
Cours
Introduction au deep learning avec PyTorch
4 h
85.7K
Alors que la technologie de l'apprentissage automatique progresse à un rythme sans précédent, les autoencodeurs variationnels (VAE) révolutionnent la façon dont nous traitons et générons les données. En combinant un encodage de données puissant avec des capacités génératives innovantes, les VAE offrent des solutions transformatrices pour relever des défis complexes sur le terrain.
Dans cet article, nous allons explorer les concepts fondamentaux des VAE, leurs applications et la manière dont elles peuvent être mises en œuvre efficacement à l'aide de PyTorch, étape par étape.
Les autoencodeurs sont un type de réseau neuronal conçu pour apprendre des représentations de données efficaces, principalement à des fins de réduction de la dimensionnalité ou d'apprentissage de caractéristiques.
Les autoencodeurs se composent de deux parties principales :
L'objectif principal des autoencodeurs est de minimiser la différence entre l'entrée et la sortie reconstruite, en apprenant ainsi une représentation compacte des données.
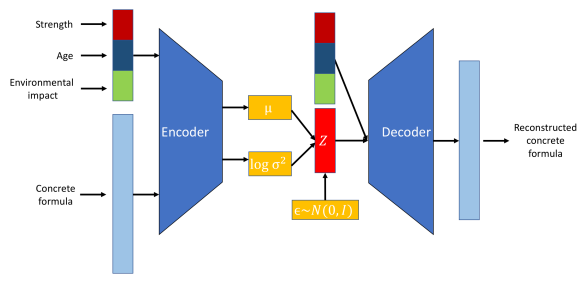
Les autoencodeurs variationnels (VAE) étendent les capacités du cadre traditionnel des autoencodeurs en incorporant des éléments probabilistes dans le processus d'encodage.
Alors que les autoencodeurs standard associent les entrées à des représentations latentes fixes, les VAE introduisent une approche probabiliste dans laquelle l'encodeur émet une distribution sur l'espace latent, généralement modélisée sous la forme d'une gaussienne multivariée. Cela permet aux VAE d'échantillonner cette distribution au cours du processus de décodage, ce qui conduit à la génération de nouvelles instances de données.
La principale innovation des VAE réside dans leur capacité à générer de nouvelles données de haute qualité en apprenant un espace latent structuré et continu. Ceci est particulièrement important pour la modélisation générative, où l'objectif n'est pas seulement de compresser les données mais de créer de nouveaux échantillons de données qui ressemblent à l'ensemble de données d'origine.
Les VAE ont démontré une efficacité significative dans des tâches telles que la synthèse d'images, le débruitage de données et la détection d'anomalies, ce qui en fait des outils pertinents pour améliorer les capacités des modèles et des applications d'apprentissage automatique.
Dans cette section, nous présenterons le contexte théorique et les mécanismes opérationnels des VAE, ce qui vous fournira une base solide pour explorer leurs applications dans les sections suivantes.
Commençons par les codeurs. L'encodeur est un réseau neuronal chargé de mettre en correspondance les données d'entrée avec un espace latent. Contrairement aux autoencodeurs traditionnels qui produisent un point fixe dans l'espace latent, l'encodeur d'une VAE produit les paramètres d'une distribution de probabilité, généralement la moyenne et la variance d'une distribution gaussienne. Cela permet à la VAE de modéliser efficacement l'incertitude et la variabilité des données.
Un autre réseau neuronal, appelé décodeur, est utilisé pour reconstruire les données originales à partir de la représentation de l'espace latent. Étant donné un échantillon de la distribution de l'espace latent, le décodeur vise à générer une sortie qui ressemble étroitement aux données d'entrée originales. Ce processus permet à la VAE de créer de nouvelles instances de données en échantillonnant la distribution apprise.
L'espace latent est un espace continu de dimension inférieure dans lequel les données d'entrée sont encodées.
Visualisation du rôle du codeur, du décodeur et de l'espace latent. Source de l'image.
L'approche variationnelle est une technique utilisée pour approximer des distributions de probabilité complexes. Dans le contexte des VAE, il s'agit d'approximer la véritable distribution postérieure des variables latentes en fonction des données, ce qui est souvent difficile à réaliser.
La VAE apprend une distribution postérieure approximative. L'objectif est de faire en sorte que cette approximation soit aussi proche que possible de la véritable valeur postérieure.
L'inférence bayésienne est une méthode qui permet d'actualiser l'estimation de la probabilité d'une hypothèse au fur et à mesure que de nouvelles preuves ou informations sont disponibles. Dans les VAE, l'inférence bayésienne est utilisée pour estimer la distribution des variables latentes.
En intégrant les connaissances antérieures (distribution antérieure) aux données observées (vraisemblance), les VAE ajustent la représentation de l'espace latent par le biais de la distribution postérieure apprise.
Inférence bayésienne avec une distribution préalable, une distribution postérieure et une fonction de vraisemblance. Source de l'image.
Voici à quoi ressemble le déroulement de la procédure :
Examinons les différences et les avantages des VAE par rapport aux autoencodeurs traditionnels.
Comme nous l'avons vu précédemment, les autoencodeurs traditionnels se composent d'un réseau d'encodage qui fait correspondre les données d'entrée x à une représentation fixe de l'espace latent de dimension inférieure z. Ce processus est déterministe, ce qui signifie que chaque entrée est codée en un point spécifique de l'espace latent.
Le réseau décodeur reconstruit ensuite les données originales à partir de cette représentation latente fixe, en cherchant à minimiser la différence entre l'entrée et sa reconstruction.
L'espace latent des autoencodeurs traditionnels est une représentation comprimée des données d'entrée sans aucune modélisation probabiliste, ce qui limite leur capacité à générer des données nouvelles et diverses puisqu'ils ne disposent pas d'un mécanisme pour gérer l'incertitude.
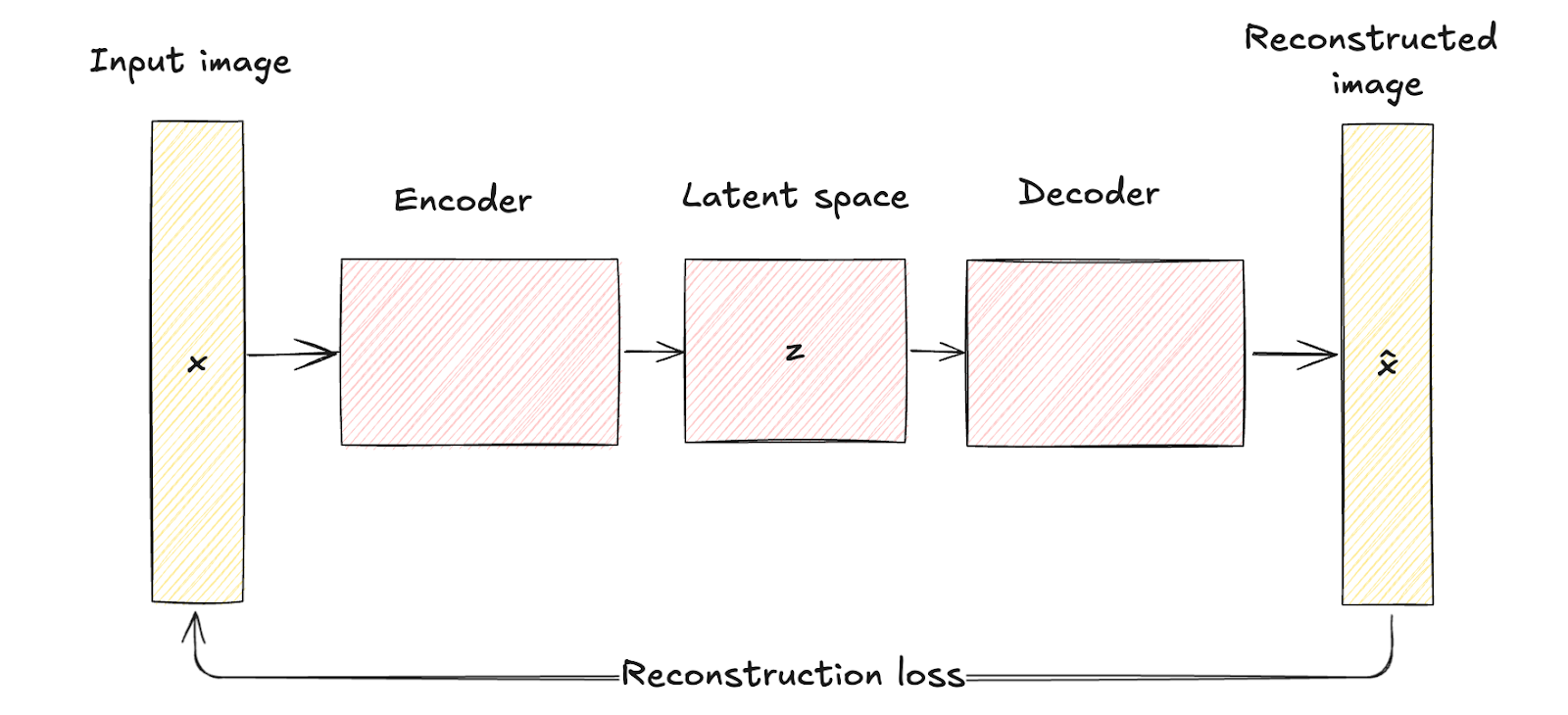
Architecture de l'autoencodeur. Image de l'auteur
Les VAE introduisent un élément probabiliste dans le processus d'encodage. Le codeur d'une VAE fait correspondre les données d'entrée à une distribution de probabilité sur les variables latentes, généralement modélisée comme une distribution gaussienne avec moyenne. μ et une variance σ2.
Cette approche encode chaque entrée dans une distribution plutôt que dans un point unique, ce qui ajoute une couche de variabilité et d'incertitude.
Les différences architecturales sont représentées visuellement par le mappage déterministe des autoencodeurs traditionnels par rapport à l'encodage et à l'échantillonnage probabilistes des VAE.
Cette différence structurelle met en évidence la manière dont les VAE intègrent la régularisation par le biais d'un terme connu sous le nom de divergence KL, en façonnant l'espace latent de manière à ce qu'il soit continu et bien structuré.
La régularisation introduite améliore considérablement la qualité et la cohérence des échantillons générés, surpassant les capacités des autoencodeurs traditionnels.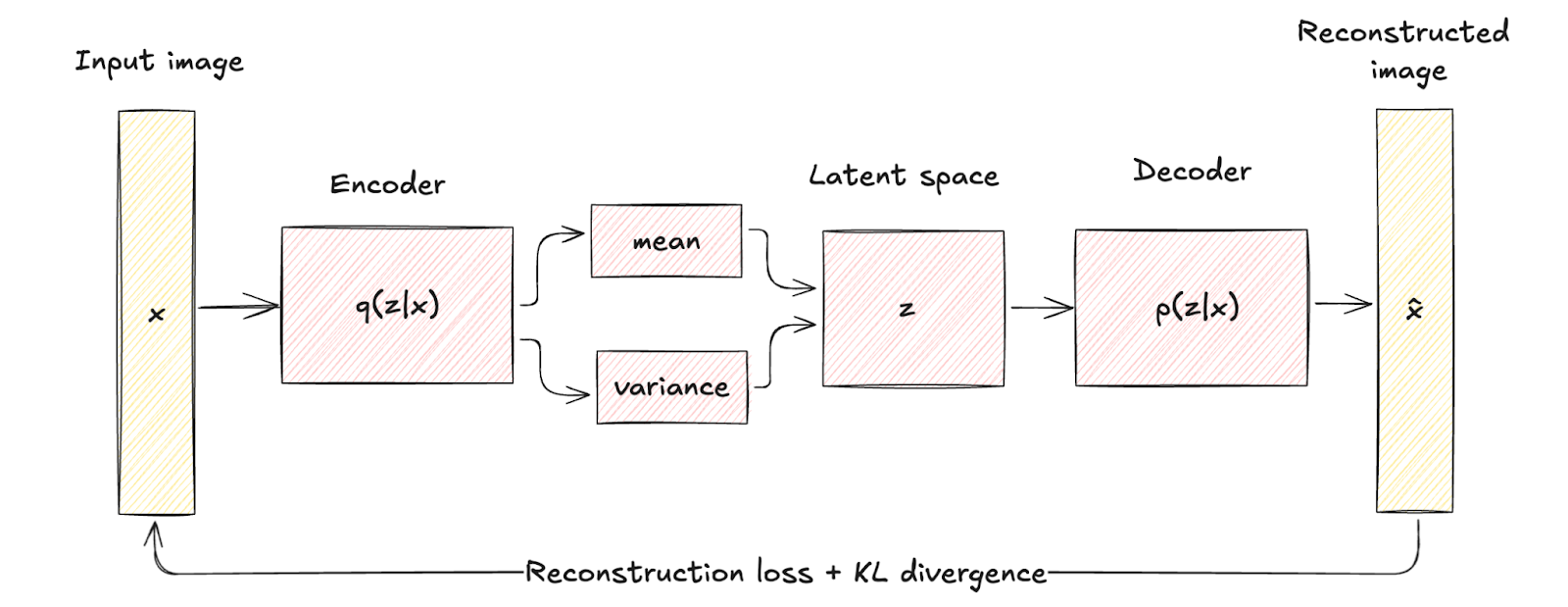
Architecture de l'autoencodeur variationnel. Image de l'auteur
La nature probabiliste des VAE élargit considérablement leur champ d'application par rapport à celui des autoencodeurs traditionnels. En revanche, les autoencodeurs traditionnels sont très efficaces dans les applications où une représentation déterministe des données est suffisante.
Examinons quelques applications de chacune d'entre elles pour mieux comprendre ce point.
Les VAE ont évolué vers diverses formes spécialisées pour répondre aux différents défis et applications de l'apprentissage automatique. Dans cette section, nous examinerons les types les plus importants, en soulignant les cas d'utilisation, les avantages et les limites.
Les autoencodeurs variationnels conditionnels (CVAE) sont une forme spécialisée de VAE qui améliore le processus génératif en conditionnant des informations supplémentaires.
Une VAE devient conditionnelle en incorporant des informations supplémentaires, désignées par c, dans les réseaux du codeur et du décodeur. Ces informations de conditionnement peuvent être des données pertinentes, telles que des étiquettes de classe, des attributs ou d'autres données contextuelles.
Structure du modèle CVAE. Source de l'image.
Les cas d'utilisation des CVAE sont les suivants
Les avantages et les inconvénients sont les suivants :
Autoencodeurs variationnels démêlés, souvent appelés Beta-VAE, sont un autre type de VAE spécialisés. Ils visent à apprendre des représentations latentes où chaque dimension capture un facteur de variation distinct et interprétable dans les données. Pour ce faire, l'objectif original de la VAE est modifié par un hyperparamètre β qui équilibre la perte de reconstruction et le terme de divergence KL.
Avantages et inconvénients des bêta-VAE :
Une autre variante des VAE est l'Autoencodeur Adversarial (AAEs). Les AAE combinent le cadre de la VAE avec les principes de formation contradictoire des réseaux adversoriels génératifs (GAN). Un réseau discriminant supplémentaire garantit que les représentations latentes correspondent à une distribution préalable, améliorant ainsi les capacités génératives du modèle.
Avantages et inconvénients des AAE :
Nous allons maintenant examiner deux autres extensions des autoencodeurs variationnels.
La première est celle des autoencodeurs récurrents variationnels (VRAE). Les VRAE étendent le cadre de la VAE aux données séquentielles en incorporant des réseaux neuronaux récurrents (RNN) dans les réseaux de codage et de décodage. Cela permet aux VRAE de saisir les dépendances temporelles et de modéliser des modèles séquentiels.
Avantages et inconvénients des VRAE :
La dernière variante que nous examinerons est la variante autoencodeurs variationnels hiérarchiques (HVAE). Les HVAE introduisent plusieurs couches de variables latentes disposées selon une structure hiérarchique, ce qui permet au modèle de saisir des dépendances et des abstractions plus complexes dans les données.
Avantages et inconvénients des HVAE :
Dans cette section, nous allons mettre en œuvre un simple autoencodeur variationnel (VAE) à l'aide de PyTorch.
Pour mettre en œuvre une VAE, nous devons configurer notre environnement Python avec les bibliothèques et les outils nécessaires. Les bibliothèques que nous utiliserons sont les suivantes :
Voici le code pour installer ces bibliothèques :
pip install torch torchvision matplotlib numpyDécouvrons étape par étape la mise en œuvre d'une VAE. Tout d'abord, nous devons importer les bibliothèques :
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as npEnsuite, il faut définir le codeur, le décodeur et la VAE. Voici le code :
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
h = torch.relu(self.fc1(z))
x_hat = torch.sigmoid(self.fc2(h))
return x_hat
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
mu, logvar = self.encoder(x)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = mu + eps * std
x_hat = self.decoder(z)
return x_hat, mu, logvarNous devons également définir la fonction de perte. La fonction de perte pour les VAE se compose d'une perte de reconstruction et d'une perte de divergence KL. Voici à quoi cela ressemble dans PyTorch :
def loss_function(x, x_hat, mu, logvar):
BCE = nn.functional.binary_cross_entropy(x_hat, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLDPour entraîner la VAE, nous chargerons l'ensemble de données MNIST, définirons l'optimiseur et entraînerons le modèle.
# Hyperparameters
input_dim = 784
hidden_dim = 400
latent_dim = 20
lr = 1e-3
batch_size = 128
epochs = 10
# Data loader
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Model, optimizer
vae = VAE(input_dim, hidden_dim, latent_dim)
optimizer = optim.Adam(vae.parameters(), lr=lr)
# Training loop
vae.train()
for epoch in range(epochs):
train_loss = 0
for x, _ in train_loader:
x = x.view(-1, input_dim)
optimizer.zero_grad()
x_hat, mu, logvar = vae(x)
loss = loss_function(x, x_hat, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset)}")Après l'entraînement, nous pouvons évaluer la VAE en visualisant les sorties reconstruites et les échantillons générés.
Voici le code :
# visualizing reconstructed outputs
vae.eval()
with torch.no_grad():
x, _ = next(iter(train_loader))
x = x.view(-1, input_dim)
x_hat, _, _ = vae(x)
x = x.view(-1, 28, 28)
x_hat = x_hat.view(-1, 28, 28)
fig, axs = plt.subplots(2, 10, figsize=(15, 3))
for i in range(10):
axs[0, i].imshow(x[i].cpu().numpy(), cmap='gray')
axs[1, i].imshow(x_hat[i].cpu().numpy(), cmap='gray')
axs[0, i].axis('off')
axs[1, i].axis('off')
plt.show()
#visualizing generated samples
with torch.no_grad():
z = torch.randn(10, latent_dim)
sample = vae.decoder(z)
sample = sample.view(-1, 28, 28)
fig, axs = plt.subplots(1, 10, figsize=(15, 3))
for i in range(10):
axs[i].imshow(sample[i].cpu().numpy(), cmap='gray')
axs[i].axis('off')
plt.show()
Visualisation des résultats. La ligne du haut représente les données MNIST originales, la ligne du milieu les sorties reconstruites et la dernière ligne les échantillons générés - image de l'auteur.
Bien que les autoencodeurs variationnels (VAE) soient des outils puissants pour la modélisation générative, ils présentent plusieurs défis et limitations qui peuvent affecter leurs performances. Examinons certains d'entre eux et proposons des stratégies d'atténuation.
Il s'agit d'un phénomène où la VAE ne parvient pas à capturer toute la diversité de la distribution des données. Il en résulte des échantillons générés qui ne représentent que quelques modes (régions distinctes) de la distribution des données, tout en ignorant les autres. Il en résulte un manque de variété dans les résultats générés.
Effondrement du mode causé par :
L'effondrement du mode peut être atténué en utilisant :
Dans certains cas, l'espace latent appris par une VAE peut devenir non informatif, lorsque le modèle n'utilise pas efficacement les variables latentes pour capturer des caractéristiques significatives des données d'entrée. Cela peut entraîner une mauvaise qualité des échantillons générés et des reconstructions.
Cela se produit généralement pour les raisons suivantes :
Les espaces latents non informatifs peuvent être corrigés en tirant parti de la stratégie d'échauffement, qui consiste à augmenter progressivement le poids de la divergence KL au cours de l'apprentissage, ou en modifiant directement le poids du terme de divergence KL dans la fonction de perte.
Les VAE de formation peuvent parfois être instables, la fonction de perte oscillant ou divergeant. Cela peut rendre difficile la convergence et l'obtention d'un modèle bien entraîné.
La raison en est la suivante :
Les mesures visant à atténuer l'instabilité de la formation consistent soit à utiliser :
L'entraînement des VAE, en particulier avec des ensembles de données complexes et de grande taille, peut être coûteux en termes de calcul. Cela s'explique par la nécessité de procéder à un échantillonnage et à une rétropropagation à travers des couches stochastiques.
Les causes des coûts de calcul élevés sont les suivantes :
Il s'agit de quelques mesures d'atténuation :
Les autoencodeurs variationnels (VAE) se sont révélés être une avancée révolutionnaire dans le domaine de l'apprentissage automatique et de la génération de données.
En introduisant des éléments probabilistes dans le cadre traditionnel de l'autoencodeur, les VAE permettent de générer de nouvelles données de haute qualité et fournissent un espace latent plus structuré et plus continu. Cette capacité unique a ouvert la voie à un large éventail d'applications, allant de la modélisation générative et de la détection d'anomalies à l'imputation de données et à l'apprentissage semi-supervisé.
Dans cet article, nous avons abordé les principes fondamentaux des autoencodeurs variationnels, les différents types, la manière d'implémenter les VAE dans PyTorch, ainsi que les défis et les solutions lorsque vous travaillez avec des VAE.
Consultez ces ressources pour poursuivre votre apprentissage :
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Apprenez-en plus sur l'IA grâce à ces cours !
Cours
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel
Samuel Shaibu
Tutoriel
Tutoriel
Mark Pedigo

