fois le téléchargement terminé, veuillez exécuter le modèle en mode de discussion interactive afin de procéder à une vérification rapide :
ollama run glm-4.7-flashVeuillez saisir une invite simple, telle qu'une salutation, puis appuyez sur Entrée. Dans quelques instants, vous devriez recevoir une réponse.
Si vous utilisez un GPU, vous constaterez que les réponses sont très rapides et que le résultat peut inclure des jetons de réflexion internes ou des traces de raisonnement, selon la configuration du modèle.

Vous pouvez également tester le modèle via l'API HTTP locale d'Ollama. Ceci est utile pour vérifier que les outils externes peuvent communiquer avec le modèle.
Veuillez exécuter la commande suivante :
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role":"user","content":"Hello!"}]
}'Claude Code et la plupart des outils de codage agentique fonctionnent mieux avec des fenêtres contextuelles de grande taille, pouvant souvent atteindre 64 000 tokens. Cependant, avec GLM 4.7 Flash, il est essentiel de choisir la bonne longueur de contexte pour garantir à la fois performances et stabilité.
L'utilisation de contextes de très grande taille peut considérablement ralentir la vitesse de génération. En pratique, le débit des jetons peut passer de plus de 100 jetons par seconde à seulement 2 jetons par seconde. Dans certains cas, le modèle peut également se retrouver bloqué dans de longues boucles de réflexion si la fenêtre contextuelle est réglée à une valeur trop élevée.
Nous avons évalué plusieurs tailles de contexte et avons constaté qu'un contexte de 10 000 mots n'était pas suffisant pour les flux de travail Claude Code. Un contexte de 20 000 mots a permis d'atteindre un bon équilibre. Il était suffisamment spacieux pour les tâches de codage tout en conservant des temps de réponse rapides et en réduisant les boucles de réflexion inutiles.
Tout d'abord, veuillez arrêter le serveur Ollama en cours d'exécution. Vous pouvez procéder en saisissant la commande « Ctrl + C » dans le terminal ou en arrêtant le processus.
Ensuite, veuillez redémarrer Ollama avec une longueur de contexte personnalisée en définissant la variable d'environnement avant de lancer le serveur :
OLLAMA_CONTEXT_LENGTH=20000 ollama serveCela indique à Ollama de charger des modèles avec une fenêtre contextuelle maximale de 20 000 jetons.
Dans une nouvelle fenêtre de terminal, veuillez exécuter :
ollama psCela confirme que GLM 4.7 Flash fonctionne sur le GPU et que la longueur du contexte a été correctement définie. À ce stade, le modèle est configuré pour une utilisation stable et rapide avec Claude Code.
NAME ID SIZE PROCESSOR CONTEXT UNTIL
glm-4.7-flash:latest d1a8a26252f1 21 GB 100% GPU 20000 About a minute from now Claude Code est l'agent de codage basé sur terminal d'Anthropic qui vous assiste dans la rédaction, la modification, la refactorisation et la compréhension du code à l'aide du langage naturel. Il est conçu pour les flux de travail agentique et peut gérer des tâches de codage en plusieurs étapes directement à partir de votre ligne de commande.
Lorsqu'il est associé à Ollama, Claude Code peut être facilement utilisé avec des modèles locaux tels que GLM 4.7 Flash, ce qui vous permet d'exécuter toutes les opérations localement et de conserver votre code sur votre machine.
Sur macOS, Linux ou Windows utilisant WSL, veuillez installer Claude Code à l'aide du script d'installation officiel :
curl -fsSL https://claude.ai/install.sh | bashCette commande télécharge et installe Claude Code ainsi que les dépendances requises. Une fois l'installation terminée, la commande claude sera disponible dans votre terminal.
Maintenant que Ollama et Claude Code sont installés, l'étape suivante consiste à connecter Claude Code à votre serveur Ollama local et à le configurer pour utiliser le modèle GLM 4.7 Flash.
Commencez par créer un répertoire de travail pour votre projet. C'est ici que Claude Code fonctionnera et gérera les fichiers :
mkdir <project-name>
cd <project-name>Ollama propose désormais une fonctionnalité intégrée permettant de lancer Claude Code, qui se configure automatiquement pour communiquer avec le runtime Ollama local. Il s'agit de l'approche recommandée et la plus fiable.
Pour lancer Claude Code de manière interactive à l'aide d'Ollama :
ollama launch claudePour démarrer directement Claude Code à l'aide du modèle GLM 4.7 Flash, veuillez exécuter :
ollama launch claude --model glm-4.7-flashCela garantit que Claude Code utilise votre modèle Flash GLM 4.7 local au lieu d'un modèle distant ou par défaut.
Une fois que tout est configuré, l'interface Claude Code s'affichera directement dans votre terminal.
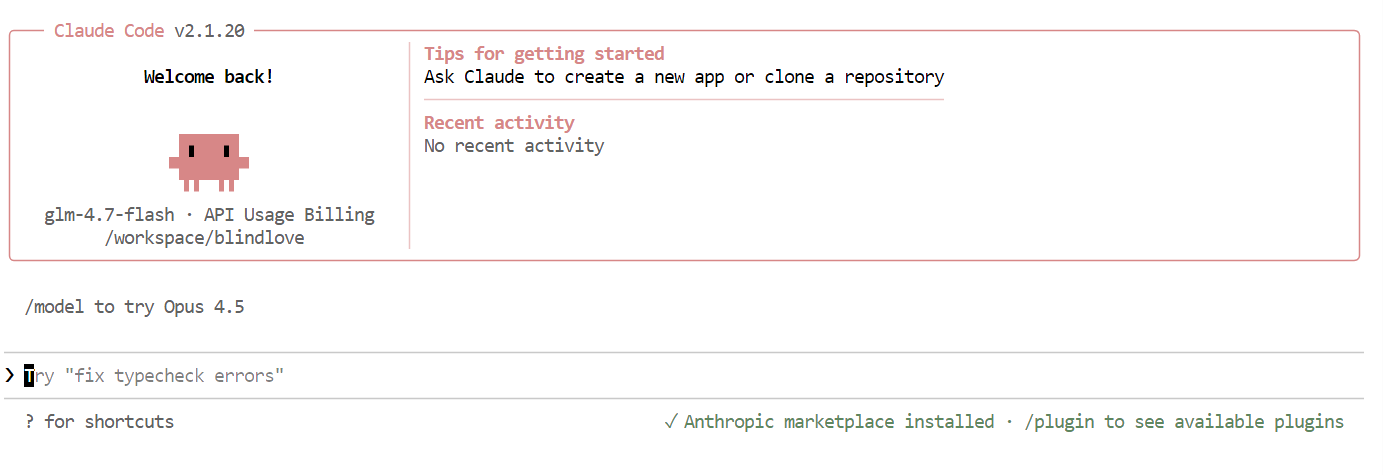
Dans Claude Code, veuillez utiliser la commande suivante pour vérifier que le modèle local est bien utilisé :
/modelSi le résultat affiche « glm-4.7-flash », votre configuration est terminée et Claude Code fonctionne correctement sur votre modèle Ollama local.
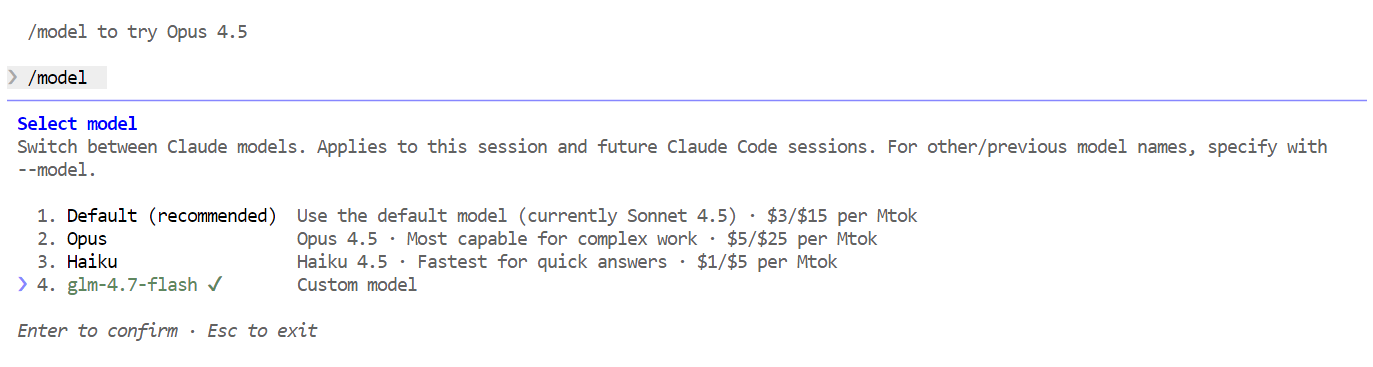
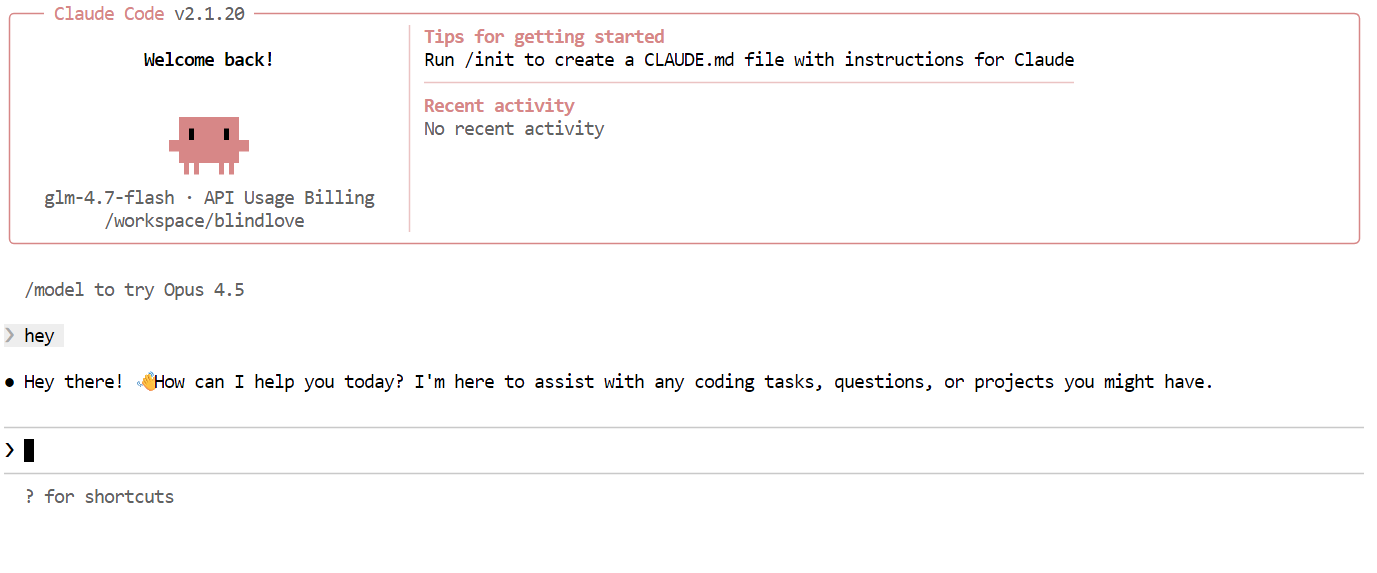
Une fois tout configuré, vous pouvez désormais commencer à utiliser Claude Code, optimisé par votre modèle Flash GLM 4.7 local. La première chose à essayer est une simple salutation. En l'espace d'une ou deux secondes, vous devriez recevoir une réponse. La vitesse est remarquablement rapide, en particulier lors de l'exécution sur un GPU.
Ensuite, essayez une tâche de codage plus réaliste. Veuillez demander à Claude Code de développer un jeu Snake en Python avec une interface CLI. Avant de générer le code, veuillez passer en mode planification afin que le modèle définisse d'abord son approche. Vous pouvez activer ou désactiver le mode planification en appuyant deux fois sur les touchesShift + Tab de votre claviers .
 Une fois le plan généré, veuillez le vérifier. Si l'approche semble appropriée, veuillez informer Claude Code de mettre le plan à exécution.
Une fois le plan généré, veuillez le vérifier. Si l'approche semble appropriée, veuillez informer Claude Code de mettre le plan à exécution.
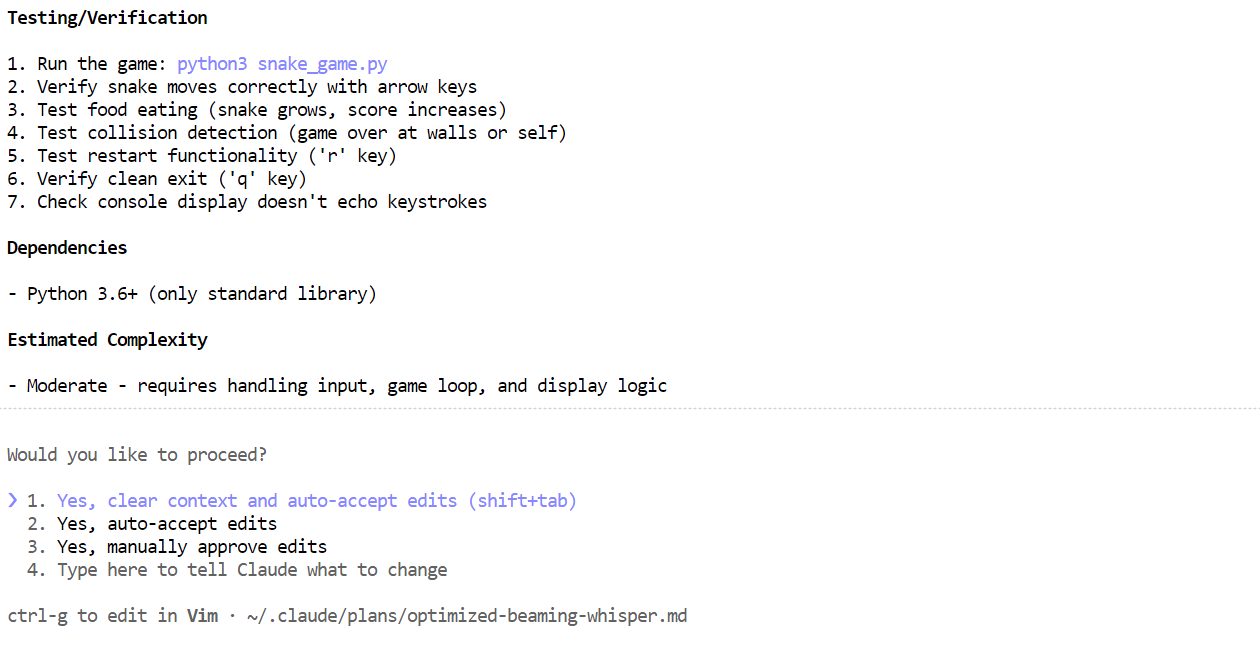 En quelques minutes, il a créé les fichiers requis, expliqué le fonctionnement du jeu Snake et fourni des instructions claires sur la manière de l'exécuter.
En quelques minutes, il a créé les fichiers requis, expliqué le fonctionnement du jeu Snake et fourni des instructions claires sur la manière de l'exécuter.
 Veuillez ouvrir une nouvelle fenêtre de terminal et vous assurer que vous vous trouvez dans le même répertoire de projet. Veuillez ensuite démarrer le jeu avec :
Veuillez ouvrir une nouvelle fenêtre de terminal et vous assurer que vous vous trouvez dans le même répertoire de projet. Veuillez ensuite démarrer le jeu avec :
python3 snake_game.pyLe jeu est prêt à l'emploi, aucune configuration supplémentaire n'est nécessaire. Il s'agit d'un jeu Snake simple, basé sur un terminal, très similaire à la version classique du Nokia 3310. Malgré sa simplicité, il s'agit d'un excellent exemple de la rapidité et de l'efficacité du codage agentique local avec Claude Code et Ollama.
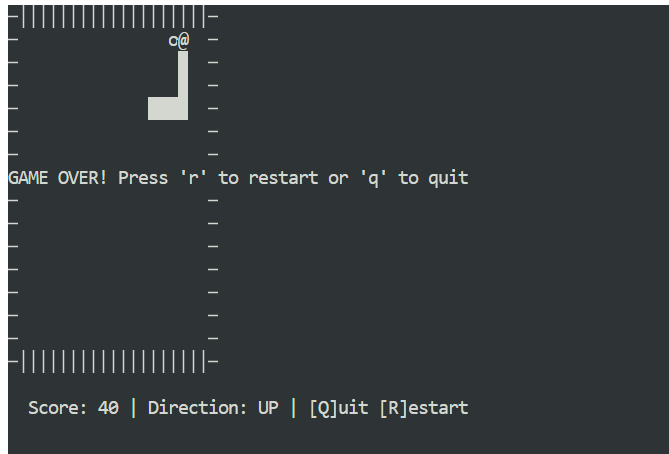
L'exécution de Claude Code avec GLM 4.7 Flash sur Ollama démontre les progrès réalisés en matière de codage agentique local. Vous bénéficiez de réponses rapides, d'une génération de code performante et d'un contrôle total sur vos données, sans dépendre de modèles hébergés dans le cloud.
Une fois configuré, le flux de travail est fluide et fiable, même pour les tâches de codage en plusieurs étapes.
Il est important de retenir que des fenêtres contextuelles plus grandes et des configurations plus complexes ne sont pas toujours préférables. Avec des paramètres par défaut raisonnables, la configuration complète prend environ cinq minutes, hors temps de téléchargement du modèle, qui dépend de votre connexion Internet.
Si vous avez déjà téléchargé le fichier GGUF pour le modèle, l'installation sera encore plus rapide. Dans ce cas, vous pouvez ignorer complètement le téléchargement du modèle et simplement enregistrer le fichier GGUF existant dans Ollama en créant unfichier modèle .
Cela vous permet de définir les paramètres de génération une seule fois et de réutiliser le modèle de manière cohérente entre les exécutions et les outils.
Veuillez créer un fichier nommé Modelfile dans le même répertoire que votre fichier GGUF :
FROM ./glm-4.7-flash.gguf
PARAMETER temperature 0.8
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.0Vous pouvez ajuster les paramètres selon vos besoins :
Veuillez enregistrer le modèle auprès d'Ollama :
ollama create glm-4.7-flash-local -f ModelfileUne fois le modèle créé, vous pouvez l'exécuter directement en mode chat :
ollama run glm-4.7-flash-localLe modèle peut désormais être utilisé comme n'importe quel autre modèle Ollama et s'intègre parfaitement à Claude Code.
J'ai pris beaucoup de plaisir à créer des applications et des jeux à l'aide de GLM 4.7 Flash dans Claude Code. Il est véritablement valorisant de travailler dans un endroit isolé, sans connexion Internet ou avec une connexion instable. Tout fonctionne localement, rien ne se casse, et vous disposez toujours d'un puissant agent de codage à portée de main. Ce sentiment de contrôle et d'indépendance est difficile à égaler.
Si vous souhaitez en savoir plus sur les outils présentés dans cet article, je vous recommande les ressources suivantes :
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Stephen Gruppetta
Tutoriel
Kurtis Pykes
Tutoriel
DataCamp Team
Tutoriel
Mark Pedigo
