Curso
Introdução ao Aprendizado Profundo com o PyTorch
4 h
85.8K
À medida que a tecnologia de machine learning avança em um ritmo sem precedentes, os Autoencoders Variacionais (VAEs) estão revolucionando a forma como processamos e geramos dados. Ao combinar a poderosa codificação de dados com recursos geradores inovadores, os VAEs oferecem soluções transformadoras para desafios complexos no campo.
Neste artigo, exploraremos passo a passo os principais conceitos por trás dos VAEs, suas aplicações e como eles podem ser implementados de forma eficaz usando o PyTorch.
Os autoencodificadores são um tipo de rede neural projetada para aprender representações de dados eficientes, principalmente para fins de redução de dimensionalidade ou aprendizado de recursos.
Os codificadores automáticos consistem em duas partes principais:
O principal objetivo dos autoencodificadores é minimizar a diferença entre a entrada e a saída reconstruída, aprendendo assim uma representação compacta dos dados.
Você pode usar os Autoencoders Variacionais (VAEs), que ampliam os recursos da estrutura tradicional de autoencoders incorporando elementos probabilísticos ao processo de codificação.
Enquanto os codificadores automáticos padrão mapeiam as entradas para representações latentes fixas, os VAEs introduzem uma abordagem probabilística em que o codificador gera uma distribuição sobre o espaço latente, normalmente modelado como um Gaussiano multivariado. Isso permite que os VAEs façam uma amostragem dessa distribuição durante o processo de decodificação, o que leva à geração de novas instâncias de dados.
A principal inovação dos VAEs está em sua capacidade de gerar dados novos e de alta qualidade por meio do aprendizado de um espaço latente estruturado e contínuo. Isso é particularmente importante para a modelagem generativa, em que o objetivo não é apenas comprimir dados, mas criar novas amostras de dados que se assemelhem ao conjunto de dados original.
Os VAEs demonstraram eficácia significativa em tarefas como síntese de imagens, redução de ruído de dados e detecção de anomalias, o que os torna ferramentas relevantes para o avanço dos recursos dos modelos e aplicativos de machine learning.
Nesta seção, apresentaremos os fundamentos teóricos e a mecânica operacional dos VAEs, fornecendo a você uma base sólida para explorar suas aplicações nas seções posteriores.
Vamos começar com os codificadores. O codificador é uma rede neural responsável pelo mapeamento dos dados de entrada em um espaço latente. Diferentemente dos codificadores automáticos tradicionais que produzem um ponto fixo no espaço latente, o codificador em um VAE gera parâmetros de uma distribuição de probabilidade - normalmente a média e a variação de uma distribuição gaussiana. Isso permite que o VAE modele a incerteza e a variabilidade dos dados de forma eficaz.
Outra rede neural, chamada decodificador, é usada para reconstruir os dados originais a partir da representação do espaço latente. Dada uma amostra da distribuição do espaço latente, o decodificador tem como objetivo gerar uma saída que se assemelhe aos dados de entrada originais. Esse processo permite que o VAE crie novas instâncias de dados por amostragem a partir da distribuição aprendida.
O espaço latente é um espaço contínuo e de dimensão inferior no qual os dados de entrada são codificados.
Visualização da função do codificador, do decodificador e do espaço latente. Fonte da imagem.
A abordagem variacional é uma técnica usada para aproximar distribuições de probabilidade complexas. No contexto dos VAEs, isso envolve a aproximação da distribuição posterior verdadeira de variáveis latentes com base nos dados, o que geralmente é difícil de ser feito.
O VAE aprende uma distribuição posterior aproximada. O objetivo é fazer com que essa aproximação seja a mais próxima possível do verdadeiro posterior.
A inferência bayesiana é um método de atualização da estimativa de probabilidade de uma hipótese à medida que mais evidências ou informações se tornam disponíveis. Nos VAEs, a inferência bayesiana é usada para estimar a distribuição de variáveis latentes.
Ao integrar o conhecimento prévio (distribuição prévia) com os dados observados (probabilidade), os VAEs ajustam a representação do espaço latente por meio da distribuição posterior aprendida.
Inferência bayesiana com uma distribuição prévia, distribuição posterior e função de verossimilhança. Fonte da imagem.
Aqui está a aparência do fluxo do processo:
Vamos examinar as diferenças e as vantagens dos VAEs em relação aos codificadores automáticos tradicionais.
Como visto anteriormente, os codificadores automáticos tradicionais consistem em uma rede codificadora que mapeia os dados de entrada x para uma representação de espaço latente fixa e de dimensão inferior z. Esse processo é determinístico, o que significa que cada entrada é codificada em um ponto específico no espaço latente.
Em seguida, a rede do decodificador reconstrói os dados originais a partir dessa representação latente fixa, com o objetivo de minimizar a diferença entre a entrada e sua reconstrução.
O espaço latente dos autoencodificadores tradicionais é uma representação comprimida dos dados de entrada sem qualquer modelagem probabilística, o que limita sua capacidade de gerar dados novos e diversificados, já que eles não têm um mecanismo para lidar com a incerteza.
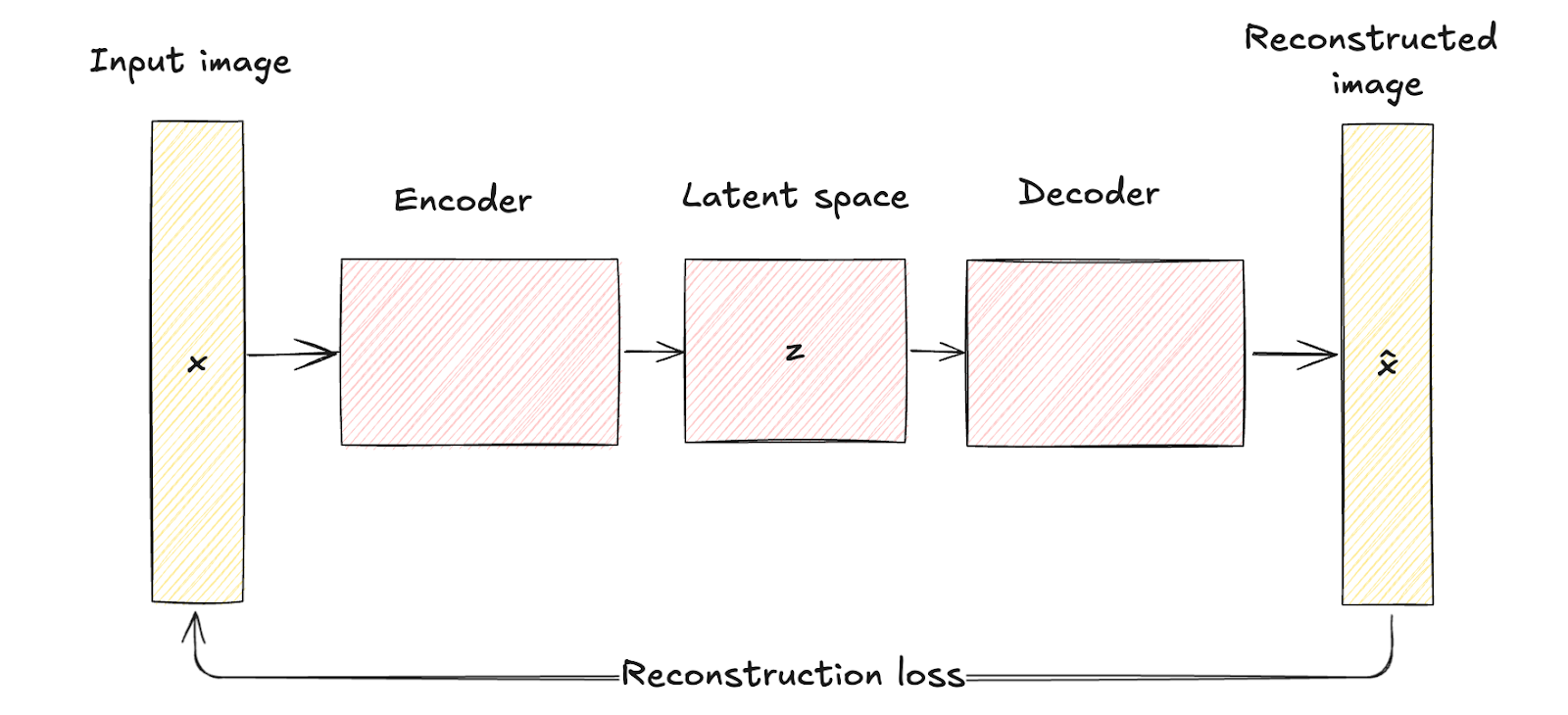
Arquitetura do codificador automático. Imagem do autor
Os VAEs introduzem um elemento probabilístico no processo de codificação. Ou seja, o codificador em uma VAE mapeia os dados de entrada para uma distribuição de probabilidade sobre as variáveis latentes, normalmente modeladas como uma distribuição gaussiana com média μ e variância σ2.
Essa abordagem codifica cada entrada em uma distribuição em vez de um único ponto, acrescentando uma camada de variabilidade e incerteza.
As diferenças arquitetônicas são visualmente representadas pelo mapeamento determinístico nos autoencodificadores tradicionais em comparação com a codificação probabilística e a amostragem nos VAEs.
Essa diferença estrutural destaca como os VAEs incorporam a regularização por meio de um termo conhecido como divergência KL, moldando o espaço latente para ser contínuo e bem estruturado.
A regularização introduzida aumenta significativamente a qualidade e a coerência das amostras geradas, superando os recursos dos autocodificadores tradicionais.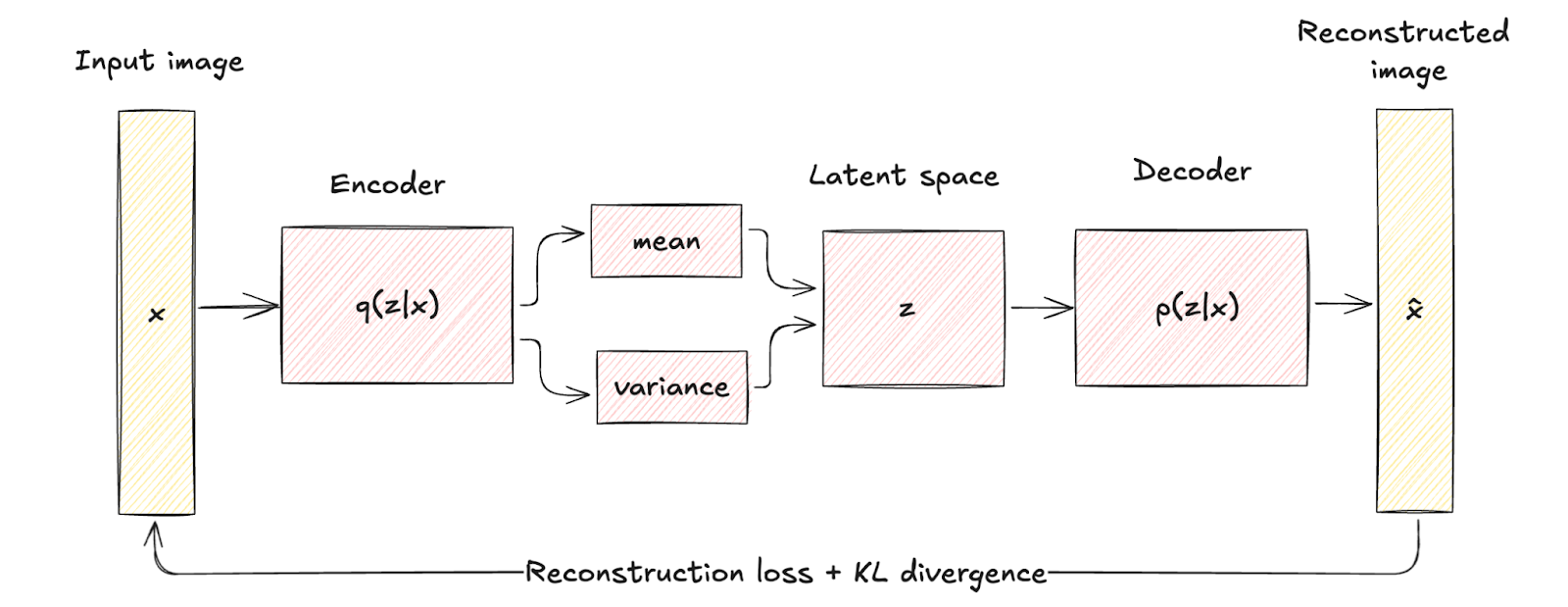
Arquitetura do codificador automático variacional. Imagem do autor
A natureza probabilística dos VAEs amplia significativamente sua gama de aplicações em comparação com os autoencodificadores tradicionais. Por outro lado, os autoencodificadores tradicionais são altamente eficazes em aplicações em que a representação determinística de dados é suficiente.
Vamos dar uma olhada em algumas aplicações de cada uma delas para que você entenda melhor esse ponto.
Os VAEs evoluíram para várias formas especializadas para lidar com diferentes desafios e aplicações em machine learning. Nesta seção, examinaremos os tipos mais proeminentes, destacando casos de uso, vantagens e limitações.
Os Autoencoders Variacionais Condicionais (CVAEs) são uma forma especializada de VAEs que aprimoram o processo generativo condicionando informações adicionais.
Um VAE torna-se condicional ao incorporar informações adicionais, denotadas como c, nas redes do codificador e do decodificador. Essas informações de condicionamento podem ser quaisquer dados relevantes, como rótulos de classe, atributos ou outros dados contextuais.
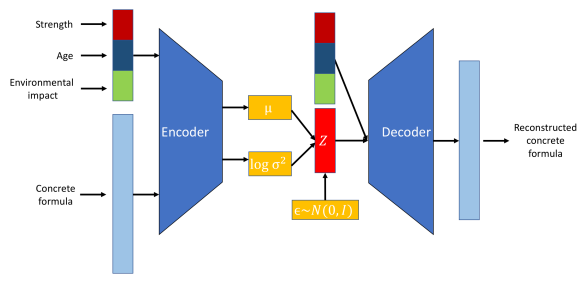
Estrutura do modelo CVAE. Fonte da imagem.
Os casos de uso de CVAEs incluem:
Os prós e contras são:
Autoencodificadores variacionais desemaranhados, geralmente chamados de Beta-VAEs, são outro tipo de VAEs especializados. Eles têm como objetivo aprender representações latentes em que cada dimensão captura um fator de variação distinto e interpretável nos dados. Isso é feito modificando o objetivo VAE original com um hiperparâmetro β que equilibra a perda de reconstrução e o termo de divergência KL.
Prós e contras dos Beta-VAEs:
Outra variante dos VAEs são os Autoencodificadores Adversariais (AAEs). Os AAEs combinam a estrutura do VAE com os princípios de treinamento contraditório das Redes Adversárias Generativas (GANs). Uma rede discriminadora adicional garante que as representações latentes correspondam a uma distribuição prévia, aprimorando os recursos de geração do modelo.
Prós e contras dos AAEs:
Agora, veremos mais duas extensões de Autoencodificadores Variacionais.
O primeiro é o Variational Recurrent Autoencoders (VRAEs). Os VRAEs estendem a estrutura do VAE para dados sequenciais, incorporando redes neurais recorrentes (RNNs) nas redes de codificador e decodificador. Isso permite que os VRAEs capturem dependências temporais e modelem padrões sequenciais.
Prós e contras dos VRAEs:
A última variante que examinaremos é a Variacional Hierárquico (HVAEs). Os HVAEs introduzem várias camadas de variáveis latentes organizadas em uma estrutura hierárquica, o que permite que o modelo capture dependências e abstrações mais complexas nos dados.
Prós e contras dos HVAEs:
Nesta seção, implementaremos um Autoencoder Variacional (VAE) simples usando o PyTorch.
Para implementar uma VAE, precisamos configurar nosso ambiente Python com as bibliotecas e ferramentas necessárias. As bibliotecas que usaremos são:
Aqui está o código para instalar essas bibliotecas:
pip install torch torchvision matplotlib numpyVamos analisar a implementação de um VAE passo a passo. Primeiro, precisamos importar as bibliotecas:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as npEm seguida, devemos definir o codificador, o decodificador e o VAE. Aqui está o código:
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
h = torch.relu(self.fc1(z))
x_hat = torch.sigmoid(self.fc2(h))
return x_hat
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
mu, logvar = self.encoder(x)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = mu + eps * std
x_hat = self.decoder(z)
return x_hat, mu, logvarTambém precisamos definir a função de perda. A função de perda para VAEs consiste em uma perda de reconstrução e uma perda de divergência KL. É assim que você vê no PyTorch:
def loss_function(x, x_hat, mu, logvar):
BCE = nn.functional.binary_cross_entropy(x_hat, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLDPara treinar o VAE, carregaremos o conjunto de dados MNIST, definiremos o otimizador e treinaremos o modelo.
# Hyperparameters
input_dim = 784
hidden_dim = 400
latent_dim = 20
lr = 1e-3
batch_size = 128
epochs = 10
# Data loader
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Model, optimizer
vae = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(vae.parameters(), lr=lr)
# Training loop
vae.train()
for epoch in range(epochs):
train_loss = 0
for x, _ in train_loader:
x = x.view(-1, input_dim)
optimizer.zero_grad()
x_hat, mu, logvar = vae(x)
loss = loss_function(x, x_hat, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset)}")Após o treinamento, podemos avaliar o VAE visualizando as saídas reconstruídas e as amostras geradas.
Este é o código:
# visualizing reconstructed outputs
vae.eval()
with torch.no_grad():
x, _ = next(iter(train_loader))
x = x.view(-1, input_dim)
x_hat, _, _ = vae(x)
x = x.view(-1, 28, 28)
x_hat = x_hat.view(-1, 28, 28)
fig, axs = plt.subplots(2, 10, figsize=(15, 3))
for i in range(10):
axs[0, i].imshow(x[i].cpu().numpy(), cmap='gray')
axs[1, i].imshow(x_hat[i].cpu().numpy(), cmap='gray')
axs[0, i].axis('off')
axs[1, i].axis('off')
plt.show()
#visualizing generated samples
with torch.no_grad():
z = torch.randn(10, latent_dim)
sample = vae.decoder(z)
sample = sample.view(-1, 28, 28)
fig, axs = plt.subplots(1, 10, figsize=(15, 3))
for i in range(10):
axs[i].imshow(sample[i].cpu().numpy(), cmap='gray')
axs[i].axis('off')
plt.show()
Visualização de resultados. Na linha superior estão os dados originais do MNIST, na linha do meio estão os resultados reconstruídos e na última linha estão as amostras-imagem geradas pelo autor.
Embora os Autoencoders Variacionais (VAEs) sejam ferramentas poderosas para modelagem generativa, eles apresentam vários desafios e limitações que podem afetar seu desempenho. Vamos discutir alguns deles e fornecer estratégias de atenuação.
Esse é um fenômeno em que o VAE não consegue capturar a diversidade total da distribuição de dados. O resultado são amostras geradas que representam apenas alguns modos (regiões distintas) da distribuição de dados, ignorando outros. Isso leva a uma falta de variedade nos resultados gerados.
Colapso do modo causado por:
O colapso do modo pode ser atenuado com o uso:
Em alguns casos, o espaço latente aprendido por um VAE pode se tornar não informativo, quando o modelo não usa efetivamente as variáveis latentes para capturar recursos significativos dos dados de entrada. Isso pode resultar em baixa qualidade das amostras e reconstruções geradas.
Isso geralmente acontece pelos seguintes motivos:
Espaços latentes não informativos podem ser corrigidos com a estratégia de aquecimento, que envolve o aumento gradual do peso da divergência KL durante o treinamento ou a modificação direta do peso do termo de divergência KL na função de perda.
Às vezes, os VAEs de treinamento podem ser instáveis, com a função de perda oscilando ou divergindo. Isso pode dificultar a convergência e a obtenção de um modelo bem treinado.
Isso ocorre porque:
As etapas para atenuar a instabilidade do treinamento envolvem o uso:
O treinamento de VAEs, especialmente com conjuntos de dados grandes e complexos, pode ser caro do ponto de vista computacional. Isso se deve à necessidade de amostragem e retropropagação por meio de camadas estocásticas.
As causas dos altos custos computacionais incluem:
Essas são algumas ações de mitigação:
Os Autoencoders Variacionais (VAEs) provaram ser um avanço inovador no campo do machine learning e da geração de dados.
Ao introduzir elementos probabilísticos na estrutura tradicional do autocodificador, os VAEs permitem a geração de dados novos e de alta qualidade e fornecem um espaço latente mais estruturado e contínuo. Esse recurso exclusivo abriu uma ampla gama de aplicações, desde modelagem generativa e detecção de anomalias até imputação de dados e aprendizado semissupervisionado.
Neste artigo, abordamos os fundamentos dos Autoencodificadores Variacionais, os diferentes tipos, como implementar VAEs no PyTorch, bem como os desafios e as soluções ao trabalhar com VAEs.
Confira estes recursos para que você continue aprendendo:
Saiba mais sobre IA com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
11 min
blog
DataCamp Team
4 min
blog
Javier Canales Luna
8 min
blog
Tutorial
Arjun Sarkar
Tutorial
Zoumana Keita



