
Corso
Progettare sistemi agentici con LangChain
3 h
12.9K
GLM 4.7 Flash sta rapidamente diventando una scelta popolare per il coding agentico in locale. Molti sviluppatori lo usano con strumenti come llama.cpp e LM Studio. Tuttavia, molte persone incontrano ancora problemi durante la configurazione, nell’avvio corretto del modello e nel far funzionare la chiamata agli strumenti come previsto.
Questo tutorial si concentra sul modo più semplice e affidabile per eseguire GLM 4.7 Flash in locale usando Claude Code con Ollama. L’obiettivo è eliminare gli attriti e aiutarti a ottenere una configurazione funzionante senza complessità inutili.
Questa guida funziona su tutti i sistemi operativi. Non importa se usi Linux, Windows o macOS. Alla fine, avrai GLM 4.7 Flash in esecuzione in locale e correttamente integrato con Claude Code tramite Ollama.
Prima di iniziare, assicurati che il tuo sistema soddisfi i requisiti minimi hardware e software qui sotto.
Hardware:
Se non hai una GPU, il modello può girare su CPU, ma le prestazioni saranno significativamente più lente e servirà molta RAM.
Software:
Se il toolkit CUDA o i driver NVIDIA mancano o sono incompatibili, Ollama userà la modalità CPU, che è molto più lenta.
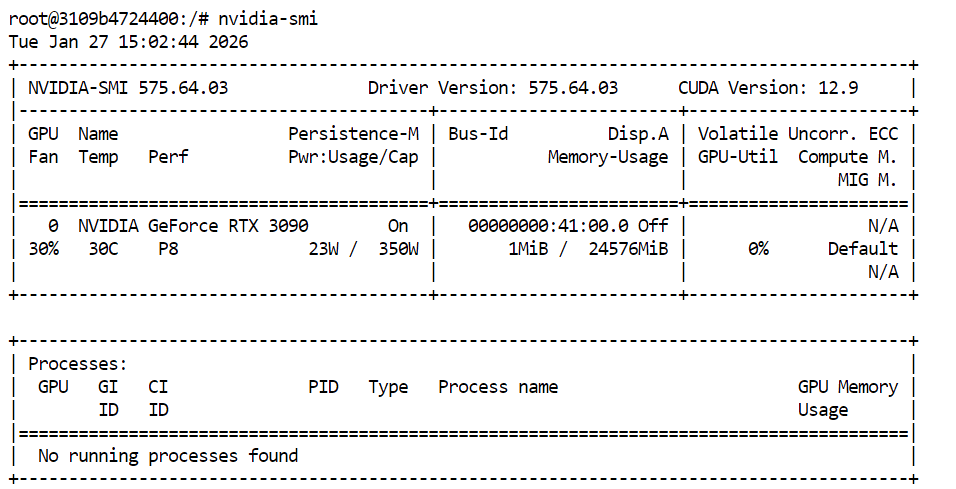
Per verificare che GPU e driver CUDA siano installati correttamente, esegui il seguente comando nel terminale:
nvidia-smiSe tutto è a posto, dovresti vedere la tua GPU elencata insieme alla VRAM disponibile e alla versione di CUDA.
Ollama è il runtime che useremo per eseguire GLM 4.7 Flash in locale ed esporlo in modo che Claude Code possa interagire in maniera affidabile. L’installazione è semplice su tutte le piattaforme supportate.
Su Linux, puoi installare Ollama con un solo comando:
curl -fsSL https://ollama.com/install.sh | shPer macOS e Windows, scarica l’installer direttamente dal sito Ollama e segui le istruzioni sullo schermo.

Fonte: Ollama
Ollama gira come servizio in background e controllerà automaticamente la presenza di aggiornamenti. Quando è disponibile un update, puoi applicarlo selezionando “Riavvia per aggiornare” dal menu di Ollama.
Dopo l’installazione, apri un terminale e verifica che Ollama sia installato correttamente:
ollama -vDovresti vedere un output simile a:
ollama version is 0.15.2Se vedi un errore eseguendo ollama -v, di solito significa che il servizio Ollama non è ancora in esecuzione. Avvia manualmente il server Ollama:
ollama serveLascia questo processo in esecuzione, apri una nuova finestra del terminale e poi esegui:
ollama -vUna volta che il comando della versione funziona, Ollama è pronto per essere usato nei prossimi passaggi del tutorial.
Una volta installato e avviato Ollama, il passo successivo è scaricare il modello GLM 4.7 Flash e verificare che funzioni correttamente. Questo assicura che il modello giri in locale prima di integrarlo con Claude Code.
Fonte: glm-4.7-flash
Inizia scaricando il modello dal registro di Ollama:
ollama pull glm-4.7-flashQuesto scaricherà i file del modello e li salverà in locale. A seconda della velocità della tua connessione, potrebbe richiedere alcuni minuti.
Al termine del download, avvia il modello in modalità chat interattiva come controllo rapido:
ollama run glm-4.7-flashScrivi un prompt semplice, ad esempio un saluto, e premi invio. Entro pochi secondi dovresti ricevere una risposta.
Se stai usando una GPU, noterai che le risposte sono molto veloci e l’output potrebbe includere token di pensiero interni o tracce di ragionamento a seconda della configurazione del modello.

Puoi anche testare il modello tramite l’API HTTP locale di Ollama. È utile per confermare che strumenti esterni possano comunicare con il modello.
Esegui il seguente comando:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role":"user","content":"Hello!"}]
}'Claude Code e la maggior parte degli strumenti di coding agentico funzionano al meglio con finestre di contesto ampie, spesso fino a 64k token. Tuttavia, con GLM 4.7 Flash, scegliere la lunghezza del contesto giusta è importante sia per le prestazioni che per la stabilità.
Usare contesti molto grandi può rallentare significativamente la velocità di generazione. In pratica, il throughput può scendere da oltre 100 token al secondo fino a soli 2 token al secondo. In alcuni casi, il modello può anche bloccarsi in lunghi loop di pensiero se la finestra di contesto è impostata troppo in alto.
Abbiamo testato diverse dimensioni di contesto e abbiamo riscontrato che 10k non era sufficiente per i flussi di lavoro di Claude Code. Un contesto da 20k ha offerto un buon equilibrio. Era abbastanza grande per i compiti di coding mantenendo tempi di risposta rapidi e riducendo loop di pensiero inutili.
Per prima cosa, ferma il server Ollama in esecuzione. Puoi farlo premendo Ctrl + C nel terminale o terminando il processo.
Poi, riavvia Ollama con una lunghezza di contesto personalizzata impostando la variabile d’ambiente prima di lanciare il server:
OLLAMA_CONTEXT_LENGTH=20000 ollama serveQuesto dice a Ollama di caricare i modelli con una finestra di contesto massima di 20.000 token.
In una nuova finestra del terminale, esegui:
ollama psQuesto conferma che GLM 4.7 Flash sta girando sulla GPU e che la lunghezza del contesto è stata impostata correttamente. A questo punto, il modello è configurato per un uso stabile e veloce con Claude Code.
NAME ID SIZE PROCESSOR CONTEXT UNTIL
glm-4.7-flash:latest d1a8a26252f1 21 GB 100% GPU 20000 About a minute from now Claude Code è l’agente per il coding da terminale di Anthropic che ti aiuta a scrivere, modificare, fare refactor e capire il codice usando il linguaggio naturale. È pensato per flussi di lavoro agentici e può gestire compiti di coding multi-step direttamente dalla riga di comando.
Insieme a Ollama, Claude Code può essere usato facilmente con modelli locali come GLM 4.7 Flash, permettendoti di eseguire tutto in locale e mantenere il codice sulla tua macchina.
Su macOS, Linux o Windows con WSL, installa Claude Code usando lo script ufficiale:
curl -fsSL https://claude.ai/install.sh | bashQuesto comando scarica e installa Claude Code insieme alle dipendenze richieste. Una volta completata l’installazione, il comando claude sarà disponibile nel tuo terminale.
Ora che sia Ollama sia Claude Code sono installati, il passo successivo è collegare Claude Code al tuo server Ollama locale e configurarlo per usare il modello GLM 4.7 Flash.
Inizia creando una directory di lavoro per il tuo progetto. Qui è dove Claude Code opererà e gestirà i file:
mkdir <project-name>
cd <project-name>Ollama ora fornisce un modo integrato per lanciare Claude Code che lo configura automaticamente per parlare con il runtime locale di Ollama. È l’approccio consigliato e più affidabile.
Per avviare Claude Code in modo interattivo usando Ollama:
ollama launch claudePer avviare direttamente Claude Code usando il modello GLM 4.7 Flash, esegui:
ollama launch claude --model glm-4.7-flashQuesto assicura che Claude Code usi il tuo modello GLM 4.7 Flash locale invece di un modello remoto o predefinito.
Una volta configurato tutto, vedrai l’interfaccia di Claude Code direttamente nel terminale.
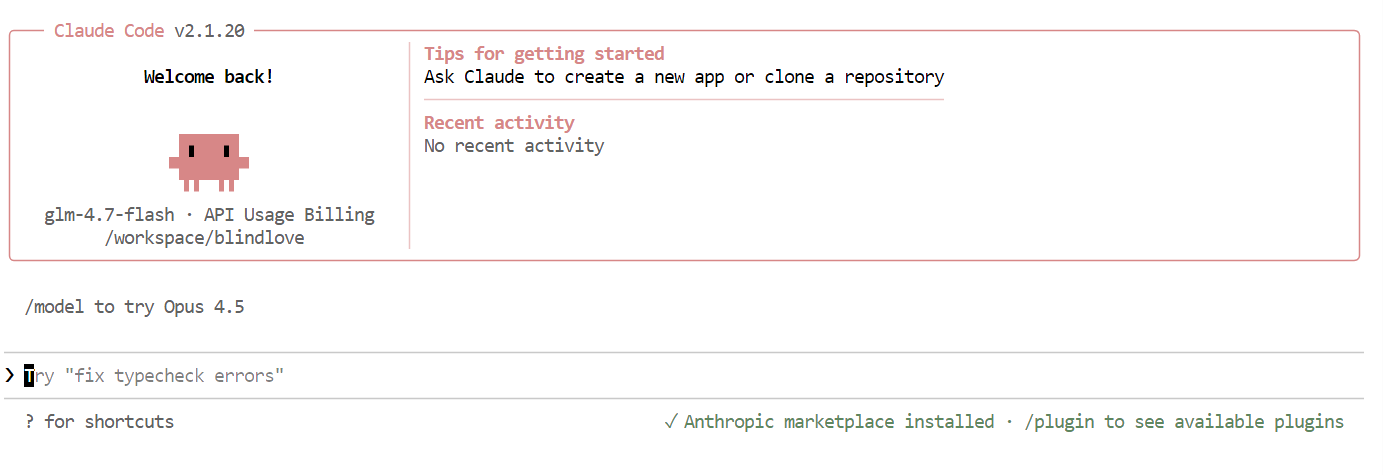
All’interno di Claude Code, usa il seguente comando per confermare che stia usando il tuo modello locale:
/modelSe l’output mostra glm-4.7-flash, la configurazione è completata e Claude Code sta girando con successo sul tuo modello locale in Ollama.
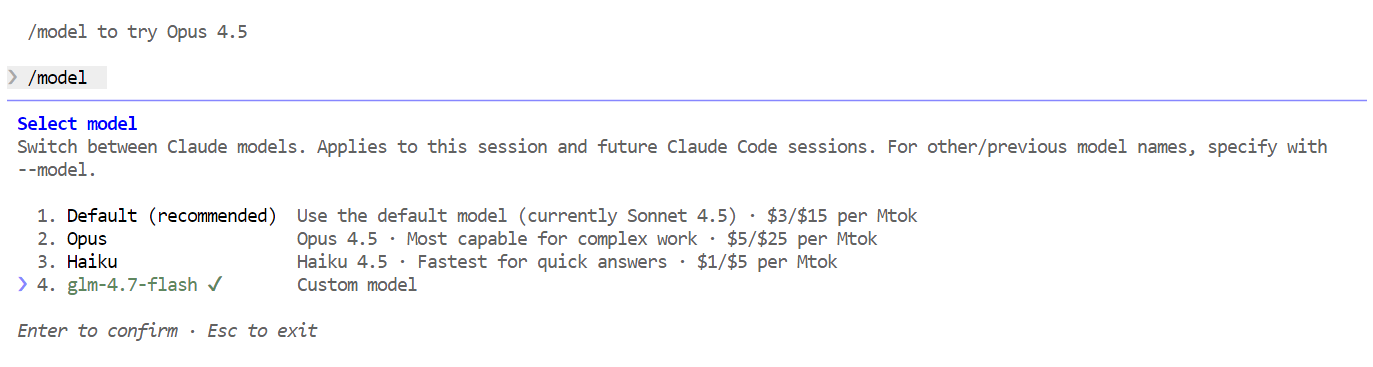
Con tutto configurato, puoi iniziare a usare Claude Code alimentato dal tuo modello locale GLM 4.7 Flash. La prima cosa da provare è un semplice saluto. Nel giro di uno o due secondi dovresti ricevere una risposta. La velocità è notevole, soprattutto su GPU.
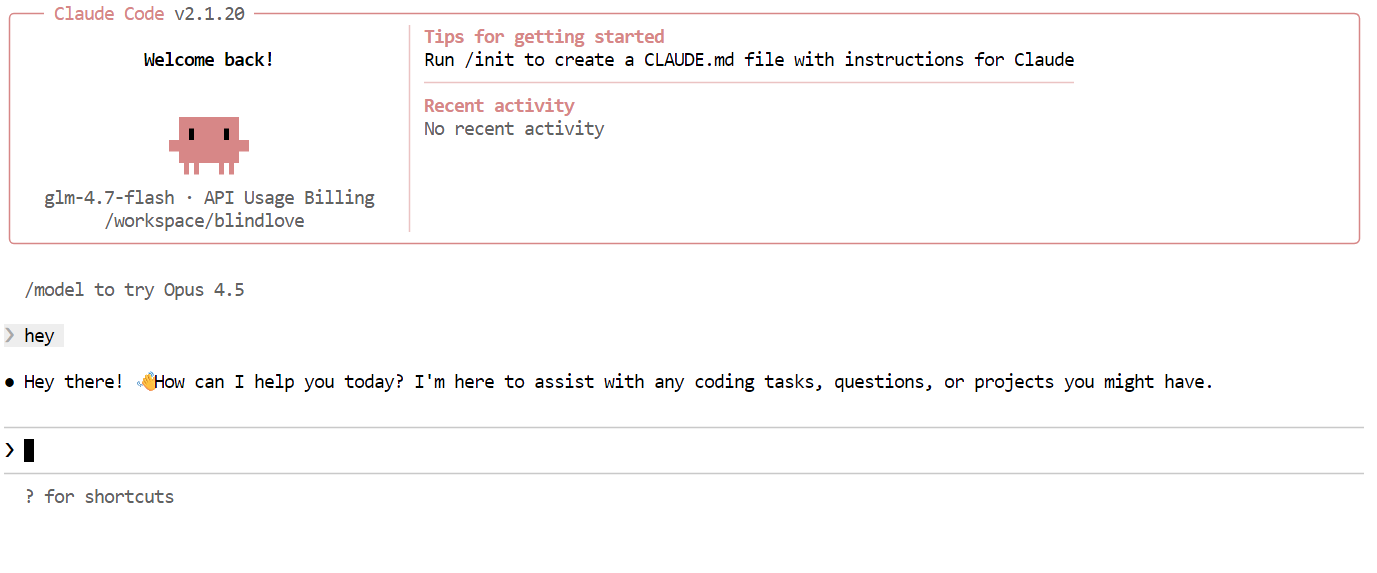
Poi prova un compito di coding più realistico. Chiedi a Claude Code di creare un gioco Snake da CLI in Python. Prima di generare il codice, passa alla modalità di pianificazione in modo che il modello delinei prima l’approccio. Puoi attivare la modalità di pianificazione premendo Shift + Tab due volte.
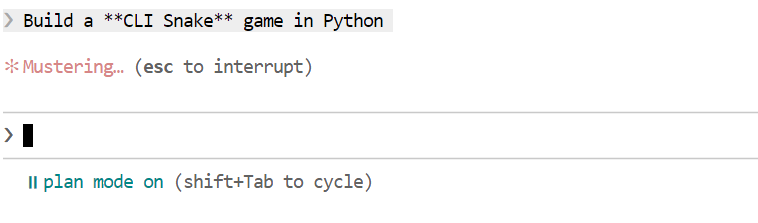 Una volta generato il piano, rivedilo. Se l’approccio ti sembra valido, chiedi a Claude Code di eseguirlo.
Una volta generato il piano, rivedilo. Se l’approccio ti sembra valido, chiedi a Claude Code di eseguirlo.
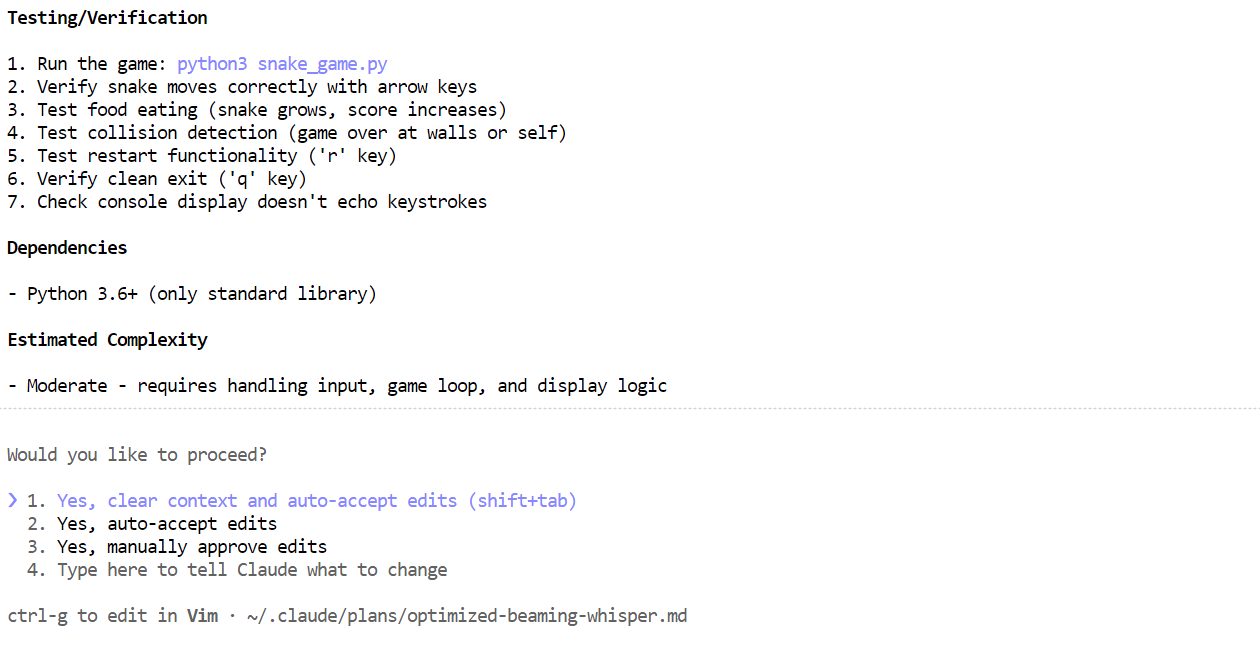 Nel giro di pochi minuti, avrai i file necessari, una spiegazione di cosa fa il gioco Snake e istruzioni chiare su come avviarlo.
Nel giro di pochi minuti, avrai i file necessari, una spiegazione di cosa fa il gioco Snake e istruzioni chiare su come avviarlo.
 Apri una nuova finestra del terminale e assicurati di essere nella stessa directory del progetto. Poi avvia il gioco con:
Apri una nuova finestra del terminale e assicurati di essere nella stessa directory del progetto. Poi avvia il gioco con:
python3 snake_game.pyIl gioco parte subito senza configurazioni extra. È un semplice Snake da terminale, molto simile alla versione classica del Nokia 3310. Nonostante la semplicità, è un ottimo esempio di quanto possano essere veloci ed efficaci i flussi di lavoro agentici in locale con Claude Code e Ollama.
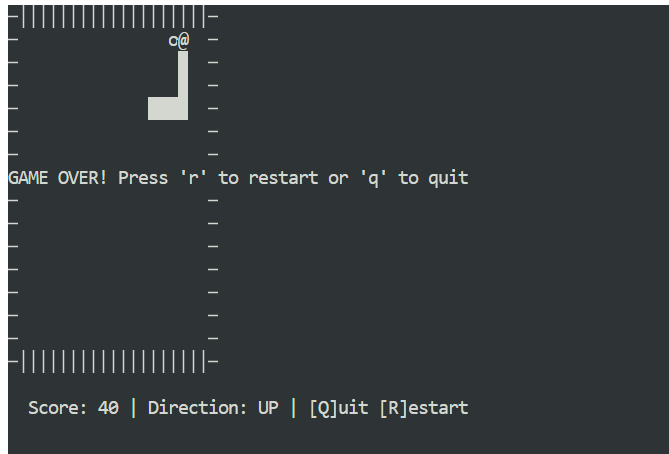
Usare Claude Code con GLM 4.7 Flash su Ollama mostra quanta strada abbia fatto il coding agentico in locale. Ottieni risposte rapide, una forte capacità di generazione del codice e pieno controllo sui tuoi dati, il tutto senza dipendere da modelli ospitati nel cloud.
Una volta configurato, il flusso di lavoro è fluido e affidabile, anche per compiti di coding multi-step.
Un punto chiave è che finestre di contesto più grandi e configurazioni più complesse non sono sempre meglio. Con impostazioni sensate, l’intera configurazione richiede circa cinque minuti, escluso il tempo di download del modello, che dipende dalla tua connessione.
Se hai già scaricato il file GGUF del modello, la configurazione è ancora più veloce. In questo caso, puoi saltare il download del modello e semplicemente registrare il file GGUF esistente con Ollama creando un Modelfile.
Questo ti permette di definire una volta i parametri di generazione e riutilizzare il modello in modo coerente tra esecuzioni e strumenti.
Crea un file chiamato Modelfile nella stessa directory del tuo file GGUF:
FROM ./glm-4.7-flash.gguf
PARAMETER temperature 0.8
PARAMETER top_p 0.95
PARAMETER repeat_penalty 1.0Puoi regolare i parametri secondo necessità:
Registra il modello con Ollama:
ollama create glm-4.7-flash-local -f ModelfileUna volta creato il modello, puoi eseguirlo direttamente in modalità chat:
ollama run glm-4.7-flash-localOra il modello può essere usato come qualunque altro modello di Ollama e integrato senza problemi con Claude Code.
Mi sono divertito molto a creare app e giochi usando GLM 4.7 Flash dentro Claude Code. È davvero gratificante lavorare in un luogo remoto senza internet o con connettività instabile. Tutto gira in locale, niente si rompe e hai comunque un potente agente di coding a portata di mano. Quella sensazione di controllo e indipendenza è difficile da battere.
Se vuoi approfondire gli strumenti trattati in questo articolo, ti consiglio le seguenti risorse:
I migliori corsi DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

