
Courses
Nhập môn Deep Learning với PyTorch
4 giờ
87.7K
Khi công nghệ học máy phát triển với tốc độ chưa từng có, Variational Autoencoders (VAE) đang làm thay đổi cách chúng ta xử lý và tạo sinh dữ liệu. Bằng cách kết hợp khả năng mã hoá dữ liệu mạnh mẽ với năng lực tạo sinh đổi mới, VAE mang đến những giải pháp mang tính chuyển đổi cho các thách thức phức tạp trong lĩnh vực này.
Trong bài viết này, chúng ta sẽ khám phá các khái niệm cốt lõi đằng sau VAE, các ứng dụng của chúng, và cách triển khai hiệu quả bằng PyTorch theo từng bước.
Autoencoder là một loại mạng nơ-ron được thiết kế để học các biểu diễn dữ liệu hiệu quả, chủ yếu phục vụ mục đích giảm chiều dữ liệu hoặc học đặc trưng.
Autoencoder gồm hai phần chính:
Mục tiêu chính của autoencoder là giảm thiểu sự khác biệt giữa đầu vào và đầu ra được tái tạo, qua đó học một biểu diễn gọn nhẹ của dữ liệu.
Và đây là Variational Autoencoders (VAE), mở rộng khả năng của khung autoencoder truyền thống bằng cách đưa các yếu tố xác suất vào quá trình mã hoá.
Trong khi autoencoder tiêu chuẩn ánh xạ đầu vào tới các biểu diễn tiềm ẩn cố định, VAE đưa ra một cách tiếp cận xác suất, trong đó bộ mã hoá xuất ra một phân phối trên không gian tiềm ẩn, thường được mô hình hoá như một Gaussian đa biến. Điều này cho phép VAE lấy mẫu từ phân phối này trong quá trình giải mã, dẫn đến việc tạo ra các mẫu dữ liệu mới.
Đổi mới then chốt của VAE nằm ở khả năng tạo ra dữ liệu mới, chất lượng cao bằng cách học một không gian tiềm ẩn liên tục, có cấu trúc. Điều này đặc biệt quan trọng đối với mô hình tạo sinh, nơi mục tiêu không chỉ là nén dữ liệu mà còn tạo ra các mẫu mới tương tự với bộ dữ liệu gốc.
VAE đã chứng minh hiệu quả đáng kể trong các tác vụ như tổng hợp ảnh, khử nhiễu dữ liệu và phát hiện bất thường, khiến chúng trở thành công cụ hữu ích để nâng cao năng lực của các mô hình và ứng dụng học máy.
Trong phần này, chúng ta sẽ giới thiệu nền tảng lý thuyết và cơ chế hoạt động của VAE, cung cấp cho bạn cơ sở vững chắc để khám phá các ứng dụng ở những phần sau.
Bắt đầu với bộ mã hoá. Bộ mã hoá là một mạng nơ-ron chịu trách nhiệm ánh xạ dữ liệu đầu vào vào không gian tiềm ẩn. Khác với autoencoder truyền thống tạo ra một điểm cố định trong không gian tiềm ẩn, bộ mã hoá trong VAE xuất ra các tham số của một phân phối xác suất—thường là trung bình và phương sai của một phân phối Gaussian. Điều này cho phép VAE mô hình hoá sự bất định và biến thiên dữ liệu một cách hiệu quả.
Một mạng nơ-ron khác gọi là bộ giải mã được dùng để tái tạo dữ liệu gốc từ biểu diễn không gian tiềm ẩn. Với một mẫu lấy ra từ phân phối không gian tiềm ẩn, bộ giải mã nhằm tạo ra đầu ra giống với dữ liệu đầu vào ban đầu. Quá trình này cho phép VAE tạo các mẫu dữ liệu mới bằng cách lấy mẫu từ phân phối đã học.
Không gian tiềm ẩn là một không gian liên tục, số chiều thấp hơn, nơi dữ liệu đầu vào được mã hoá.
Minh hoạ vai trò của bộ mã hoá, bộ giải mã và không gian tiềm ẩn. Nguồn hình ảnh.
Cách tiếp cận biến phân (variational) là một kỹ thuật dùng để xấp xỉ các phân phối xác suất phức tạp. Trong ngữ cảnh VAE, nó liên quan đến việc xấp xỉ phân phối hậu nghiệm thực sự của các biến tiềm ẩn khi biết dữ liệu, vốn thường không thể tính tường minh.
VAE học một phân phối hậu nghiệm xấp xỉ. Mục tiêu là khiến xấp xỉ này càng gần hậu nghiệm thực càng tốt.
Suy luận Bayes là phương pháp cập nhật ước lượng xác suất cho một giả thuyết khi có thêm bằng chứng hay thông tin. Trong VAE, suy luận Bayes được dùng để ước lượng phân phối của các biến tiềm ẩn.
Bằng cách tích hợp tri thức tiên nghiệm (phân phối prior) với dữ liệu quan sát (likelihood), VAE điều chỉnh biểu diễn không gian tiềm ẩn thông qua phân phối hậu nghiệm đã học.
Suy luận Bayes với phân phối tiên nghiệm, hậu nghiệm và hàm hợp lý. Nguồn hình ảnh.
Quy trình hoạt động như sau:
Hãy xem xét các khác biệt và ưu thế của VAE so với autoencoder truyền thống.
Như đã thấy, autoencoder truyền thống gồm một mạng mã hoá ánh xạ dữ liệu đầu vào x tới một biểu diễn không gian tiềm ẩn cố định, có số chiều thấp hơn z. Quá trình này có tính quyết định (deterministic), nghĩa là mỗi đầu vào được mã hoá thành một điểm cụ thể trong không gian tiềm ẩn.
Mạng giải mã sau đó tái tạo dữ liệu gốc từ biểu diễn tiềm ẩn cố định này, nhằm giảm thiểu khác biệt giữa đầu vào và bản tái tạo.
Không gian tiềm ẩn của autoencoder truyền thống là một biểu diễn nén của dữ liệu đầu vào mà không có mô hình hoá xác suất, điều này hạn chế khả năng tạo dữ liệu mới, đa dạng do thiếu cơ chế xử lý bất định.
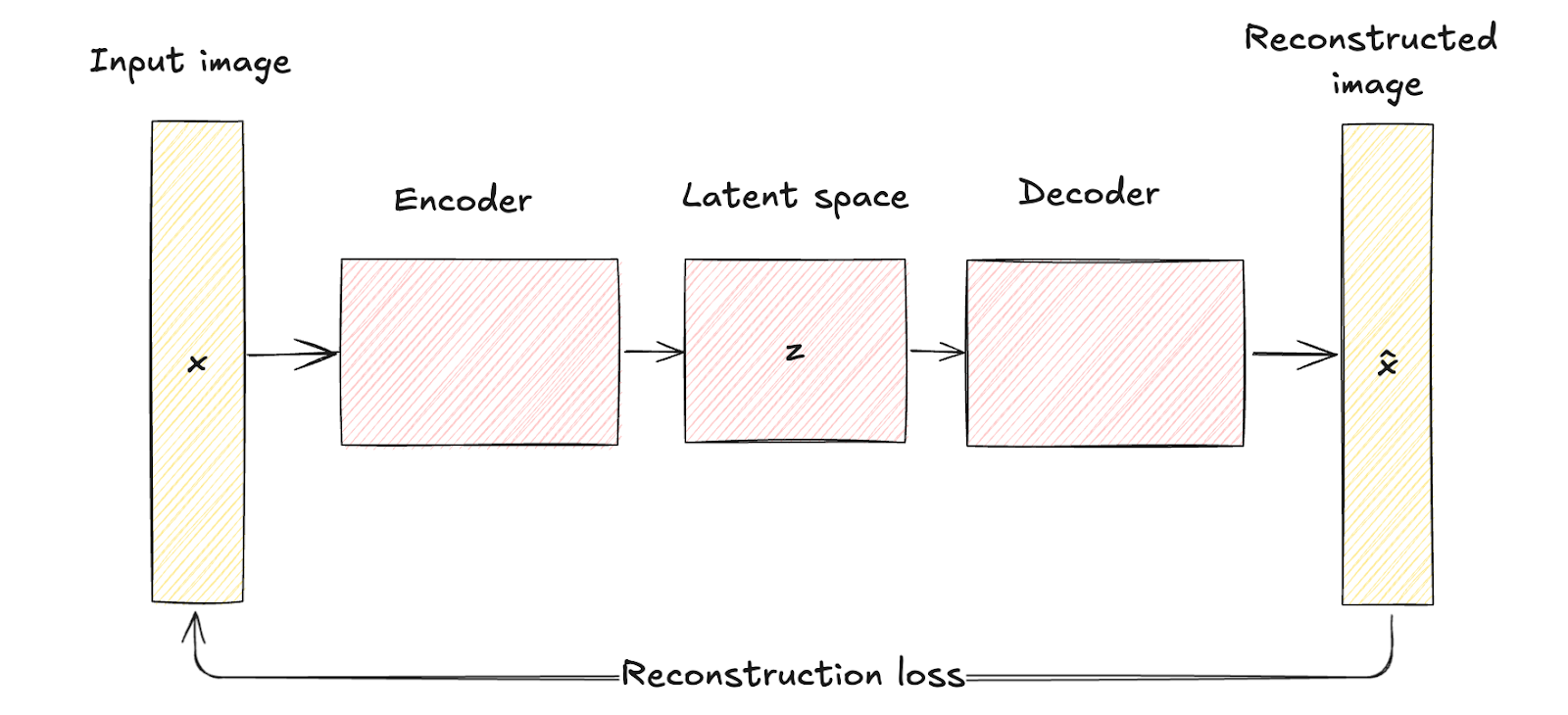
Kiến trúc autoencoder. Hình do tác giả cung cấp
VAE đưa yếu tố xác suất vào quá trình mã hoá. Cụ thể, bộ mã hoá trong VAE ánh xạ dữ liệu đầu vào tới một phân phối xác suất trên các biến tiềm ẩn, thường được mô hình hoá như phân phối Gaussian với trung bình μ và phương sai σ2.
Cách tiếp cận này mã hoá mỗi đầu vào thành một phân phối thay vì một điểm đơn lẻ, bổ sung lớp biến thiên và bất định.
Khác biệt kiến trúc được thể hiện qua ánh xạ quyết định ở autoencoder truyền thống so với mã hoá xác suất và lấy mẫu trong VAE.
Khác biệt cấu trúc này nhấn mạnh cách VAE đưa vào quy chuẩn hoá (regularization) thông qua một hạng mục gọi là phân kỳ KL (KL divergence), định hình không gian tiềm ẩn trở nên liên tục và có cấu trúc tốt.
Sự quy chuẩn hoá được đưa vào giúp nâng cao đáng kể chất lượng và tính mạch lạc của các mẫu được tạo ra, vượt trội so với autoencoder truyền thống.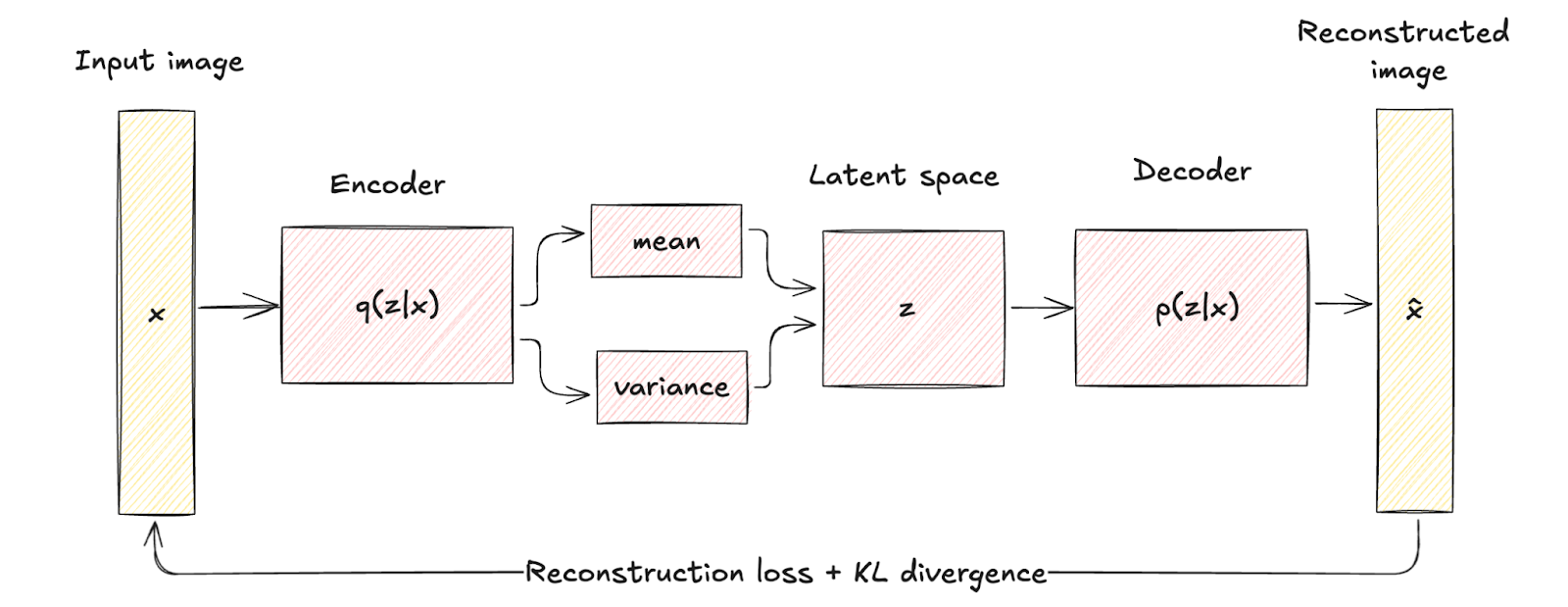
Kiến trúc Variational Autoencoder. Hình do tác giả cung cấp
Bản chất xác suất của VAE mở rộng đáng kể phạm vi ứng dụng so với autoencoder truyền thống. Ngược lại, autoencoder truyền thống rất hiệu quả trong các bài toán mà biểu diễn dữ liệu mang tính quyết định là đủ.
Hãy cùng xem một vài ứng dụng của mỗi loại để làm rõ điểm này.
VAE đã phát triển thành nhiều dạng chuyên biệt để giải quyết các thách thức và ứng dụng khác nhau trong học máy. Phần này, chúng ta sẽ xem xét những loại nổi bật nhất, nêu bật trường hợp sử dụng, ưu điểm và hạn chế.
Conditional Variational Autoencoders (CVAE) là một dạng chuyên biệt của VAE, tăng cường quá trình tạo sinh bằng cách điều kiện hoá trên thông tin bổ sung.
Một VAE trở thành có điều kiện bằng cách đưa thông tin bổ sung, ký hiệu là c, vào cả mạng mã hoá và giải mã. Thông tin điều kiện này có thể là bất kỳ dữ liệu liên quan nào, như nhãn lớp, thuộc tính hoặc dữ liệu ngữ cảnh khác.
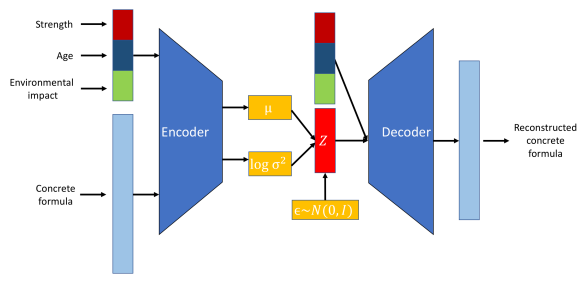
Cấu trúc mô hình CVAE. Nguồn.
Các trường hợp sử dụng của CVAE bao gồm:
Ưu và nhược điểm:
Disentangled Variational Autoencoders, thường gọi là Beta-VAE, là một loại VAE chuyên biệt khác. Chúng hướng tới việc học các biểu diễn tiềm ẩn mà mỗi chiều nắm bắt một yếu tố biến thiên riêng biệt, có thể diễn giải trong dữ liệu. Điều này đạt được bằng cách điều chỉnh mục tiêu VAE gốc với một siêu tham số β để cân bằng giữa mất mát tái tạo và hạng mục phân kỳ KL.
Ưu và nhược điểm của Beta-VAE:
Một biến thể khác của VAE là Adversarial Autoencoders (AAE). AAE kết hợp khung VAE với nguyên lý huấn luyện đối kháng từ Generative Adversarial Networks (GAN). Một mạng phân biệt bổ sung đảm bảo các biểu diễn tiềm ẩn khớp với phân phối prior, qua đó tăng cường khả năng tạo sinh của mô hình.
Ưu và nhược điểm của AAE:
Tiếp theo, chúng ta sẽ xem xét thêm hai phần mở rộng của Variational Autoencoders.
Đầu tiên là Variational Recurrent Autoencoders (VRAE). VRAE mở rộng khung VAE cho dữ liệu tuần tự bằng cách tích hợp mạng nơ-ron hồi quy (RNN) vào các mạng mã hoá và giải mã. Điều này cho phép VRAE nắm bắt phụ thuộc theo thời gian và mô hình hoá các mẫu tuần tự.
Ưu và nhược điểm của VRAE:
Biến thể cuối cùng chúng ta xem xét là Hierarchical Variational Autoencoders (HVAE). HVAE đưa vào nhiều tầng biến tiềm ẩn được sắp xếp theo cấu trúc phân cấp, cho phép mô hình nắm bắt các phụ thuộc và mức trừu tượng phức tạp hơn trong dữ liệu.
Ưu và nhược điểm của HVAE:
Trong phần này, chúng ta sẽ triển khai một Variational Autoencoder (VAE) đơn giản bằng PyTorch.
Để triển khai VAE, chúng ta cần thiết lập môi trường Python với các thư viện và công cụ cần thiết. Các thư viện sẽ sử dụng gồm:
Đây là mã để cài đặt các thư viện này:
pip install torch torchvision matplotlib numpyHãy cùng đi qua việc triển khai VAE từng bước. Trước hết, chúng ta cần nhập các thư viện:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as npTiếp theo, chúng ta cần định nghĩa bộ mã hoá, bộ giải mã và VAE. Đây là mã:
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
h = torch.relu(self.fc1(z))
x_hat = torch.sigmoid(self.fc2(h))
return x_hat
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
mu, logvar = self.encoder(x)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = mu + eps * std
x_hat = self.decoder(z)
return x_hat, mu, logvarChúng ta cũng cần định nghĩa hàm mất mát. Hàm mất mát cho VAE gồm phần mất mát tái tạo và phần mất mát phân kỳ KL. Đây là cách hiện thực trong PyTorch:
def loss_function(x, x_hat, mu, logvar):
BCE = nn.functional.binary_cross_entropy(x_hat, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLDĐể huấn luyện VAE, chúng ta sẽ tải bộ dữ liệu MNIST, định nghĩa bộ tối ưu hoá và huấn luyện mô hình.
# Hyperparameters
input_dim = 784
hidden_dim = 400
latent_dim = 20
lr = 1e-3
batch_size = 128
epochs = 10
# Data loader
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Model, optimizer
vae = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(vae.parameters(), lr=lr)
# Training loop
vae.train()
for epoch in range(epochs):
train_loss = 0
for x, _ in train_loader:
x = x.view(-1, input_dim)
optimizer.zero_grad()
x_hat, mu, logvar = vae(x)
loss = loss_function(x, x_hat, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset)}")Sau khi huấn luyện, chúng ta có thể đánh giá VAE bằng cách trực quan hoá các đầu ra tái tạo và các mẫu được tạo.
Đây là mã:
# visualizing reconstructed outputs
vae.eval()
with torch.no_grad():
x, _ = next(iter(train_loader))
x = x.view(-1, input_dim)
x_hat, _, _ = vae(x)
x = x.view(-1, 28, 28)
x_hat = x_hat.view(-1, 28, 28)
fig, axs = plt.subplots(2, 10, figsize=(15, 3))
for i in range(10):
axs[0, i].imshow(x[i].cpu().numpy(), cmap='gray')
axs[1, i].imshow(x_hat[i].cpu().numpy(), cmap='gray')
axs[0, i].axis('off')
axs[1, i].axis('off')
plt.show()
#visualizing generated samples
with torch.no_grad():
z = torch.randn(10, latent_dim)
sample = vae.decoder(z)
sample = sample.view(-1, 28, 28)
fig, axs = plt.subplots(1, 10, figsize=(15, 3))
for i in range(10):
axs[i].imshow(sample[i].cpu().numpy(), cmap='gray')
axs[i].axis('off')
plt.show()
Trực quan hoá đầu ra. Hàng trên là dữ liệu MNIST gốc, hàng giữa là đầu ra tái tạo, và hàng cuối là các mẫu được tạo—hình do tác giả cung cấp.
Mặc dù Variational Autoencoders (VAE) là công cụ mạnh mẽ cho mô hình tạo sinh, chúng đi kèm một số thách thức và hạn chế có thể ảnh hưởng đến hiệu năng. Hãy thảo luận một vài vấn đề và đưa ra các chiến lược giảm thiểu.
Đây là hiện tượng VAE không nắm bắt được đầy đủ tính đa dạng của phân phối dữ liệu. Kết quả là các mẫu tạo ra chỉ đại diện cho một vài mode (vùng riêng biệt) của phân phối dữ liệu và bỏ qua các vùng khác. Điều này dẫn đến thiếu đa dạng trong đầu ra tạo sinh.
Nguyên nhân của sụp đổ mode:
Có thể giảm thiểu sụp đổ mode bằng cách dùng:
Trong một số trường hợp, không gian tiềm ẩn do VAE học có thể trở nên thiếu thông tin, khi mô hình không sử dụng hiệu quả các biến tiềm ẩn để nắm bắt các đặc trưng có ý nghĩa của dữ liệu đầu vào. Điều này có thể dẫn đến chất lượng kém của các mẫu tạo sinh và bản tái tạo.
Điều này thường xảy ra vì các lý do sau:
Có thể khắc phục không gian tiềm ẩn thiếu thông tin bằng chiến lược warm-up, tức tăng dần trọng số của phân kỳ KL trong quá trình huấn luyện, hoặc trực tiếp điều chỉnh trọng số của hạng mục phân kỳ KL trong hàm mất mát.
Huấn luyện VAE đôi khi có thể không ổn định, với hàm mất mát dao động hoặc phân kỳ. Điều này gây khó khăn để hội tụ và đạt được mô hình huấn luyện tốt.
Lý do xảy ra là do:
Các bước giảm thiểu bất ổn huấn luyện gồm sử dụng:
Huấn luyện VAE, đặc biệt với các bộ dữ liệu lớn và phức tạp, có thể tốn kém về tính toán. Nguyên nhân là do cần lấy mẫu và lan truyền ngược qua các tầng ngẫu nhiên.
Nguyên nhân của chi phí tính toán cao bao gồm:
Một số biện pháp giảm thiểu:
Variational Autoencoders (VAE) đã chứng tỏ là một bước tiến đột phá trong lĩnh vực học máy và tạo sinh dữ liệu.
Bằng cách đưa các yếu tố xác suất vào khung autoencoder truyền thống, VAE cho phép tạo dữ liệu mới, chất lượng cao và cung cấp một không gian tiềm ẩn liên tục, có cấu trúc hơn. Khả năng độc đáo này đã mở ra hàng loạt ứng dụng, từ mô hình tạo sinh và phát hiện bất thường đến bổ khuyết dữ liệu và học bán giám sát.
Trong bài viết này, chúng ta đã đề cập nền tảng của Variational Autoencoders, các biến thể, cách triển khai VAE trong PyTorch, cũng như thách thức và giải pháp khi làm việc với VAE.
Khám phá thêm các tài nguyên sau để tiếp tục học tập:
Tìm hiểu thêm về AI với các khoá học này!
Courses
Courses
Courses