
Corso
Introduzione al Deep Learning con PyTorch
4 h
87.7K
Con l’avanzare della tecnologia del machine learning a un ritmo senza precedenti, i Variational Autoencoders (VAE) stanno rivoluzionando il modo in cui elaboriamo e generiamo dati. Unendo un potente sistema di codifica dei dati a innovative capacità generative, i VAE offrono soluzioni trasformative a sfide complesse nel campo.
In questo articolo esploreremo i concetti di base dei VAE, le loro applicazioni e come implementarli in modo efficace con PyTorch, passo dopo passo.
Gli autoencoder sono un tipo di rete neurale progettata per apprendere rappresentazioni efficienti dei dati, principalmente per riduzione della dimensionalità o apprendimento delle feature.
Gli autoencoder sono composti da due parti principali:
L’obiettivo principale degli autoencoder è minimizzare la differenza tra l’input e l’output ricostruito, imparando così una rappresentazione compatta dei dati.
Entrano in gioco i Variational Autoencoders (VAE), che estendono le capacità del framework dell’autoencoder tradizionale incorporando elementi probabilistici nel processo di codifica.
Mentre gli autoencoder standard mappano gli input in rappresentazioni latenti fisse, i VAE introducono un approccio probabilistico in cui l’encoder produce una distribuzione sullo spazio latente, tipicamente modellata come una Gaussiana multivariata. Questo consente ai VAE di campionare da tale distribuzione durante il processo di decodifica, portando alla generazione di nuove istanze di dati.
La principale innovazione dei VAE risiede nella capacità di generare nuovi dati di alta qualità apprendendo uno spazio latente strutturato e continuo. Questo è particolarmente importante per il generative modeling, dove l’obiettivo non è solo comprimere i dati ma creare nuovi campioni che somiglino al dataset originale.
I VAE hanno dimostrato grande efficacia in compiti come la sintesi di immagini, la rimozione del rumore dai dati e il rilevamento di anomalie, rendendoli strumenti rilevanti per potenziare le capacità di modelli e applicazioni di machine learning.
In questa sezione introdurremo le basi teoriche e i meccanismi operativi dei VAE, fornendoti una base solida per esplorarne le applicazioni nelle sezioni successive.
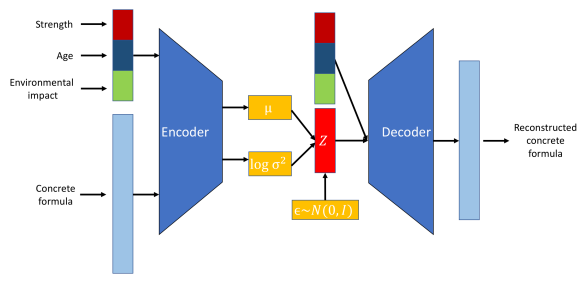
Partiamo dagli encoder. L’encoder è una rete neurale responsabile della mappatura dei dati in ingresso in uno spazio latente. A differenza degli autoencoder tradizionali che producono un punto fisso nello spazio latente, l’encoder in un VAE restituisce i parametri di una distribuzione di probabilità—tipicamente media e varianza di una distribuzione Gaussiana. Questo permette al VAE di modellare in modo efficace incertezza e variabilità dei dati.
Un’altra rete neurale chiamata decoder viene utilizzata per ricostruire i dati originali a partire dalla rappresentazione nello spazio latente. Dato un campione dalla distribuzione nello spazio latente, il decoder mira a generare un output che assomigli il più possibile all’input originale. Questo processo permette al VAE di creare nuove istanze di dati campionando dalla distribuzione appresa.
Lo spazio latente è uno spazio continuo a dimensionalità inferiore in cui vengono codificati i dati in ingresso.
Visualizzazione del ruolo di encoder, decoder e spazio latente. Fonte dell’immagine.
L’approccio variazionale è una tecnica utilizzata per approssimare distribuzioni di probabilità complesse. Nel contesto dei VAE, consiste nell’approssimare la vera distribuzione a posteriori delle variabili latenti dato il dato osservato, spesso intrattabile.
Il VAE apprende una distribuzione a posteriori approssimata. L’obiettivo è rendere questa approssimazione il più vicina possibile alla vera distribuzione a posteriori.
L’inferenza bayesiana è un metodo per aggiornare la stima di probabilità di un’ipotesi man mano che sono disponibili nuove evidenze o informazioni. Nei VAE, l’inferenza bayesiana viene utilizzata per stimare la distribuzione delle variabili latenti.
Integrando la conoscenza a priori (distribuzione prior) con i dati osservati (likelihood), i VAE adattano la rappresentazione nello spazio latente attraverso la distribuzione a posteriori appresa.
Inferenza bayesiana con distribuzione prior, distribuzione a posteriori e funzione di verosimiglianza. Fonte dell’immagine.
Ecco come appare il flusso del processo:
Vediamo le differenze e i vantaggi dei VAE rispetto agli autoencoder tradizionali.
Come visto in precedenza, gli autoencoder tradizionali consistono in una rete di encoding che mappa i dati in ingresso x in una rappresentazione latente fissa a dimensionalità inferiore z. Questo processo è deterministico, il che significa che ogni input viene codificato in un punto specifico dello spazio latente.
La rete di decodifica ricostruisce quindi i dati originali a partire da questa rappresentazione latente fissa, con l’obiettivo di minimizzare la differenza tra input e ricostruzione.
Lo spazio latente degli autoencoder tradizionali è una rappresentazione compressa dei dati in ingresso senza alcuna modellazione probabilistica, il che limita la loro capacità di generare nuovi dati diversificati poiché manca un meccanismo per gestire l’incertezza.
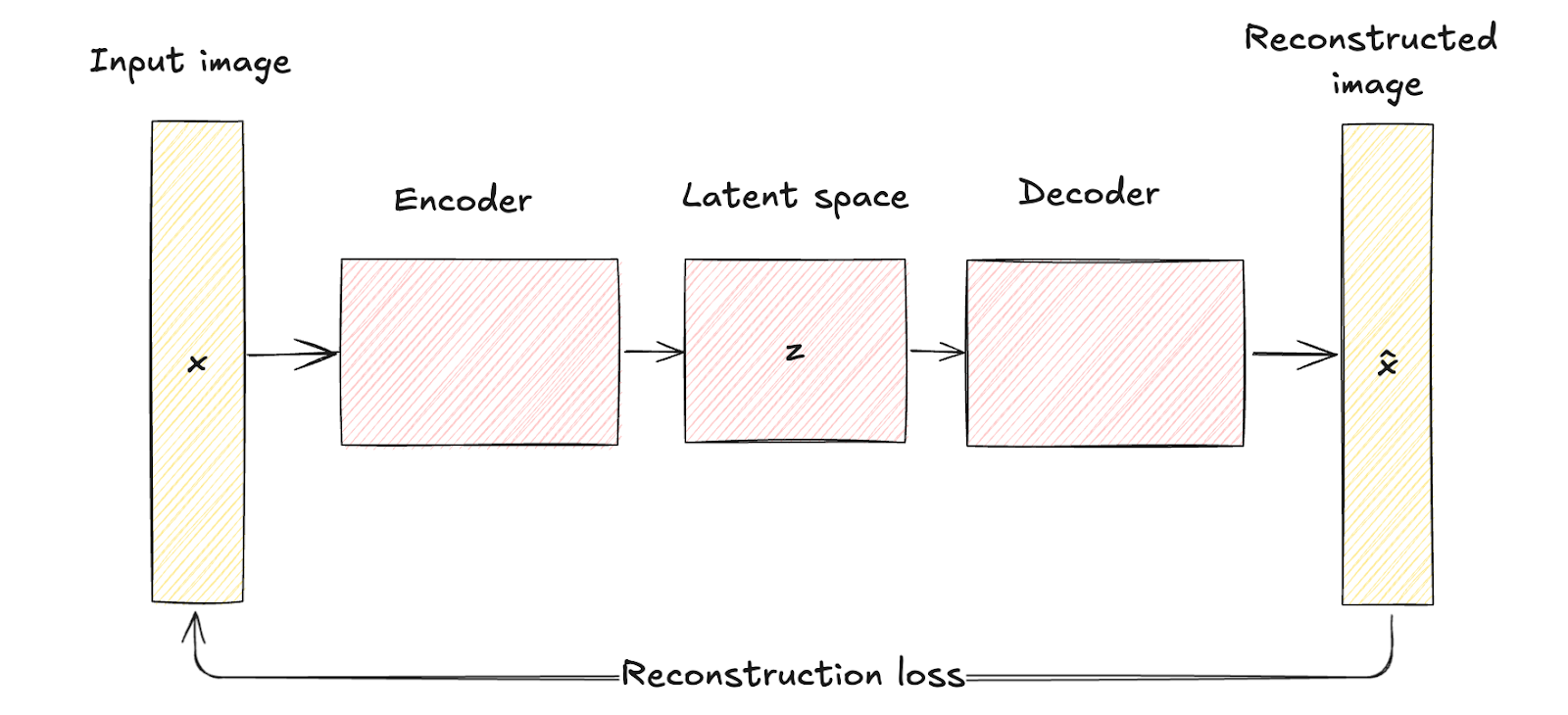
Architettura dell’autoencoder. Immagine dell’autore
I VAE introducono un elemento probabilistico nel processo di codifica. In particolare, l’encoder in un VAE mappa i dati in ingresso in una distribuzione di probabilità sulle variabili latenti, tipicamente modellata come una distribuzione Gaussiana con media μ e varianza σ2.
Questo approccio codifica ogni input in una distribuzione anziché in un singolo punto, aggiungendo un livello di variabilità e incertezza.
Le differenze architetturali sono rappresentate visivamente dal mapping deterministico negli autoencoder tradizionali rispetto alla codifica probabilistica e al campionamento nei VAE.
Questa differenza strutturale evidenzia come i VAE incorporino una regolarizzazione attraverso un termine noto come divergenza KL, che modella lo spazio latente rendendolo continuo e ben strutturato.
La regolarizzazione introdotta migliora sensibilmente la qualità e la coerenza dei campioni generati, superando le capacità degli autoencoder tradizionali.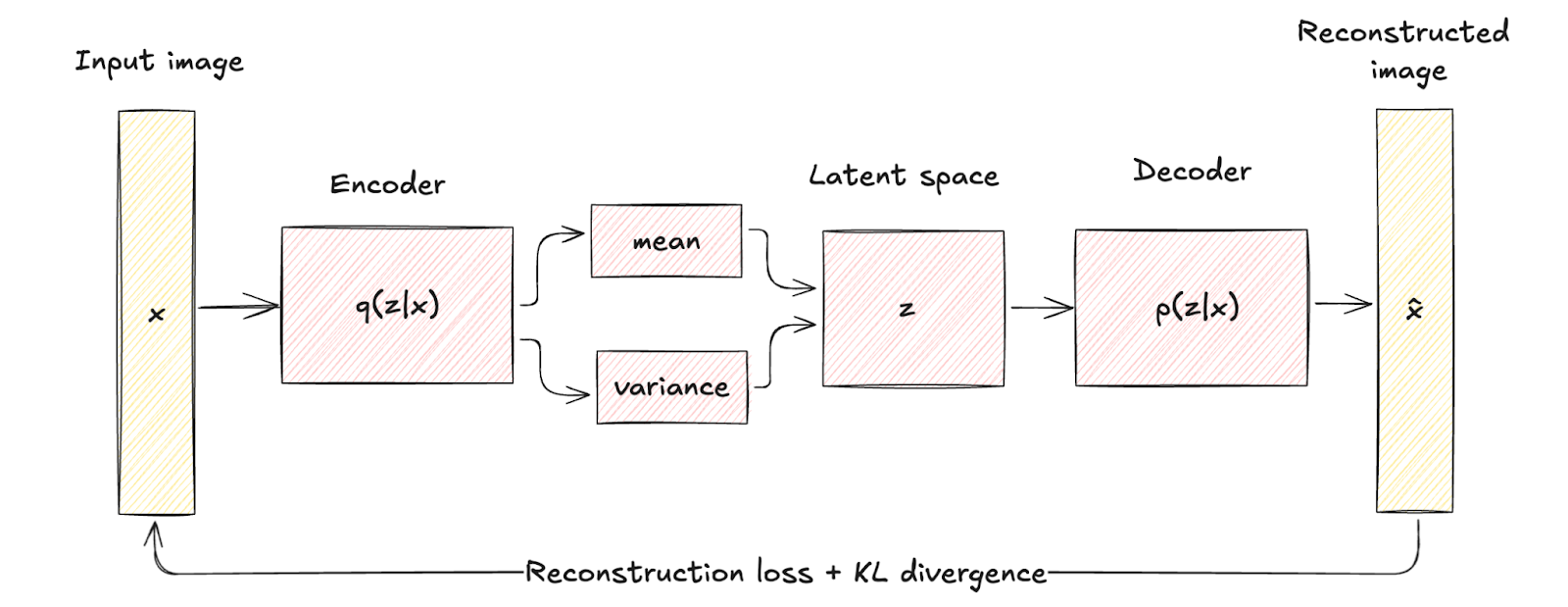
Architettura del Variational Autoencoder. Immagine dell’autore
La natura probabilistica dei VAE amplia significativamente la loro gamma di applicazioni rispetto agli autoencoder tradizionali. Questi ultimi, al contrario, sono molto efficaci in applicazioni dove è sufficiente una rappresentazione deterministica dei dati.
Vediamo alcune applicazioni di ciascun approccio per chiarire meglio il punto.
I VAE si sono evoluti in varie forme specializzate per affrontare diverse sfide e applicazioni nel machine learning. In questa sezione analizzeremo i tipi più importanti, evidenziando casi d’uso, vantaggi e limiti.
I Conditional Variational Autoencoders (CVAE) sono una forma specializzata di VAE che migliorano il processo generativo condizionandolo su informazioni aggiuntive.
Un VAE diventa “conditional” incorporando informazioni aggiuntive, indicate con c, sia nell’encoder sia nel decoder. Queste informazioni di condizionamento possono essere qualunque dato rilevante, come etichette di classe, attributi o altri dati contestuali.
Struttura del modello CVAE. Fonte dell’immagine.
I casi d’uso dei CVAE includono:
Pro e contro:
I Disentangled Variational Autoencoders, spesso chiamati Beta‑VAE, sono un altro tipo di VAE specializzati. Mirano ad apprendere rappresentazioni latenti in cui ogni dimensione cattura un fattore di variazione distinto e interpretabile nei dati. Ciò viene ottenuto modificando l’obiettivo originale dei VAE con un iperparametro β che bilancia la perdita di ricostruzione e il termine di divergenza KL.
Pro e contro dei Beta‑VAE:
Un’altra variante dei VAE sono gli Adversarial Autoencoders (AAE). Gli AAE combinano il framework dei VAE con i principi di training avversario delle Generative Adversarial Networks (GAN). Una rete discriminatrice aggiuntiva assicura che le rappresentazioni latenti corrispondano a una distribuzione prior, migliorando le capacità generative del modello.
Pro e contro degli AAE:
Ora esamineremo altre due estensioni dei Variational Autoencoders.
La prima sono i Variational Recurrent Autoencoders (VRAE). I VRAE estendono il framework dei VAE ai dati sequenziali incorporando reti neurali ricorrenti (RNN) nell’encoder e nel decoder. Questo consente ai VRAE di catturare dipendenze temporali e modellare pattern sequenziali.
Pro e contro dei VRAE:
L’ultima variante che esamineremo sono gli Hierarchical Variational Autoencoders (HVAE). Gli HVAE introducono più livelli di variabili latenti disposti in una struttura gerarchica, che consente al modello di catturare dipendenze e astrazioni più complesse nei dati.
Pro e contro degli HVAE:
In questa sezione implementeremo un semplice Variational Autoencoder (VAE) utilizzando PyTorch.
Per implementare un VAE, dobbiamo configurare l’ambiente Python con le librerie e gli strumenti necessari. Le librerie che useremo sono:
Ecco il codice per installare queste librerie:
pip install torch torchvision matplotlib numpyProcediamo con l’implementazione di un VAE passo dopo passo. Per prima cosa, importiamo le librerie:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as npSuccessivamente, dobbiamo definire encoder, decoder e VAE. Ecco il codice:
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
h = torch.relu(self.fc1(z))
x_hat = torch.sigmoid(self.fc2(h))
return x_hat
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
mu, logvar = self.encoder(x)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = mu + eps * std
x_hat = self.decoder(z)
return x_hat, mu, logvarDobbiamo anche definire la funzione di loss. La loss dei VAE comprende una perdita di ricostruzione e una perdita di divergenza KL. Ecco come appare in PyTorch:
def loss_function(x, x_hat, mu, logvar):
BCE = nn.functional.binary_cross_entropy(x_hat, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLDPer addestrare il VAE, caricheremo il dataset MNIST, definiremo l’ottimizzatore e alleneremo il modello.
# Hyperparameters
input_dim = 784
hidden_dim = 400
latent_dim = 20
lr = 1e-3
batch_size = 128
epochs = 10
# Data loader
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Model, optimizer
vae = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(vae.parameters(), lr=lr)
# Training loop
vae.train()
for epoch in range(epochs):
train_loss = 0
for x, _ in train_loader:
x = x.view(-1, input_dim)
optimizer.zero_grad()
x_hat, mu, logvar = vae(x)
loss = loss_function(x, x_hat, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset)}")Dopo l’addestramento, possiamo valutare il VAE visualizzando gli output ricostruiti e i campioni generati.
Questo è il codice:
# visualizing reconstructed outputs
vae.eval()
with torch.no_grad():
x, _ = next(iter(train_loader))
x = x.view(-1, input_dim)
x_hat, _, _ = vae(x)
x = x.view(-1, 28, 28)
x_hat = x_hat.view(-1, 28, 28)
fig, axs = plt.subplots(2, 10, figsize=(15, 3))
for i in range(10):
axs[0, i].imshow(x[i].cpu().numpy(), cmap='gray')
axs[1, i].imshow(x_hat[i].cpu().numpy(), cmap='gray')
axs[0, i].axis('off')
axs[1, i].axis('off')
plt.show()
#visualizing generated samples
with torch.no_grad():
z = torch.randn(10, latent_dim)
sample = vae.decoder(z)
sample = sample.view(-1, 28, 28)
fig, axs = plt.subplots(1, 10, figsize=(15, 3))
for i in range(10):
axs[i].imshow(sample[i].cpu().numpy(), cmap='gray')
axs[i].axis('off')
plt.show()
Visualizzazione degli output. La riga superiore è il dato MNIST originale, la riga centrale sono gli output ricostruiti e l’ultima riga i campioni generati—immagine dell’autore.
Sebbene i Variational Autoencoders (VAE) siano strumenti potenti per il generative modeling, presentano diverse sfide e limitazioni che possono influenzarne le prestazioni. Vediamone alcune e forniamo strategie di mitigazione.
È un fenomeno in cui il VAE non riesce a catturare l’intera diversità della distribuzione dei dati. Il risultato sono campioni generati che rappresentano solo poche modalità (regioni distinte) della distribuzione, ignorando le altre. Ciò porta a una scarsa varietà negli output generati.
Il mode collapse è causato da:
Il mode collapse può essere mitigato usando:
In alcuni casi, lo spazio latente appreso da un VAE può diventare poco informativo, ovvero il modello non usa in modo efficace le variabili latenti per catturare caratteristiche significative dei dati in ingresso. Questo può risultare in campioni generati e ricostruzioni di bassa qualità.
Ciò avviene tipicamente per i seguenti motivi:
Gli spazi latenti poco informativi possono essere mitigati usando la strategia di warm‑up, che consiste nell’aumentare gradualmente il peso della divergenza KL durante l’addestramento, oppure modificando direttamente il peso del termine KL nella funzione di loss.
L’addestramento dei VAE può talvolta essere instabile, con la funzione di loss che oscilla o diverge. Questo può rendere difficile raggiungere la convergenza e ottenere un modello ben addestrato.
Ciò accade perché:
I passi per mitigare l’instabilità del training includono:
L’addestramento dei VAE, specialmente con dataset ampi e complessi, può essere costoso dal punto di vista computazionale. Ciò è dovuto alla necessità di campionamento e backpropagation attraverso layer stocastici.
Le cause degli alti costi computazionali includono:
Alcune azioni di mitigazione:
I Variational Autoencoders (VAE) si sono rivelati un progresso rivoluzionario nel mondo del machine learning e della generazione di dati.
Introducendo elementi probabilistici nel framework dell’autoencoder tradizionale, i VAE consentono di generare nuovi dati di alta qualità e forniscono uno spazio latente più strutturato e continuo. Questa capacità unica ha aperto un’ampia gamma di applicazioni, dal generative modeling e rilevamento di anomalie all’imputazione dei dati e all’apprendimento semi‑supervisionato.
In questo articolo abbiamo trattato i fondamenti dei Variational Autoencoders, le diverse tipologie, come implementarli in PyTorch, nonché le sfide e le soluzioni quando si lavora con i VAE.
Dai un’occhiata a queste risorse per continuare a imparare:
Approfondisci l’AI con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

