
Cursus
Introductie tot Deep Learning met PyTorch
4 Hr
87.7K
Nu machinelearningtechnologie in een ongekend tempo vooruitgaat, veranderen Variational Autoencoders (VAEs) de manier waarop we data verwerken en genereren. Door krachtige data-encodering te combineren met innovatieve generatieve mogelijkheden bieden VAEs baanbrekende oplossingen voor complexe uitdagingen in het vakgebied.
In dit artikel verkennen we de kernconcepten achter VAEs, hun toepassingen en hoe je ze stap voor stap effectief kunt implementeren met PyTorch.
Autoencoders zijn een type neuraal netwerk dat is ontworpen om efficiënte datarepresentaties te leren, voornamelijk met het oog op dimensionale reductie of feature learning.
Autoencoders bestaan uit twee hoofdonderdelen:
Het primaire doel van autoencoders is het minimaliseren van het verschil tussen de input en de gereconstrueerde output, en zo een compacte representatie van de data te leren.
Daar komen Variational Autoencoders (VAEs) om de hoek kijken, die de mogelijkheden van het traditionele autoencoder-raamwerk uitbreiden door probabilistische elementen in het encoderingproces op te nemen.
Waar standaard autoencoders inputs naar vaste latente representaties mappen, introduceren VAEs een probabilistische benadering waarbij de encoder een verdeling over de latente ruimte uitgeeft, meestal gemodelleerd als een multivariate Gaussiaan. Hierdoor kunnen VAEs tijdens het decoderen uit deze verdeling sampelen, wat leidt tot de generatie van nieuwe datapunten.
De kerninnovatie van VAEs ligt in hun vermogen om nieuwe, hoogwaardige data te genereren door een gestructureerde, continue latente ruimte te leren. Dit is vooral belangrijk voor generatief modelleren, waar het doel niet alleen is om data te comprimeren, maar ook om nieuwe datamonsters te creëren die lijken op de oorspronkelijke dataset.
VAEs hebben hun effectiviteit bewezen bij taken als beeldsynthese, datadenoising en anomaliedetectie, waardoor ze relevante tools zijn om de capaciteiten van machinelearningmodellen en -toepassingen te vergroten.
In deze sectie introduceren we de theoretische achtergrond en de werking van VAEs, zodat je een stevige basis hebt om hun toepassingen in latere secties te verkennen.
Laten we beginnen met encoders. De encoder is een neuraal netwerk dat verantwoordelijk is voor het mappen van inputdata naar een latente ruimte. In tegenstelling tot traditionele autoencoders die een vast punt in de latente ruimte produceren, geeft de encoder in een VAE parameters van een kansverdeling uit—doorgaans het gemiddelde en de variantie van een Gaussiaanse verdeling. Dit stelt de VAE in staat onzekerheid en variabiliteit in data effectief te modelleren.
Een ander neuraal netwerk, de decoder, wordt gebruikt om de oorspronkelijke data te reconstrueren vanuit de latente representatie. Gegeven een sample uit de latente ruimtedistributie, probeert de decoder een output te genereren die sterk lijkt op de originele inputdata. Dit proces stelt de VAE in staat nieuwe data-instanties te creëren door te sampelen uit de geleerde verdeling.
De latente ruimte is een lager-dimensionale, continue ruimte waarin de inputdata wordt gecodeerd.
Visualisatie van de rol van de encoder, decoder en latente ruimte. Afbeelding bron.
De variationele aanpak is een techniek om complexe kansverdelingen te benaderen. In de context van VAEs houdt dit in dat de ware posteriorverdeling van latente variabelen gegeven de data wordt benaderd, wat vaak onoplosbaar is.
De VAE leert een benaderde posteriorverdeling. Het doel is om deze benadering zo dicht mogelijk bij de ware posterior te brengen.
Bayesiaanse inferentie is een methode om de waarschijnlijkheidsschatting voor een hypothese bij te werken naarmate er meer bewijs of informatie beschikbaar komt. In VAEs wordt Bayesiaanse inferentie gebruikt om de verdeling van latente variabelen te schatten.
Door voorkennis (priorverdeling) te combineren met de geobserveerde data (likelihood) passen VAEs de latente ruimtereprentatie aan via de geleerde posteriorverdeling.
Bayesiaanse inferentie met een priorverdeling, posteriorverdeling en likelihoodfunctie. Afbeelding bron.
Zo ziet de procesflow eruit:
Laten we de verschillen en voordelen van VAEs ten opzichte van traditionele autoencoders bekijken.
Zoals eerder gezien bestaan traditionele autoencoders uit een encodernetwerk dat de inputdata x naar een vaste, lager-dimensionale latente ruimtereprentatie z mappt. Dit proces is deterministisch: elke input wordt naar een specifiek punt in de latente ruimte gecodeerd.
Het decodernetwerk reconstrueert vervolgens de oorspronkelijke data vanuit deze vaste latente representatie, met als doel het verschil tussen de input en de reconstructie te minimaliseren.
De latente ruimte van traditionele autoencoders is een gecomprimeerde representatie van de inputdata zonder probabilistische modellering, wat hun vermogen beperkt om nieuwe, diverse data te genereren omdat ze geen mechanisme hebben om met onzekerheid om te gaan.
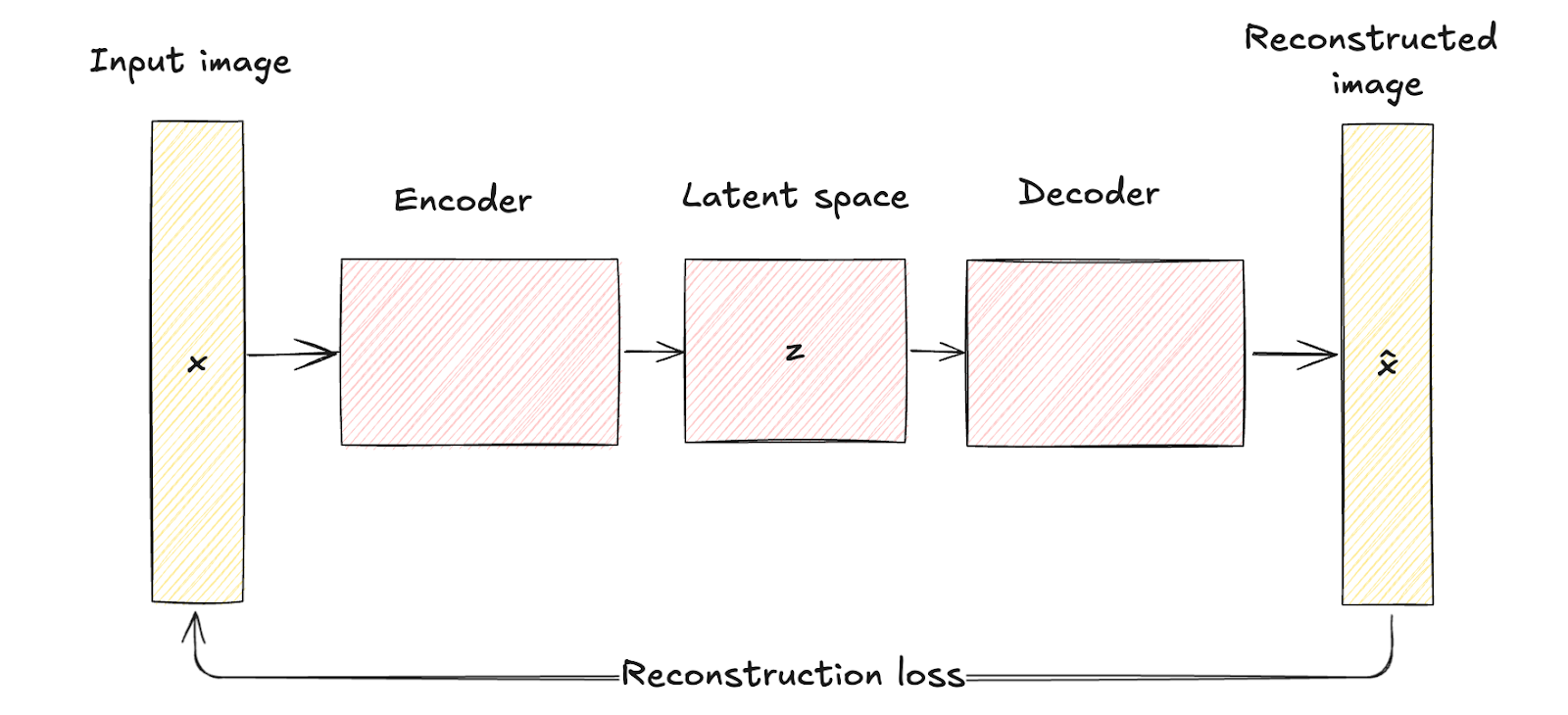
Autoencoder-architectuur. Afbeelding door auteur
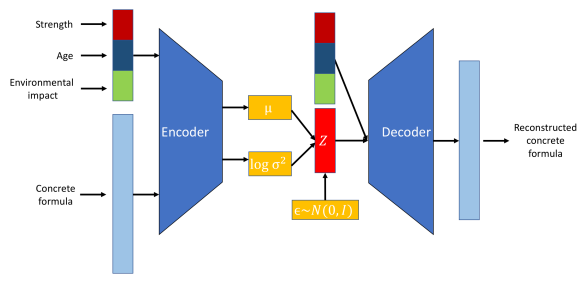
VAEs introduceren een probabilistisch element in het encoderingproces. Concreet mappt de encoder in een VAE de inputdata naar een kansverdeling over de latente variabelen, doorgaans gemodelleerd als een Gaussiaanse verdeling met gemiddelde μ en variantie σ2.
Deze aanpak codeert elke input in een verdeling in plaats van in één enkel punt, wat een laag van variabiliteit en onzekerheid toevoegt.
De architectuurverschillen worden visueel weergegeven door de deterministische mapping in traditionele autoencoders versus de probabilistische encodering en sampling in VAEs.
Dit structurele verschil benadrukt hoe VAEs regularisatie opnemen via een term die KL-divergentie wordt genoemd, waardoor de latente ruimte continu en goed gestructureerd wordt vormgegeven.
De geïntroduceerde regularisatie verbetert de kwaliteit en samenhang van de gegenereerde samples aanzienlijk en overtreft daarmee de mogelijkheden van traditionele autoencoders.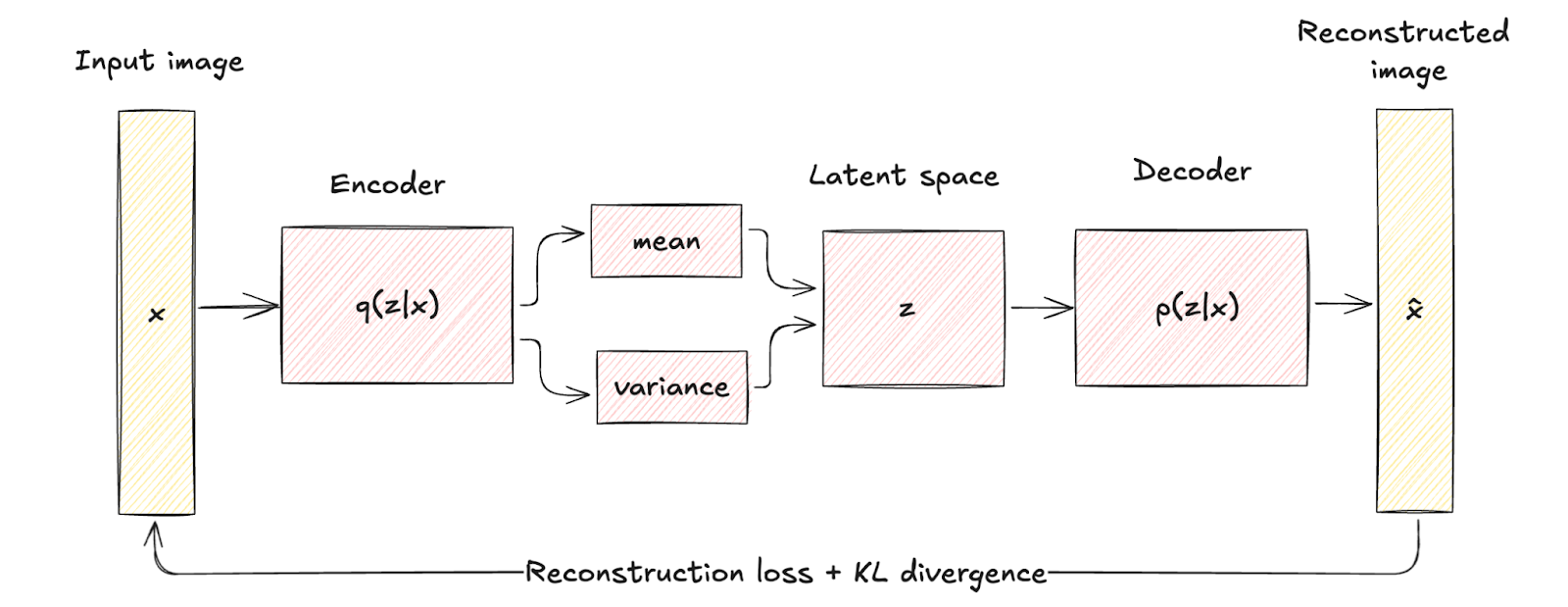
Variational Autoencoder-architectuur. Afbeelding door auteur
Door hun probabilistische aard hebben VAEs een aanzienlijk breder toepassingsgebied dan traditionele autoencoders. Traditionele autoencoders zijn daarentegen zeer effectief in toepassingen waar een deterministische datarepresentatie volstaat.
Laten we enkele toepassingen van beide bekijken om dit punt te verduidelijken.
VAEs zijn geëvolueerd naar verschillende gespecialiseerde vormen om uiteenlopende uitdagingen en toepassingen in machine learning aan te pakken. In deze sectie bekijken we de meest prominente typen, met hun use-cases, voordelen en beperkingen.
Conditionele Variational Autoencoders (CVAEs) zijn een gespecialiseerde vorm van VAEs die het generatieve proces verbeteren door te conditioneren op extra informatie.
Een VAE wordt conditioneel door aanvullende informatie, aangeduid als c, op te nemen in zowel de encoder- als decodernetwerken. Deze conditionerende informatie kan elke relevante data zijn, zoals klasselabels, attributen of andere contextuele data.
CVAE-modelstructuur. Afbeelding bron.
Use-cases van CVAEs zijn onder meer:
De voor- en nadelen zijn:
Disentangled Variational Autoencoders, vaak Beta-VAEs genoemd, zijn een ander type gespecialiseerde VAEs. Ze streven ernaar latente representaties te leren waarbij elke dimensie een afzonderlijke en interpreteerbare variatiefactor in de data vastlegt. Dit wordt bereikt door het oorspronkelijke VAE-doel aan te passen met een hyperparameter β die het evenwicht regelt tussen de reconstructieverlies en de KL-divergentieterm.
Voor- en nadelen van Beta-VAEs:
Een andere variant van VAEs is Adversarial Autoencoders (AAEs). AAEs combineren het VAE-raamwerk met adversarial training uit Generative Adversarial Networks (GANs). Een extra discriminerend netwerk zorgt ervoor dat de latente representaties overeenkomen met een priorverdeling, wat de generatieve capaciteiten van het model vergroot.
Voor- en nadelen van AAEs:
Nu bekijken we nog twee uitbreidingen van Variational Autoencoders.
De eerste is Variational Recurrent Autoencoders (VRAEs). VRAEs breiden het VAE-raamwerk uit naar sequentiële data door recurrente neurale netwerken (RNNs) in de encoder- en decodernetwerken op te nemen. Hierdoor kunnen VRAEs temporele afhankelijkheden vastleggen en sequentiële patronen modelleren.
Voor- en nadelen van VRAEs:
De laatste variant die we bekijken is Hiërarchische Variational Autoencoders (HVAEs). HVAEs introduceren meerdere lagen van latente variabelen in een hiërarchische structuur, waardoor het model complexere afhankelijkheden en abstracties in de data kan vastleggen.
Voor- en nadelen van HVAEs:
In deze sectie implementeren we een eenvoudige Variational Autoencoder (VAE) met PyTorch.
Om een VAE te implementeren, moeten we onze Python-omgeving instellen met de benodigde libraries en tools. De libraries die we gebruiken zijn:
Hier is de code om deze libraries te installeren:
pip install torch torchvision matplotlib numpyLaten we de implementatie van een VAE stap voor stap doornemen. Eerst importeren we de libraries:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as npVervolgens definiëren we de encoder, decoder en VAE. Hier is de code:
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
h = torch.relu(self.fc1(z))
x_hat = torch.sigmoid(self.fc2(h))
return x_hat
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
mu, logvar = self.encoder(x)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = mu + eps * std
x_hat = self.decoder(z)
return x_hat, mu, logvarWe moeten ook de verliesfunctie definiëren. De verliesfunctie voor VAEs bestaat uit een reconstructieverlies en een KL-divergentieverlies. Zo ziet dat eruit in PyTorch:
def loss_function(x, x_hat, mu, logvar):
BCE = nn.functional.binary_cross_entropy(x_hat, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLDOm de VAE te trainen laden we de MNIST-dataset, definiëren we de optimizer en trainen we het model.
# Hyperparameters
input_dim = 784
hidden_dim = 400
latent_dim = 20
lr = 1e-3
batch_size = 128
epochs = 10
# Data loader
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Model, optimizer
vae = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(vae.parameters(), lr=lr)
# Training loop
vae.train()
for epoch in range(epochs):
train_loss = 0
for x, _ in train_loader:
x = x.view(-1, input_dim)
optimizer.zero_grad()
x_hat, mu, logvar = vae(x)
loss = loss_function(x, x_hat, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset)}")Na het trainen kunnen we de VAE evalueren door de gereconstrueerde outputs en de gegenereerde samples te visualiseren.
Dit is de code:
# visualizing reconstructed outputs
vae.eval()
with torch.no_grad():
x, _ = next(iter(train_loader))
x = x.view(-1, input_dim)
x_hat, _, _ = vae(x)
x = x.view(-1, 28, 28)
x_hat = x_hat.view(-1, 28, 28)
fig, axs = plt.subplots(2, 10, figsize=(15, 3))
for i in range(10):
axs[0, i].imshow(x[i].cpu().numpy(), cmap='gray')
axs[1, i].imshow(x_hat[i].cpu().numpy(), cmap='gray')
axs[0, i].axis('off')
axs[1, i].axis('off')
plt.show()
#visualizing generated samples
with torch.no_grad():
z = torch.randn(10, latent_dim)
sample = vae.decoder(z)
sample = sample.view(-1, 28, 28)
fig, axs = plt.subplots(1, 10, figsize=(15, 3))
for i in range(10):
axs[i].imshow(sample[i].cpu().numpy(), cmap='gray')
axs[i].axis('off')
plt.show()
Visualisatie van outputs. De bovenste rij is de originele MNIST-data, de middelste rij de gereconstrueerde outputs en de onderste rij de gegenereerde samples—afbeelding door auteur.
Hoewel Variational Autoencoders (VAEs) krachtige tools zijn voor generatief modelleren, kennen ze verschillende uitdagingen en beperkingen die hun prestaties kunnen beïnvloeden. Laten we er een paar bespreken en mitigerende strategieën geven.
Dit is een fenomeen waarbij de VAE er niet in slaagt de volledige diversiteit van de dataverdeling vast te leggen. Het resultaat is dat gegenereerde samples slechts een paar modes (onderscheidbare regio’s) van de dataverdeling vertegenwoordigen en andere negeren. Dit leidt tot een gebrek aan variatie in de gegenereerde outputs.
Mode collapse wordt veroorzaakt door:
Mode collapse kan worden verminderd door gebruik te maken van:
In sommige gevallen kan de latente ruimte die door een VAE is geleerd niet-informatief worden, waarbij het model de latente variabelen niet effectief gebruikt om betekenisvolle kenmerken van de inputdata vast te leggen. Dit kan resulteren in een lagere kwaliteit van gegenereerde samples en reconstructies.
Dit gebeurt meestal om de volgende redenen:
Niet-informatieve latente ruimtes kunnen worden verholpen met een warm-up-strategie, waarbij het gewicht van de KL-divergentie tijdens het trainen geleidelijk wordt verhoogd, of door het gewicht van de KL-divergentieterm in de verliesfunctie direct aan te passen.
Het trainen van VAEs kan soms instabiel zijn, waarbij de verliesfunctie oscilleert of divergeert. Dit kan het moeilijk maken om te convergeren en een goed getraind model te verkrijgen.
Dit gebeurt doordat:
Stappen om trainingsinstabiliteit te beperken zijn onder andere:
Het trainen van VAEs, zeker met grote en complexe datasets, kan rekenintensief zijn. Dit komt door de noodzaak van sampelen en backpropagatie door stochastische lagen.
Oorzaken van hoge rekenkosten zijn onder meer:
Dit zijn enkele mitigerende acties:
Variational Autoencoders (VAEs) zijn een baanbrekende stap in de wereld van machine learning en datageneratie.
Door probabilistische elementen te introduceren in het traditionele autoencoder-raamwerk, maken VAEs de generatie van nieuwe, hoogwaardige data mogelijk en bieden ze een meer gestructureerde en continue latente ruimte. Deze unieke mogelijkheid heeft een breed scala aan toepassingen geopend, van generatief modelleren en anomaliedetectie tot data-imputatie en semi-supervised learning.
In dit artikel hebben we de basis van Variational Autoencoders behandeld, de verschillende typen, hoe je VAEs in PyTorch implementeert, en de uitdagingen en oplossingen bij het werken met VAEs.
Bekijk deze resources om verder te leren:
Leer meer over AI met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
