
Kursus
Pengantar Deep Learning dengan PyTorch
4 Hr
87.7K
Seiring teknologi machine learning berkembang dengan kecepatan yang belum pernah terjadi sebelumnya, Variational Autoencoders (VAE) merevolusi cara kita memproses dan menghasilkan data. Dengan menggabungkan pengodean data yang kuat dengan kemampuan generatif yang inovatif, VAE menawarkan solusi transformatif untuk tantangan kompleks di bidang ini.
Dalam artikel ini, kita akan mengeksplorasi konsep inti di balik VAE, aplikasinya, dan bagaimana cara mengimplementasikannya secara efektif menggunakan PyTorch, selangkah demi selangkah.
Autoencoder adalah jenis jaringan saraf yang dirancang untuk mempelajari representasi data yang efisien, terutama untuk tujuan reduksi dimensi atau pembelajaran fitur.
Autoencoder terdiri dari dua bagian utama:
Tujuan utama autoencoder adalah meminimalkan perbedaan antara masukan dan keluaran rekonstruksi, sehingga mempelajari representasi data yang ringkas.
Masuklah Variational Autoencoders (VAE), yang memperluas kemampuan kerangka autoencoder tradisional dengan memasukkan elemen probabilistik ke dalam proses pengodean.
Sementara autoencoder standar memetakan masukan ke representasi laten yang tetap, VAE memperkenalkan pendekatan probabilistik di mana encoder menghasilkan distribusi atas ruang laten, yang biasanya dimodelkan sebagai Gaussian multivariat. Ini memungkinkan VAE untuk melakukan pengambilan sampel dari distribusi tersebut selama proses decoding, yang menghasilkan pembuatan instance data baru.
Inovasi kunci VAE terletak pada kemampuannya menghasilkan data baru yang berkualitas tinggi dengan mempelajari ruang laten yang terstruktur dan kontinu. Ini sangat penting untuk pemodelan generatif, di mana tujuannya bukan hanya mengompresi data tetapi juga membuat sampel data baru yang menyerupai dataset asli.
VAE telah menunjukkan efektivitas yang signifikan dalam tugas-tugas seperti sintesis gambar, denoising data, dan deteksi anomali, menjadikannya alat yang relevan untuk meningkatkan kemampuan model dan aplikasi machine learning.
Pada bagian ini, kami akan memperkenalkan latar belakang teoretis dan mekanisme operasional VAE, memberi Anda dasar yang kuat untuk mengeksplorasi aplikasinya di bagian selanjutnya.
Mari mulai dengan encoder. Encoder adalah sebuah jaringan saraf yang bertugas memetakan data masukan ke ruang laten. Tidak seperti autoencoder tradisional yang menghasilkan titik tetap di ruang laten, encoder dalam VAE menghasilkan parameter distribusi probabilitas—biasanya mean dan varians dari distribusi Gaussian. Ini memungkinkan VAE memodelkan ketidakpastian dan keragaman data secara efektif.
Jaringan saraf lain yang disebut decoder digunakan untuk merekonstruksi data asli dari representasi ruang laten. Diberikan sebuah sampel dari distribusi ruang laten, decoder bertujuan menghasilkan keluaran yang sangat mirip dengan data masukan asli. Proses ini memungkinkan VAE menciptakan instance data baru dengan melakukan sampling dari distribusi yang telah dipelajari.
Ruang laten adalah ruang kontinu berdimensi lebih rendah tempat data masukan dienkode.
Visualisasi peran encoder, decoder, dan ruang laten. Sumber gambar.
Pendekatan variational adalah teknik untuk mendekati distribusi probabilitas yang kompleks. Dalam konteks VAE, ini melibatkan pendekatan terhadap distribusi posterior sejati dari variabel laten yang diberikan data, yang sering kali tidak terjangkau untuk dihitung secara eksak.
VAE mempelajari distribusi posterior pendekatan. Tujuannya adalah membuat pendekatan ini sedekat mungkin dengan posterior sejati.
Inferensi Bayesian adalah metode untuk memperbarui estimasi probabilitas suatu hipotesis seiring lebih banyak bukti atau informasi tersedia. Dalam VAE, inferensi Bayesian digunakan untuk memperkirakan distribusi variabel laten.
Dengan mengintegrasikan pengetahuan awal (distribusi prior) dengan data yang diamati (likelihood), VAE menyesuaikan representasi ruang laten melalui distribusi posterior yang dipelajari.
Inferensi Bayesian dengan distribusi prior, distribusi posterior, dan fungsi likelihood. Sumber gambar.
Berikut alur prosesnya:
Mari kita tinjau perbedaan dan keunggulan VAE dibanding autoencoder tradisional.
Seperti telah dibahas sebelumnya, autoencoder tradisional terdiri dari jaringan encoder yang memetakan data masukan x ke representasi ruang laten berdimensi lebih rendah yang tetap, z. Proses ini deterministik, artinya setiap masukan dikodekan ke titik tertentu di ruang laten.
Jaringan decoder kemudian merekonstruksi data asli dari representasi laten yang tetap ini, dengan tujuan meminimalkan perbedaan antara masukan dan rekonstruksinya.
Ruang laten pada autoencoder tradisional adalah representasi terkompresi dari data masukan tanpa pemodelan probabilistik, yang membatasi kemampuannya untuk menghasilkan data baru yang beragam karena tidak ada mekanisme untuk menangani ketidakpastian.
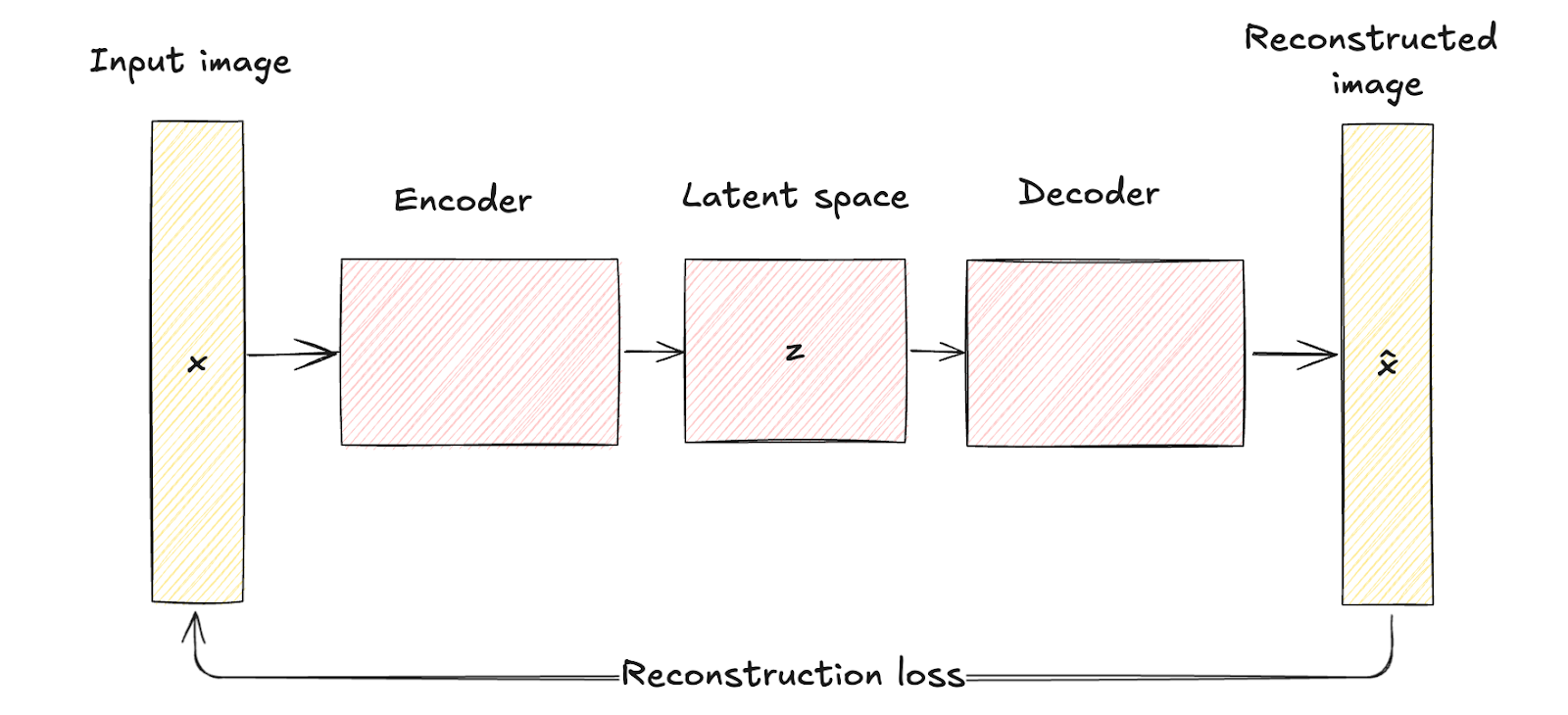
Arsitektur autoencoder. Gambar oleh penulis
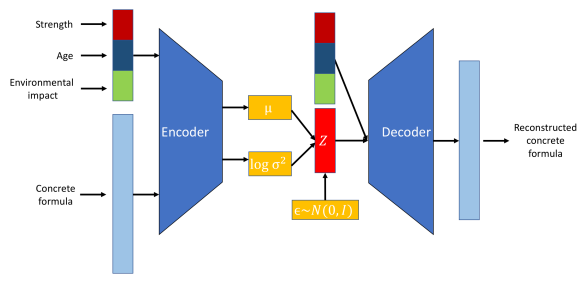
VAE memperkenalkan elemen probabilistik ke dalam proses pengodean. Secara khusus, encoder dalam VAE memetakan data masukan ke distribusi probabilitas atas variabel laten, yang biasanya dimodelkan sebagai distribusi Gaussian dengan mean μ dan varians σ2.
Pendekatan ini mengodekan setiap masukan menjadi sebuah distribusi alih-alih satu titik, menambahkan lapisan variabilitas dan ketidakpastian.
Perbedaan arsitektural ini divisualisasikan melalui pemetaan deterministik pada autoencoder tradisional versus pengodean dan pengambilan sampel probabilistik pada VAE.
Perbedaan struktur ini menyoroti bagaimana VAE memasukkan regularisasi melalui istilah yang dikenal sebagai KL divergence, membentuk ruang laten agar kontinu dan terstruktur dengan baik.
Regularisasi yang diperkenalkan secara signifikan meningkatkan kualitas dan koherensi sampel yang dihasilkan, melampaui kemampuan autoencoder tradisional.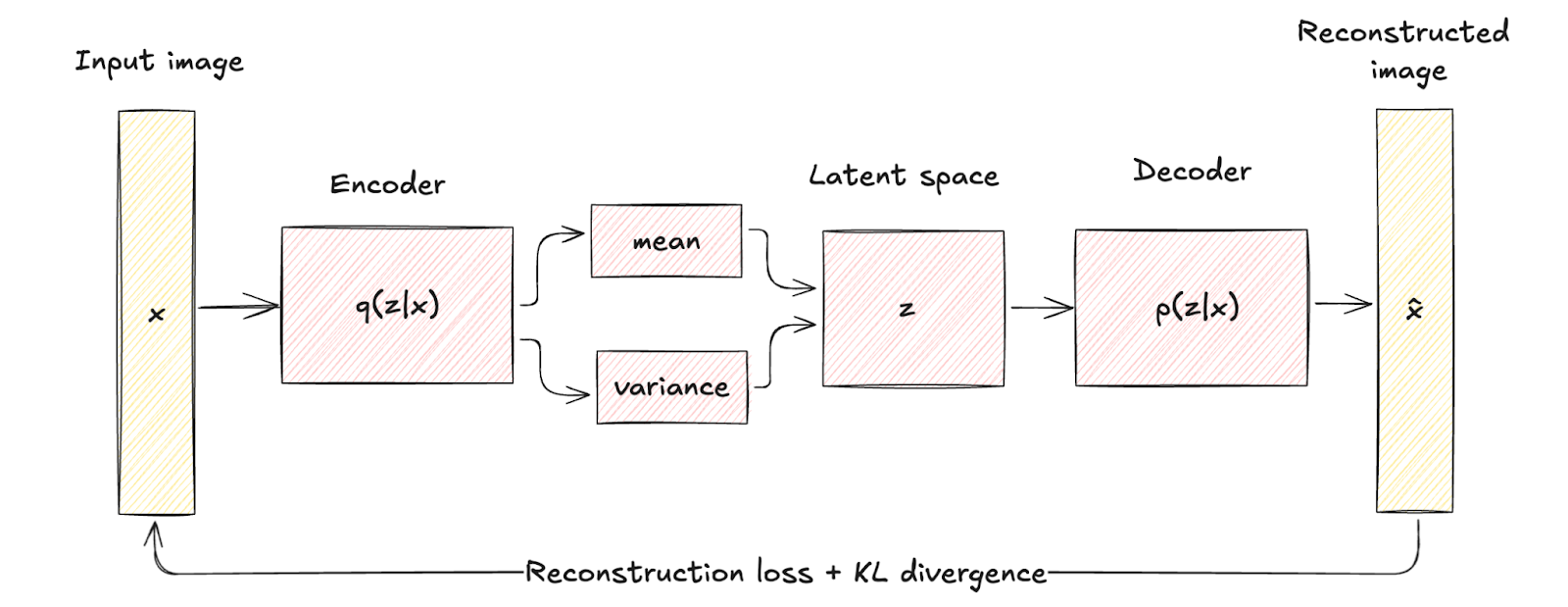
Arsitektur Variational Autoencoder. Gambar oleh penulis
Sifat probabilistik VAE secara signifikan memperluas jangkauan aplikasinya dibanding autoencoder tradisional. Sebaliknya, autoencoder tradisional sangat efektif pada aplikasi di mana representasi data deterministik sudah memadai.
Mari kita lihat beberapa aplikasi masing-masing untuk memperjelas poin ini.
VAE telah berevolusi menjadi berbagai bentuk khusus untuk mengatasi beragam tantangan dan aplikasi dalam machine learning. Pada bagian ini, kita akan meninjau tipe-tipe yang paling menonjol, menyoroti use case, kelebihan, dan keterbatasannya.
Conditional Variational Autoencoders (CVAE) adalah bentuk khusus VAE yang meningkatkan proses generatif dengan melakukan kondisioning pada informasi tambahan.
VAE menjadi bersyarat dengan memasukkan informasi tambahan, dinotasikan sebagai c, ke dalam jaringan encoder dan decoder. Informasi kondisional ini bisa berupa data relevan apa pun, seperti label kelas, atribut, atau data kontekstual lainnya.
Struktur model CVAE. Sumber gambar.
Use case CVAE meliputi:
Kelebihan dan kekurangannya adalah:
Disentangled Variational Autoencoders, sering disebut Beta-VAE, adalah tipe VAE khusus lainnya. Tujuannya adalah mempelajari representasi laten di mana setiap dimensi menangkap faktor variasi data yang berbeda dan dapat ditafsirkan. Ini dicapai dengan memodifikasi tujuan VAE asli menggunakan hiperparameter β yang menyeimbangkan loss rekonstruksi dan istilah KL divergence.
Kelebihan dan kekurangan Beta-VAE:
Varian lain dari VAE adalah Adversarial Autoencoders (AAE). AAE menggabungkan kerangka VAE dengan prinsip pelatihan adversarial dari Generative Adversarial Networks (GAN). Jaringan diskriminator tambahan memastikan bahwa representasi laten sesuai dengan distribusi prior, sehingga meningkatkan kemampuan generatif model.
Kelebihan dan kekurangan AAE:
Sekarang, kita akan melihat dua ekstensi Variational Autoencoders lainnya.
Yang pertama adalah Variational Recurrent Autoencoders (VRAE). VRAE memperluas kerangka VAE ke data berurutan dengan memasukkan recurrent neural network (RNN) ke dalam jaringan encoder dan decoder. Ini memungkinkan VRAE menangkap ketergantungan temporal dan memodelkan pola sekuensial.
Kelebihan dan kekurangan VRAE:
Varian terakhir yang akan kita tinjau adalah Hierarchical Variational Autoencoders (HVAE). HVAE memperkenalkan beberapa lapisan variabel laten yang disusun secara hierarkis, yang memungkinkan model menangkap ketergantungan dan abstraksi yang lebih kompleks pada data.
Kelebihan dan kekurangan HVAE:
Pada bagian ini, kita akan mengimplementasikan Variational Autoencoder (VAE) sederhana menggunakan PyTorch.
Untuk mengimplementasikan VAE, kita perlu menyiapkan lingkungan Python dengan pustaka dan alat yang diperlukan. Pustaka yang akan kita gunakan adalah:
Berikut kode untuk memasang pustaka tersebut:
pip install torch torchvision matplotlib numpyMari kita telusuri implementasi VAE selangkah demi selangkah. Pertama, kita harus mengimpor pustaka:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as npSelanjutnya, kita harus mendefinisikan encoder, decoder, dan VAE. Berikut kodenya:
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
h = torch.relu(self.fc1(z))
x_hat = torch.sigmoid(self.fc2(h))
return x_hat
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
mu, logvar = self.encoder(x)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = mu + eps * std
x_hat = self.decoder(z)
return x_hat, mu, logvarKita juga harus mendefinisikan fungsi loss. Fungsi loss untuk VAE terdiri dari loss rekonstruksi dan loss KL divergence. Seperti inilah implementasinya di PyTorch:
def loss_function(x, x_hat, mu, logvar):
BCE = nn.functional.binary_cross_entropy(x_hat, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLDUntuk melatih VAE, kita akan memuat dataset MNIST, mendefinisikan optimizer, dan melatih model.
# Hyperparameters
input_dim = 784
hidden_dim = 400
latent_dim = 20
lr = 1e-3
batch_size = 128
epochs = 10
# Data loader
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Model, optimizer
vae = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(vae.parameters(), lr=lr)
# Training loop
vae.train()
for epoch in range(epochs):
train_loss = 0
for x, _ in train_loader:
x = x.view(-1, input_dim)
optimizer.zero_grad()
x_hat, mu, logvar = vae(x)
loss = loss_function(x, x_hat, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset)}")Setelah pelatihan, kita dapat mengevaluasi VAE dengan memvisualisasikan keluaran rekonstruksi dan sampel yang dihasilkan.
Berikut kodenya:
# visualizing reconstructed outputs
vae.eval()
with torch.no_grad():
x, _ = next(iter(train_loader))
x = x.view(-1, input_dim)
x_hat, _, _ = vae(x)
x = x.view(-1, 28, 28)
x_hat = x_hat.view(-1, 28, 28)
fig, axs = plt.subplots(2, 10, figsize=(15, 3))
for i in range(10):
axs[0, i].imshow(x[i].cpu().numpy(), cmap='gray')
axs[1, i].imshow(x_hat[i].cpu().numpy(), cmap='gray')
axs[0, i].axis('off')
axs[1, i].axis('off')
plt.show()
#visualizing generated samples
with torch.no_grad():
z = torch.randn(10, latent_dim)
sample = vae.decoder(z)
sample = sample.view(-1, 28, 28)
fig, axs = plt.subplots(1, 10, figsize=(15, 3))
for i in range(10):
axs[i].imshow(sample[i].cpu().numpy(), cmap='gray')
axs[i].axis('off')
plt.show()
Visualisasi keluaran. Baris atas adalah data MNIST asli, baris tengah adalah keluaran rekonstruksi, dan baris terakhir adalah sampel yang dihasilkan—gambar oleh penulis.
Meskipun Variational Autoencoders (VAE) adalah alat yang kuat untuk pemodelan generatif, ada beberapa tantangan dan keterbatasan yang dapat memengaruhi kinerjanya. Mari kita bahas beberapa di antaranya, serta strategi mitigasinya.
Ini adalah fenomena ketika VAE gagal menangkap seluruh keragaman distribusi data. Akibatnya, sampel yang dihasilkan hanya mewakili beberapa mode (wilayah berbeda) dari distribusi data dan mengabaikan yang lain. Ini menyebabkan kurangnya variasi pada keluaran yang dihasilkan.
Mode collapse disebabkan oleh:
Mode collapse dapat dikurangi dengan menggunakan:
Dalam beberapa kasus, ruang laten yang dipelajari VAE bisa menjadi tidak informatif, di mana model tidak secara efektif menggunakan variabel laten untuk menangkap fitur bermakna dari data masukan. Ini dapat menghasilkan kualitas sampel dan rekonstruksi yang buruk.
Hal ini biasanya terjadi karena alasan berikut:
Ruang laten yang tidak informatif dapat diatasi dengan memanfaatkan strategi warm-up, yaitu secara bertahap meningkatkan bobot KL divergence selama pelatihan atau dengan langsung memodifikasi bobot istilah KL divergence dalam fungsi loss.
Melatih VAE terkadang tidak stabil, dengan fungsi loss yang berosilasi atau menyimpang. Ini dapat menyulitkan tercapainya konvergensi dan model yang terlatih dengan baik.
Alasan terjadinya hal ini adalah karena:
Langkah untuk mengurangi ketidakstabilan pelatihan melibatkan penggunaan:
Melatih VAE, terutama dengan dataset yang besar dan kompleks, bisa mahal secara komputasi. Ini karena kebutuhan sampling dan backpropagation melalui lapisan stokastik.
Penyebab tingginya biaya komputasi meliputi:
Beberapa tindakan mitigasi berikut dapat dilakukan:
Variational Autoencoders (VAE) terbukti menjadi terobosan di ranah machine learning dan pembuatan data.
Dengan memperkenalkan elemen probabilistik ke dalam kerangka autoencoder tradisional, VAE memungkinkan pembuatan data baru yang berkualitas tinggi dan menyediakan ruang laten yang lebih terstruktur dan kontinu. Kemampuan unik ini telah membuka beragam aplikasi, dari pemodelan generatif dan deteksi anomali hingga imputasi data dan pembelajaran semi-terawasi.
Dalam artikel ini, kami telah membahas dasar-dasar Variational Autoencoders, berbagai tipenya, cara mengimplementasikan VAE di PyTorch, serta tantangan dan solusi saat bekerja dengan VAE.
Lihat sumber daya berikut untuk melanjutkan pembelajaran Anda:
Pelajari lebih lanjut tentang AI dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
