
Corso
Classificatori lineari in Python
4 h
66.7K
Hai mai provato a estrarre schemi utili da un dataset con migliaia di feature?
Sai che un dataset enorme deve avere una qualche struttura utile nascosta. Il problema è che i dataset grezzi contengono molto rumore, ridondanza, valori mancanti e molte più dimensioni di quante te ne servano davvero. La maggior parte degli algoritmi di machine learning fatica a comprendere questo tipo di dati o, nel migliore dei casi, rallenta i tempi di training.
La Decomposizione ai Valori Singolari (SVD) scompone qualsiasi matrice (in questo caso, un dataset) in tre matrici più semplici che mostrano la sua struttura centrale. È la matematica alla base dei sistemi di raccomandazione, della compressione delle immagini e delle tecniche di riduzione della dimensionalità come la PCA — e una volta che la capisci, la vedrai ovunque nel tuo lavoro quotidiano.
In questo articolo ti spiego cos'è l'SVD, come funziona, dove viene usata in data science e quando è meglio scegliere un'alternativa.
Trovi confusi concetti come vettori e determinanti? Leggi il nostro post Demistificare i concetti matematici per il deep learning prima di proseguire con questo.
L'SVD è un metodo che scompone qualsiasi matrice in tre matrici più semplici.
Pensala così. Hai una matrice A — potrebbe essere un dataset o un'immagine. L'SVD suddivide A in tre parti:
Formula SVD
U è una matrice ortogonale m x m. Le sue colonne si chiamano autovettori sinistri (left singular vectors) e descrivono le relazioni tra le righe di A
\Sigma è una matrice diagonale m x n. I valori sulla diagonale sono i valori singolari — sempre non negativi e ordinati dal più grande al più piccolo
V* è la trasposta coniugata di una matrice ortogonale n x n. Le sue righe si chiamano autovettori destri (right singular vectors) e descrivono le relazioni tra le colonne di A
Ogni pezzo mostra qualcosa di diverso sui dati originali. U contiene gli schemi a livello di riga (come le righe si relazionano tra loro), \Sigma contiene i pesi di importanza (quanto conta ciascun pattern) e V* contiene gli schemi a livello di colonna (come le colonne si relazionano tra loro).
Ecco un'analogia. Immagina di dover descrivere una ricetta a qualcuno. Potresti scomporla in tre parti: gli ingredienti (cosa ci va), le proporzioni (quanto di ciascuno) e i passaggi (come si combinano). Nessuna di queste parti da sola ricrea il piatto, ma insieme ti danno tutto ciò che serve. L'SVD fa lo stesso con le matrici: separa il "cosa", il "quanto" e il "come" in componenti distinti con cui puoi lavorare in modo indipendente.
Ciò che rende l'SVD speciale in algebra lineare è che funziona su qualsiasi matrice. Non deve essere quadrata né avere proprietà particolari. Qualsiasi matrice m x n può essere decomposta in questo modo, ed è per questo che compare ovunque in data science.
Vediamo da vicino come funziona l'SVD, partendo dall'inizio.
Supponiamo di avere una matrice 3×2 A:
Decomposizione della matrice
L'SVD la decompone in U (3×3), \Sigma (3×2) e V* (2×2). Le colonne di U provengono dagli autovettori di A x A^T e le colonne di V dagli autovettori di A^T x A. I valori singolari in \Sigma sono le radici quadrate degli autovalori di uno dei due prodotti.
La buona notizia è che non devi calcolarli a mano. In Python, ti basta una riga di codice:
import numpy as np
A = np.array([[1, 2], [3, 4], [5, 6]])
U, sigma, Vt = np.linalg.svd(A, full_matrices=True)
Output Numpy
Le tre matrici interagiscono tramite moltiplicazione. U ruota i dati nello spazio delle righe, \Sigma li scala lungo ciascun asse e V* li ruota nello spazio delle colonne. Il risultato è la matrice originale A.
I valori diagonali in \Sigma indicano quanto ciascun componente contribuisce alla matrice complessiva.
Il primo valore singolare è sempre il più grande: cattura lo schema più dominante nei dati. Ciascun valore successivo cattura di meno. Se i primi valori singolari sono grandi e gli altri vicini allo zero, significa che gran parte dell'informazione nella matrice è concentrata in pochi componenti.
È questo che rende possibile la compressione dei dati.
Puoi escludere i valori singolari piccoli (e le loro colonne corrispondenti in U e le righe in V*) senza perdere molta informazione. Il risultato è un'approssimazione a rango inferiore della matrice originale, più piccola e più veloce da usare.
Il numero di valori singolari non nulli indica anche il rango della matrice — cioè il numero di righe o colonne linearmente indipendenti. Se una matrice 100×50 ha solo 10 valori singolari non nulli, significa che i dati hanno solo 10 dimensioni indipendenti. Le altre 40 sono ridondanti.
Puoi ricostruire la matrice originale moltiplicando di nuovo insieme i tre componenti:
Ricostruzione della matrice
Ma quello che ti interessa davvero è la ricostruzione parziale. Quindi, invece di usare tutti i valori singolari, tieni solo i primi k valori e i relativi vettori. Questo ti dà un'approssimazione di rango k di A:
Approssimazione di matrice a rango k
Il teorema di Eckart-Young garantisce che questa approssimazione di rango k è la matrice di rango k più vicina possibile all'originale A (misurata con la norma di Frobenius). In altre parole, se devi comprimere una matrice a k dimensioni, l'SVD ti dà il miglior risultato possibile.
Una volta che inizi a cercarla, l'SVD compare in molti più posti di quanto ti aspetti.
L'idea è sempre prendere una grande matrice, tenere le parti che contano e rimuovere il resto. Ciò che cambia è cosa significa "conta" a seconda del problema.
I dataset ad alta dimensionalità sono difficili da gestire e da interpretare. Più feature significano tempi di training più lunghi e un rischio maggiore di overfitting. L'SVD evita questo riducendo il numero di dimensioni.
In breve, funziona così. Decomponi la tua matrice dei dati, osservi i valori singolari e tieni solo i primi k componenti. I valori singolari piccoli rappresentano rumore e variazioni minori, quindi rimuoverli incide appena sulla qualità dei dati. Ciò che rimane è una rappresentazione compatta che conserva gran parte della struttura originale.
È esattamente così che funziona la Principal Component Analysis (PCA). La PCA centra i dati e poi esegue l'SVD sul risultato. Le componenti principali sono i vettori singolari destri e i valori singolari indicano quanta varianza spiega ciascuna componente.
Aziende come Netflix e Amazon hanno enormi matrici utente–prodotto in cui la maggior parte delle voci è vuota. Un utente valuta pochi film su migliaia, quindi la matrice è sparsa. L'SVD serve a colmare le lacune.
L'idea è scomporre la matrice delle valutazioni in preferenze degli utenti e caratteristiche degli articoli. La matrice U rappresenta ciò a cui ogni utente dà peso (genere, ritmo, tono) e V* rappresenta ciò che offre ogni articolo. I valori singolari in \Sigma scalano questi fattori per importanza. Quando li moltiplichi nuovamente, ottieni valutazioni previste per i film che un utente non ha ancora visto.
In pratica, l'SVD standard non funziona direttamente su matrici sparse perché tratta i valori mancanti come zeri. Per questo si usano varianti come la SVD troncata o metodi di fattorizzazione di matrici che operano solo sulle voci osservate.
Un'immagine in scala di grigi è solo una matrice di valori di pixel. L'SVD può comprimerla mantenendo solo i valori singolari più importanti.
Supponi di avere un'immagine 1000×1000. L'SVD completo restituisce 1000 valori singolari. Ma se tieni solo i primi 50, ricostruisci l'immagine con appena 50 componenti invece di 1000. L'immagine apparirà leggermente sfocata ma riconoscibile — e lo spazio di archiviazione scende da 1.000.000 di valori a circa 100.500 (50 colonne di U + 50 valori singolari + 50 righe di V*).
Più valori singolari significano qualità dell'immagine migliore ma minore compressione. Meno valori significano file più piccoli ma più perdita. Sta a te scegliere il punto di equilibrio in base al tuo caso d'uso.
Più grande è la tua matrice, maggiore sarà il costo computazionale.
L'SVD completo su una matrice m x n ha una complessità temporale O(mn²) (supponendo m >= n). Per matrici piccole va bene. Per una matrice con milioni di righe e migliaia di colonne, è costosa.
La memoria è l'altro collo di bottiglia. L'SVD completo produce tre matrici dense e archiviarle tutte insieme può superare la RAM disponibile.
La soluzione è evitare di calcolare l'SVD completo quando non serve. La SVD troncata calcola solo i primi k valori singolari e i relativi vettori, il che è molto più veloce. In Python, scipy.sparse.linalg.svds e sklearn.decomposition.TruncatedSVD lo fanno entrambi. La SVD randomizzata spinge oltre usando campionamento casuale per approssimare la decomposizione e funziona bene quando ti servono solo le componenti dominanti.
L'SVD è numericamente stabile nella maggior parte dei casi, ma può avere difficoltà con certi schemi nei dati.
Dati altamente rumorosi sono un esempio. Se il rapporto segnale–rumore è basso, i valori singolari principali non si separano dal rumore. Finirai per mantenere rumore nell'approssimazione o per ridurre il segnale quando tronchi.
Le matrici mal condizionate sono un altro problema. Quando il rapporto tra il valore singolare più grande e quello più piccolo è enorme (numero di condizione alto), piccoli errori numerici durante il calcolo si amplificano. Questo può produrre risultati inaffidabili, soprattutto con i limiti di precisione in virgola mobile.
La soluzione è ispezionare i valori singolari prima di troncare. Tracciali e cerca un calo netto tra segnale e rumore. Se il decadimento è graduale senza un gomito evidente, l'SVD potrebbe non essere lo strumento migliore per quel dataset.
L'SVD non è l'unica decomposizione di matrici e non è sempre la scelta migliore per ogni compito.
Ciascuna alternativa che elenco sotto risolve un tipo specifico di problema. Non sono sostituti dell'SVD perché operano con ipotesi e vincoli diversi. La scelta giusta, come sempre, dipende dal compito che devi svolgere.
L'autodecomposizione è la più vicina all'SVD. Scompone una matrice quadrata in autovalori e autovettori:
Formula dell'autodecomposizione
Dove Q contiene gli autovettori e \Lambda è una matrice diagonale di autovalori.
La limitazione è che funziona solo su matrici quadrate. Se la tua matrice di dati è m x n con m != n, l'autodecomposizione non può lavorarci direttamente. L'SVD funziona con qualsiasi forma di matrice, perciò è lo strumento più generale.
Per matrici quadrate e simmetriche (come le matrici di covarianza), autodecomposizione e SVD producono risultati strettamente correlati. I valori singolari di una matrice simmetrica semidefinita positiva sono i suoi autovalori. Quindi, se lavori con matrici di covarianza nella PCA, entrambi i metodi portano agli stessi risultati. L'SVD è semplicemente la versione che si generalizza ai casi non quadrati.
La decomposizione QR divide una matrice in una matrice ortogonale Q e in una matrice triangolare superiore R:
Formula della decomposizione QR
È più veloce dell'SVD per determinati compiti, in particolare per risolvere sistemi di equazioni lineari e problemi ai minimi quadrati.
Il compromesso riguarda le informazioni. La QR non fornisce valori singolari, quindi non può dirti nulla sul rango della matrice o su quali componenti pesano di più. Se devi risolvere Ax = b e non ti interessa la struttura sottostante, la QR è una buona opzione. Ma se devi comprendere o comprimere i dati, l'SVD è la scelta migliore.
La NMF scompone una matrice in due matrici in cui tutti i valori sono non negativi:
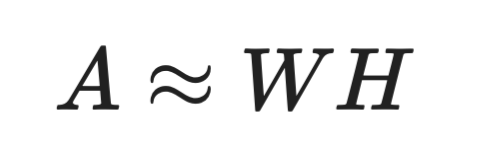
Formula NMF
Questo vincolo rende la NMF perfetta per dati intrinsecamente non negativi (pensa alle intensità dei pixel o ai conteggi di parole). L'SVD, invece, non impone questo vincolo. Le sue matrici decomposte possono avere valori negativi, il che a volte produce componenti difficili da interpretare.
La NMF è particolarmente popolare nel text mining e nel topic modeling. Ogni colonna di W può rappresentare un argomento e ogni riga di H mostra quanto di quell'argomento compare in ciascun documento. Il vincolo di non negatività significa che i topic sono costruiti da combinazioni additive di parole, il che li rende più leggibili rispetto ai componenti a segno misto dell'SVD.
Lo svantaggio è che la NMF non garantisce una soluzione unica e i risultati dipendono dall'inizializzazione. L'SVD produce sempre lo stesso output a parità di input.
Se la tua matrice è troppo grande per l'SVD completa ma vuoi comunque i valori singolari, l'SVD randomizzata merita attenzione. Usa proiezioni casuali per approssimare i primi k valori singolari e i relativi vettori senza calcolare la decomposizione completa. Librerie come scikit-learn (TruncatedSVD) e il fbpca di Facebook implementano questo approccio, e scala bene a matrici con milioni di righe.
La tabella seguente riassume quando scegliere ciascun metodo.
Alternative all'SVD
Un paio di cose comuni confondono molti nuovi data scientist.
La prima è interpretare male i valori singolari. Un valore singolare grande significa che quella componente spiega molta varianza nei dati — non che quella componente sia "importante" in senso specifico del dominio. Ad esempio, il valore singolare dominante in una matrice di valutazioni utenti potrebbe catturare il fatto che la maggior parte delle persone valuta i film popolari, non un pattern di preferenze significativo. Interpreta sempre i valori singolari nel contesto dei tuoi dati, non solo in base alla loro grandezza.
La seconda è usare l'SVD quando non serve. Su dataset piccoli (qualche centinaio di righe e poche colonne), l'SVD aggiunge solo complessità inutile. Metodi semplici come l'analisi di correlazione o una selezione di feature di base spesso bastano e richiedono meno codice. L'SVD è ottima quando hai dati ad alta dimensionalità con struttura ridondante — se il tuo dataset non rientra in questa descrizione, preferisci metodi più semplici.
L'SVD scompone qualsiasi matrice in tre componenti che ne mostrano la struttura. I valori singolari ti dicono quali parti dei dati contano di più e i vettori singolari sinistri e destri mostrano i pattern di righe e colonne che li generano.
Questa decomposizione è alla base di molti strumenti pratici che usi ogni giorno. I sistemi di raccomandazione la usano per prevedere valutazioni mancanti. La compressione delle immagini la usa per ridurre le dimensioni dei file mantenendo la qualità visiva. La matematica è quasi identica, anche se il dominio è completamente diverso.
Ma l'SVD non è sempre lo strumento giusto. È costosa su matrici grandi e può mescolare segnale e rumore quando i valori singolari non si separano bene. Inoltre, è eccessiva per dataset piccoli. Alternative come la decomposizione QR, l'autodecomposizione e la NMF gestiscono meglio casi specifici.
La chiave è sapere quando usare l'SVD e quando qualcosa di più semplice funziona meglio. E per acquisire questa conoscenza, iscriviti al nostro percorso Machine Learning Scientist in Python e diventa pronto per il lavoro nel 2026.
Impara con DataCamp
Corso
Corso
Corso