
Kurs
Einführung in Deep Learning mit PyTorch
4 Std.
85.8K
Da sich die Technologie des maschinellen Lernens in einem beispiellosen Tempo weiterentwickelt, revolutionieren Variational Autoencoders (VAEs) die Art und Weise, wie wir Daten verarbeiten und erzeugen. Durch die Verbindung von leistungsstarker Datenkodierung mit innovativen generativen Fähigkeiten bieten VAEs transformative Lösungen für komplexe Herausforderungen in der Praxis.
In diesem Artikel erkunden wir Schritt für Schritt die Kernkonzepte hinter VAEs, ihre Anwendungen und wie sie mit PyTorch effektiv umgesetzt werden können.
Autoencoder sind eine Art neuronales Netzwerk, das entwickelt wurde, um effiziente Datenrepräsentationen zu lernen, vor allem zum Zweck der Dimensionalitätsreduktion oder des Merkmalslernens.
Autoencoder bestehen aus zwei Hauptbestandteilen:
Das Hauptziel von Autoencodern ist es, die Differenz zwischen der Eingabe und der rekonstruierten Ausgabe zu minimieren und so eine kompakte Darstellung der Daten zu lernen.
Hier kommen die Variational Autoencoders (VAEs) ins Spiel, die die Möglichkeiten des traditionellen Autoencoders erweitern, indem sie probabilistische Elemente in den Codierungsprozess einbeziehen.
Während Standard-Autocodierer Eingaben auf feste latente Repräsentationen abbilden, verwenden VAEs einen probabilistischen Ansatz, bei dem der Codierer eine Verteilung über den latenten Raum ausgibt, die in der Regel als multivariater Gauß modelliert wird. Dadurch können die VAEs während des Dekodierungsprozesses aus dieser Verteilung Stichproben ziehen, was zur Erzeugung neuer Dateninstanzen führt.
Die wichtigste Innovation der VAEs liegt in ihrer Fähigkeit, neue, qualitativ hochwertige Daten zu generieren, indem sie einen strukturierten, kontinuierlichen latenten Raum lernen. Dies ist besonders wichtig für die generative Modellierung, bei der es nicht nur darum geht, Daten zu komprimieren, sondern neue Datenmuster zu erstellen, die dem ursprünglichen Datensatz ähneln.
VAEs haben sich bei Aufgaben wie der Bildsynthese, der Datenentrauschung und der Erkennung von Anomalien als sehr effektiv erwiesen und sind daher ein wichtiges Instrument, um die Fähigkeiten von Modellen und Anwendungen des maschinellen Lernens zu verbessern.
In diesem Abschnitt stellen wir dir den theoretischen Hintergrund und die Funktionsweise von VAEs vor, damit du eine solide Grundlage für die Erkundung ihrer Anwendungen in den folgenden Abschnitten hast.
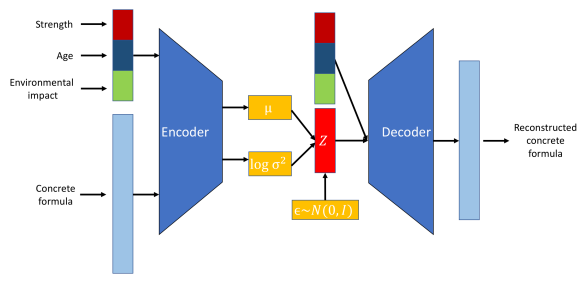
Beginnen wir mit den Encodern. Der Encoder ist ein neuronales Netzwerk, das die Eingangsdaten auf einen latenten Raum abbildet. Im Gegensatz zu traditionellen Autokodierern, die einen festen Punkt im latenten Raum erzeugen, gibt der Kodierer in einer VAE die Parameter einer Wahrscheinlichkeitsverteilung aus - in der Regel den Mittelwert und die Varianz einer Gauß-Verteilung. So kann die VAE die Unsicherheit und Variabilität der Daten effektiv modellieren.
Ein weiteres neuronales Netzwerk, der Decoder, wird verwendet, um die ursprünglichen Daten aus der latenten Raumdarstellung zu rekonstruieren. Bei einer Stichprobe aus der latenten Raumverteilung zielt der Decoder darauf ab, eine Ausgabe zu erzeugen, die den ursprünglichen Eingabedaten sehr ähnlich ist. Dieser Prozess ermöglicht es der VAE, neue Dateninstanzen durch Stichproben aus der gelernten Verteilung zu erstellen.
Der latente Raum ist ein niederdimensionaler, kontinuierlicher Raum, in dem die Eingabedaten kodiert werden.
Visualisierung der Rolle von Encoder, Decoder und latentem Raum. Bildquelle.
Der Variationsansatz ist eine Technik, mit der komplexe Wahrscheinlichkeitsverteilungen angenähert werden können. Im Zusammenhang mit VAEs geht es um die Annäherung der wahren posterioren Verteilung der latenten Variablen anhand der Daten, was oft schwierig ist.
Die VAE lernt eine ungefähre Posterior-Verteilung. Das Ziel ist es, diese Annäherung so nah wie möglich an das wahre Posterior zu bringen.
Die Bayes'sche Inferenz ist eine Methode zur Aktualisierung der Wahrscheinlichkeitsschätzung für eine Hypothese, wenn mehr Beweise oder Informationen verfügbar werden. Bei VAEs wird die Bayes'sche Inferenz verwendet, um die Verteilung der latenten Variablen zu schätzen.
Durch die Integration von Vorwissen (prior distribution) mit den beobachteten Daten (likelihood) passen VAEs die latente Raumdarstellung durch die gelernte posterior distribution an.
Bayes'sche Inferenz mit einer Prior-Verteilung, einer Posterior-Verteilung und einer Likelihood-Funktion. Bildquelle.
So sieht der Prozessablauf aus:
Untersuchen wir die Unterschiede und Vorteile von VAEs im Vergleich zu traditionellen Autokodierern.
Wie wir bereits gesehen haben, bestehen herkömmliche Autoencoder aus einem Encodernetzwerk, das die Eingabedaten x auf eine feste, niedrigdimensionale latente Raumdarstellung z abbildet. Dieser Prozess ist deterministisch, d.h. jede Eingabe wird in einen bestimmten Punkt im latenten Raum kodiert.
Das Decoder-Netzwerk rekonstruiert dann die ursprünglichen Daten aus dieser festen latenten Repräsentation und versucht dabei, die Differenz zwischen der Eingabe und der Rekonstruktion zu minimieren.
Der latente Raum traditioneller Autocoder ist eine komprimierte Darstellung der Eingabedaten ohne probabilistische Modellierung, was ihre Fähigkeit einschränkt, neue, vielfältige Daten zu generieren, da ihnen ein Mechanismus zum Umgang mit Unsicherheit fehlt.
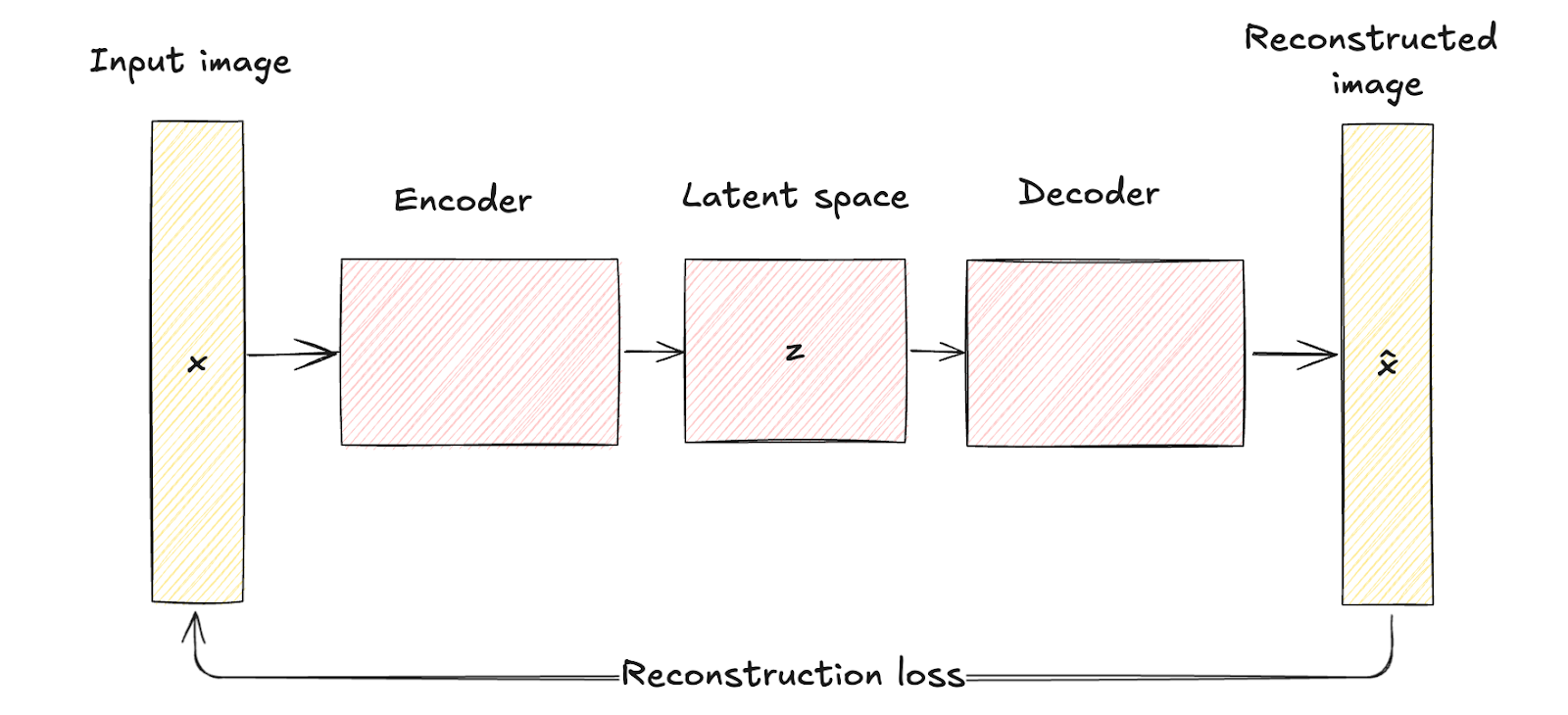
Autoencoder-Architektur. Bild vom Autor
VAEs bringen ein probabilistisches Element in den Kodierungsprozess ein. Der Encoder in einer VAE bildet die Eingabedaten auf eine Wahrscheinlichkeitsverteilung über die latenten Variablen ab, die typischerweise als Gauß-Verteilung mit dem Mittelwert modelliert wird. μ und Varianz σ2.
Bei diesem Ansatz wird jede Eingabe nicht als ein einzelner Punkt, sondern als eine Verteilung kodiert, wodurch eine zusätzliche Ebene der Variabilität und Unsicherheit entsteht.
Die architektonischen Unterschiede werden visuell durch die deterministische Zuordnung in traditionellen Autocodierern und die probabilistische Codierung und Abtastung in VAEs dargestellt.
Dieser strukturelle Unterschied verdeutlicht, wie VAEs die Regularisierung durch einen Begriff, der als KL-Divergenz bekannt ist, einbeziehen und so den latenten Raum als kontinuierlich und gut strukturiert gestalten.
Die eingeführte Regularisierung verbessert die Qualität und Kohärenz der erzeugten Stichproben erheblich und übertrifft damit die Fähigkeiten herkömmlicher Autokodierer.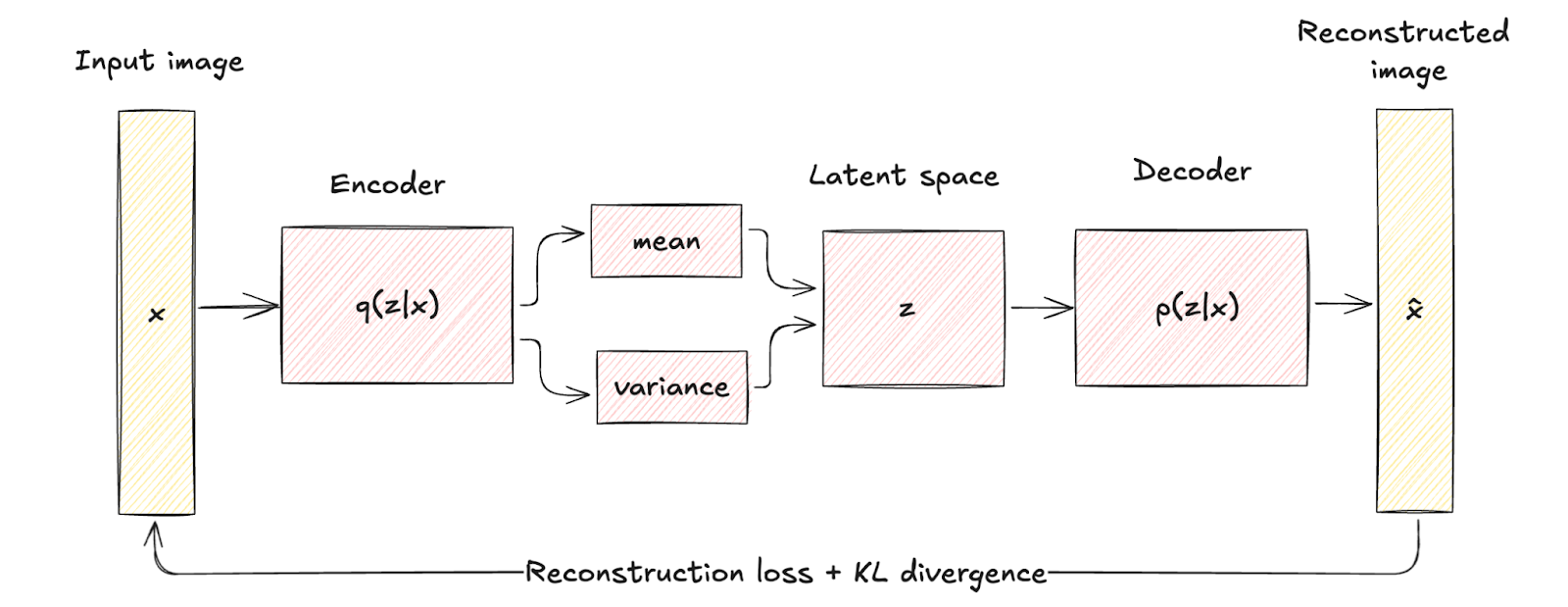
Variationale Autoencoder-Architektur. Bild vom Autor
Die probabilistische Natur der VAEs erweitert ihr Anwendungsspektrum im Vergleich zu den traditionellen Autoencodern erheblich. Im Gegensatz dazu sind herkömmliche Autoencoder sehr effektiv in Anwendungen, bei denen eine deterministische Datendarstellung ausreicht.
Schauen wir uns ein paar Anwendungen an, um diesen Punkt zu verdeutlichen.
VAEs haben sich zu verschiedenen spezialisierten Formen entwickelt, um unterschiedliche Herausforderungen und Anwendungen im maschinellen Lernen zu bewältigen. In diesem Abschnitt gehen wir auf die wichtigsten Arten ein und zeigen Anwendungsfälle, Vorteile und Grenzen auf.
Conditional Variational Autoencoders (CVAEs) sind eine spezielle Form von VAEs, die den generativen Prozess durch die Berücksichtigung zusätzlicher Informationen verbessern.
Eine VAE wird bedingt, indem zusätzliche Informationen, bezeichnet als c, sowohl in das Encoder- als auch in das Decoder-Netzwerk integriert werden. Diese Konditionierungsinformationen können alle relevanten Daten sein, wie z.B. Klassenlabels, Attribute oder andere Kontextdaten.
Struktur des CVAE-Modells. Bildquelle.
Zu den Anwendungsfällen von CVAEs gehören:
Die Vor- und Nachteile sind:
Entwirrte Variationale Autoencoder, auch Beta-VAEs genannt, sind eine weitere Art von spezialisierten VAEs. Sie zielen darauf ab, latente Repräsentationen zu erlernen, bei denen jede Dimension einen eindeutigen und interpretierbaren Faktor der Variation in den Daten abbildet. Dies wird erreicht, indem das ursprüngliche VAE-Ziel mit einem Hyperparameter β modifiziert wird, der den Rekonstruktionsverlust und den KL-Divergenzterm ausgleicht.
Vor- und Nachteile von Beta-VAEs:
Eine weitere Variante von VAEs sind Adversarial Autoencoders (AAEs). AAEs kombinieren das VAE-Framework mit den Prinzipien der Generativen Adversariellen Netze (GANs). Ein zusätzliches Diskriminatorennetzwerk stellt sicher, dass die latenten Repräsentationen mit einer Prioritätsverteilung übereinstimmen, wodurch die generativen Fähigkeiten des Modells verbessert werden.
Vor- und Nachteile von AAEs:
Jetzt werden wir uns zwei weitere Erweiterungen von Variations-Autoencodern ansehen.
Die erste ist Variational Recurrent Autoencoders (VRAEs). VRAEs erweitern den VAE-Rahmen auf sequentielle Daten, indem sie rekurrente neuronale Netze (RNNs) in die Encoder- und Decoder-Netzwerke einbeziehen. So können VRAEs zeitliche Abhängigkeiten erfassen und sequenzielle Muster modellieren.
Vor- und Nachteile von VRAEs:
Die letzte Variante, die wir untersuchen werden, ist Hierarchische Variations Autoencoder (HVAEs). HVAEs führen mehrere Schichten von latenten Variablen ein, die in einer hierarchischen Struktur angeordnet sind, wodurch das Modell komplexere Abhängigkeiten und Abstraktionen in den Daten erfassen kann.
Vor- und Nachteile von HVAEs:
In diesem Abschnitt werden wir einen einfachen Variational Autoencoder (VAE) mit PyTorch implementieren.
Um eine VAE zu implementieren, müssen wir unsere Python-Umgebung mit den notwendigen Bibliotheken und Tools einrichten. Die Bibliotheken, die wir verwenden werden, sind:
Hier ist der Code, um diese Bibliotheken zu installieren:
pip install torch torchvision matplotlib numpyGehen wir die Umsetzung einer VAE Schritt für Schritt durch. Zuerst müssen wir die Bibliotheken importieren:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as npAls Nächstes müssen wir den Encoder, den Decoder und die VAE definieren. Hier ist der Code:
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
h = torch.relu(self.fc1(z))
x_hat = torch.sigmoid(self.fc2(h))
return x_hat
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
mu, logvar = self.encoder(x)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = mu + eps * std
x_hat = self.decoder(z)
return x_hat, mu, logvarWir müssen auch die Verlustfunktion definieren. Die Verlustfunktion für VAEs besteht aus einem Rekonstruktionsverlust und einem KL-Divergenzverlust. So sieht es in PyTorch aus:
def loss_function(x, x_hat, mu, logvar):
BCE = nn.functional.binary_cross_entropy(x_hat, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLDUm die VAE zu trainieren, laden wir den MNIST-Datensatz, definieren den Optimierer und trainieren das Modell.
# Hyperparameters
input_dim = 784
hidden_dim = 400
latent_dim = 20
lr = 1e-3
batch_size = 128
epochs = 10
# Data loader
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Model, optimizer
vae = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(vae.parameters(), lr=lr)
# Training loop
vae.train()
for epoch in range(epochs):
train_loss = 0
for x, _ in train_loader:
x = x.view(-1, input_dim)
optimizer.zero_grad()
x_hat, mu, logvar = vae(x)
loss = loss_function(x, x_hat, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset)}")Nach dem Training können wir die VAE bewerten, indem wir die rekonstruierten Ausgaben und die erzeugten Proben visualisieren.
Das ist der Code:
# visualizing reconstructed outputs
vae.eval()
with torch.no_grad():
x, _ = next(iter(train_loader))
x = x.view(-1, input_dim)
x_hat, _, _ = vae(x)
x = x.view(-1, 28, 28)
x_hat = x_hat.view(-1, 28, 28)
fig, axs = plt.subplots(2, 10, figsize=(15, 3))
for i in range(10):
axs[0, i].imshow(x[i].cpu().numpy(), cmap='gray')
axs[1, i].imshow(x_hat[i].cpu().numpy(), cmap='gray')
axs[0, i].axis('off')
axs[1, i].axis('off')
plt.show()
#visualizing generated samples
with torch.no_grad():
z = torch.randn(10, latent_dim)
sample = vae.decoder(z)
sample = sample.view(-1, 28, 28)
fig, axs = plt.subplots(1, 10, figsize=(15, 3))
for i in range(10):
axs[i].imshow(sample[i].cpu().numpy(), cmap='gray')
axs[i].axis('off')
plt.show()
Visualisierung der Ergebnisse. Die oberste Reihe sind die ursprünglichen MNIST-Daten, die mittlere Reihe die rekonstruierten Ergebnisse und die letzte Reihe das vom Autor erstellte Musterbild.
Variationale Autoencoder (VAEs) sind zwar leistungsstarke Werkzeuge für die generative Modellierung, aber sie haben auch einige Herausforderungen und Einschränkungen, die ihre Leistung beeinträchtigen können. Wir wollen einige davon besprechen und Strategien zur Abhilfe aufzeigen.
Dies ist ein Phänomen, bei dem die VAE nicht die gesamte Vielfalt der Datenverteilung erfasst. Das Ergebnis sind Stichproben, die nur einige wenige Modi (unterschiedliche Regionen) der Datenverteilung repräsentieren, während andere ignoriert werden. Das führt zu einem Mangel an Vielfalt bei den erzeugten Ergebnissen.
Moduszusammenbruch verursacht durch:
Der Zusammenbruch des Modus kann durch die Verwendung von:
In einigen Fällen kann der von einer VAE gelernte latente Raum uninformativ werden, wenn das Modell die latenten Variablen nicht effektiv nutzt, um sinnvolle Merkmale der Eingabedaten zu erfassen. Dies kann zu einer schlechten Qualität der erzeugten Proben und Rekonstruktionen führen.
Dies geschieht in der Regel aus den folgenden Gründen:
Uninformative latente Räume können durch die Warm-up-Strategie behoben werden, bei der das Gewicht der KL-Divergenz während des Trainings schrittweise erhöht wird, oder indem das Gewicht des KL-Divergenz-Terms in der Verlustfunktion direkt verändert wird.
Trainings-VAEs können manchmal instabil sein, wenn die Verlustfunktion oszilliert oder divergiert. Das kann es schwierig machen, Konvergenz zu erreichen und ein gut trainiertes Modell zu erhalten.
Der Grund dafür ist, dass:
Um die Instabilität der Ausbildung abzumildern, musst du entweder
Das Trainieren von VAEs, insbesondere bei großen und komplexen Datensätzen, kann sehr rechenintensiv sein. Das liegt an der Notwendigkeit von Sampling und Backpropagation durch stochastische Schichten.
Zu den Ursachen für hohe Rechenkosten gehören:
Dies sind einige Maßnahmen zur Schadensbegrenzung:
Variationale Autoencoder (VAEs) haben sich als bahnbrechender Fortschritt auf dem Gebiet des maschinellen Lernens und der Datengenerierung erwiesen.
Durch die Einführung probabilistischer Elemente in den traditionellen Autoencoder-Rahmen ermöglichen VAEs die Generierung neuer, hochwertiger Daten und bieten einen strukturierteren und kontinuierlichen latenten Raum. Diese einzigartige Fähigkeit hat eine breite Palette von Anwendungen eröffnet, von generativer Modellierung und Anomalieerkennung bis hin zu Datenimprognosen und semi-supervised learning.
In diesem Artikel haben wir die Grundlagen von Variational Autoencoders, die verschiedenen Typen, die Implementierung von VAEs in PyTorch sowie die Herausforderungen und Lösungen bei der Arbeit mit VAEs behandelt.
Schau dir diese Ressourcen an, um dein Wissen zu erweitern:
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Lerne mehr über KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Mark Pedigo
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal