
Cours
Classifieurs linéaires en Python
4 h
66.6K
Avez-vous déjà tenté d’extraire des motifs utiles d’un jeu de données avec des milliers de variables ?
Vous savez qu’un vaste jeu de données recèle forcément une structure exploitable. Le problème, c’est qu’à l’état brut, il contient beaucoup de bruit, de redondance, des valeurs manquantes, et bien plus de dimensions que nécessaire. La plupart des algorithmes d’apprentissage automatique peinent à appréhender ce type de données, ou au mieux, allongent fortement le temps d’entraînement.
La décomposition en valeurs singulières (SVD) décompose toute matrice (un jeu de données, dans notre cas) en trois matrices plus simples qui en dévoilent la structure centrale. C’est la base mathématique des systèmes de recommandation, de la compression d’images et des techniques de réduction de dimension comme la PCA ; une fois comprise, vous la verrez partout dans votre quotidien professionnel.
Dans cet article, je vous présente ce qu’est la SVD, son fonctionnement, ses usages en data science, et quand privilégier une alternative.
Les notions comme les vecteurs et les déterminants vous embrouillent ? Lisez notre article Démystifier les concepts mathématiques pour le deep learning avant de poursuivre.
La SVD est une méthode qui décompose n’importe quelle matrice en trois matrices plus simples.
Voyez-le ainsi. Vous avez une matrice A — il peut s’agir d’un jeu de données ou d’une image. La SVD scinde A en trois éléments :
Formule de la SVD
U est une matrice orthogonale m x m. Ses colonnes sont les vecteurs singuliers gauches et décrivent les relations entre les lignes de A
\Sigma est une matrice diagonale m x n. Les valeurs sur la diagonale sont les valeurs singulières — toujours non négatives et triées de la plus grande à la plus petite
V* est la transposée conjuguée d’une matrice orthogonale n x n. Ses lignes sont les vecteurs singuliers droits et décrivent les relations entre les colonnes de A
Chaque composante révèle un aspect différent des données d’origine. U porte les motifs au niveau des lignes (comment elles se relient), \Sigma les pondérations d’importance (le poids de chaque motif), et V* les motifs au niveau des colonnes (leurs relations entre elles).
Une analogie : imaginez que vous décrivez une recette. Vous pouvez la scinder en trois parties : les ingrédients (quoi), les quantités (combien) et les étapes (comment). Aucune ne suffit à elle seule pour refaire le plat, mais ensemble, elles donnent tout le nécessaire. La SVD fait la même chose avec les matrices : elle sépare le « quoi », le « combien » et le « comment » en composantes distinctes que vous pouvez manipuler indépendamment.
La force de la SVD, en algèbre linéaire, c’est qu’elle fonctionne sur toute matrice. Elle n’a pas besoin d’être carrée ni de propriétés particulières. Toute matrice m x n peut être décomposée ainsi, d’où sa présence omniprésente en data science.
Voyons concrètement le fonctionnement de la SVD, pas à pas.
Supposons une matrice 3×2 A :
Décomposition matricielle
La SVD la décompose en U (3×3), \Sigma (3×2) et V* (2×2). Les colonnes de U proviennent des vecteurs propres de A x A^T, et les colonnes de V des vecteurs propres de A^T x A. Les valeurs singulières de \Sigma sont les racines carrées des valeurs propres de l’un ou l’autre produit.
La bonne nouvelle, c’est que vous n’avez pas à faire ces calculs à la main. En Python, une seule ligne suffit :
import numpy as np
A = np.array([[1, 2], [3, 4], [5, 6]])
U, sigma, Vt = np.linalg.svd(A, full_matrices=True)
Sortie Numpy
Les trois matrices interagissent par multiplication. U fait pivoter les données dans l’espace des lignes, \Sigma les met à l’échelle selon chaque axe, et V* fait pivoter dans l’espace des colonnes. Le résultat est la matrice d’origine A.
Les valeurs diagonales de \Sigma indiquent la contribution de chaque composante à la matrice globale.
La première valeur singulière est toujours la plus grande — elle capture le motif dominant des données. Chaque valeur suivante en capture moins. Si les premières valeurs singulières sont grandes et les autres proches de zéro, cela signifie que l’essentiel de l’information est concentré dans quelques composantes seulement.
C’est ce qui rend la compression des données possible.
Vous pouvez écarter les petites valeurs singulières (et leurs colonnes correspondantes dans U et lignes dans V*) sans perdre beaucoup d’information. On obtient ainsi une approximation de rang inférieur de la matrice d’origine, plus compacte et plus rapide à manipuler.
Le nombre de valeurs singulières non nulles indique aussi le rang de la matrice — le nombre de lignes ou de colonnes linéairement indépendantes. Si une matrice 100×50 n’a que 10 valeurs singulières non nulles, cela signifie que les données n’ont que 10 dimensions indépendantes. Les 40 autres sont redondantes.
Vous pouvez reconstruire la matrice d’origine en multipliant à nouveau les trois composantes :
Reconstruction de matrice
Mais l’intérêt réel, c’est la reconstruction partielle. Plutôt que d’utiliser toutes les valeurs singulières, vous ne gardez que les k premières et leurs vecteurs associés. Vous obtenez ainsi une approximation de rang k de A :
Approximation de matrice de rang k
Le théorème d’Eckart-Young garantit que cette approximation de rang k est la matrice de rang k la plus proche possible de la matrice d’origine A (au sens de la norme de Frobenius). En d’autres termes, si vous compressez une matrice à k dimensions, la SVD fournit le meilleur résultat possible.
Une fois que vous y prêtez attention, la SVD apparaît dans bien plus de cas que prévu.
L’idée : partir d’une grande matrice, conserver l’essentiel et éliminer le reste. Ce qui change, c’est la définition de « essentiel » selon le problème.
Les jeux de données à haute dimension sont difficiles à manipuler et à interpréter. Plus de variables signifie des entraînements plus longs et un risque accru de surapprentissage. La SVD limite cela en réduisant le nombre de dimensions.
Concrètement, vous décomposez votre matrice, examinez les valeurs singulières et ne conservez que les k premières composantes. Les petites valeurs singulières représentent du bruit et des variations mineures ; les supprimer affecte peu la qualité des données. Il reste une représentation compacte qui préserve l’essentiel de la structure.
C’est exactement le principe de l’analyse en composantes principales (PCA). La PCA centre les données puis applique la SVD. Les composantes principales sont les vecteurs singuliers droits, et les valeurs singulières indiquent la variance expliquée par chaque composante.
Des entreprises comme Netflix et Amazon manipulent d’immenses matrices utilisateur-produit où la plupart des entrées sont vides. Un utilisateur note quelques films parmi des milliers : la matrice est creuse. La SVD aide à combler ces trous.
Le principe : décomposer la matrice de notes en préférences utilisateurs et caractéristiques des items. La matrice U représente ce qui compte pour chaque utilisateur (genre, rythme, ton), et V* ce que propose chaque item. Les valeurs singulières de \Sigma pondèrent ces facteurs selon leur importance. En les remultipliant, on obtient des notes prédites pour des films qu’un utilisateur n’a pas encore vus.
En pratique, la SVD standard n’est pas directement adaptée aux matrices creuses, car elle traite les valeurs manquantes comme des zéros. D’où l’usage de variantes comme la SVD tronquée ou des méthodes de factorisation de matrices qui n’opèrent que sur les entrées observées.
Une image en niveaux de gris est simplement une matrice de pixels. La SVD peut la compresser en ne conservant que les valeurs singulières les plus importantes.
Prenons une image 1000×1000. La SVD complète fournit 1000 valeurs singulières. En n’en gardant que 50, vous reconstruisez l’image avec 50 composantes au lieu de 1000. L’image sera légèrement floue, mais reconnaissable — et le stockage passe d’1 000 000 de valeurs à environ 100 500 (50 colonnes de U + 50 valeurs singulières + 50 lignes de V*).
Plus vous gardez de valeurs singulières, meilleure est la qualité visuelle mais plus faible est la compression. Moins vous en gardez, plus le fichier est léger au prix d’une perte accrue. À vous d’ajuster selon l’usage.
Plus votre matrice est grande, plus le coût de calcul augmente.
La SVD complète sur une matrice m x n a une complexité temporelle O(mn²) (en supposant m >= n). Pour de petites matrices, cela convient. Pour des matrices avec des millions de lignes et des milliers de colonnes, cela devient coûteux.
La mémoire est l’autre goulot d’étranglement. La SVD complète produit trois matrices denses ; les stocker simultanément peut dépasser votre RAM disponible.
La solution consiste à éviter la SVD complète quand ce n’est pas nécessaire. La SVD tronquée ne calcule que les k plus grandes valeurs singulières et leurs vecteurs, bien plus rapidement. En Python, scipy.sparse.linalg.svds et sklearn.decomposition.TruncatedSVD le font. La SVD randomisée va plus loin en utilisant un échantillonnage aléatoire pour approximer la décomposition ; elle est efficace quand vous ne visez que les composantes dominantes.
La SVD est numériquement stable dans la plupart des cas, mais peut trébucher sur certains profils de données.
Un exemple : des données très bruyantes. Si le rapport signal/bruit est faible, les plus grandes valeurs singulières ne se détachent pas du bruit. En tronquant, vous risquez soit de conserver du bruit, soit d’éroder le signal.
Autre cas : les matrices mal conditionnées. Quand le rapport entre la plus grande et la plus petite valeur singulière est énorme (nombre de condition élevé), de petites erreurs numériques sont amplifiées. Les résultats peuvent devenir peu fiables, surtout avec les limites de précision en virgule flottante.
La bonne pratique consiste à examiner vos valeurs singulières avant de tronquer. Tracez-les et cherchez une chute nette entre signal et bruit. Si la décroissance est progressive, sans « coude » évident, la SVD n’est peut-être pas l’outil adapté à ce jeu de données.
La SVD n’est pas la seule décomposition matricielle, et ce n’est pas toujours le meilleur choix.
Chacune des alternatives ci-dessous répond à un besoin spécifique. Elles ne remplacent pas la SVD ; elles reposent sur d’autres hypothèses et contraintes. Comme toujours, le bon choix dépend de la tâche à accomplir.
L’eigendecomposition est la plus proche de la SVD. Elle décompose une matrice carrée en valeurs propres et vecteurs propres :
Formule de l’eigendecomposition
Où Q contient les vecteurs propres et \Lambda est une matrice diagonale de valeurs propres.
Limite : elle ne fonctionne que sur des matrices carrées. Si votre matrice de données est m x n avec m != n, vous ne pouvez pas l’appliquer directement. La SVD s’applique à toutes les formes, ce qui en fait l’outil le plus général.
Pour les matrices carrées et symétriques (comme les matrices de covariance), l’eigendecomposition et la SVD donnent des résultats étroitement liés. Les valeurs singulières d’une matrice symétrique définie positive au sens large sont ses valeurs propres. Ainsi, avec des matrices de covariance en PCA, les deux méthodes aboutissent aux mêmes résultats. La SVD est simplement la version qui se généralise aux cas non carrés.
La décomposition QR scinde une matrice en une matrice orthogonale Q et une matrice triangulaire supérieure R :
Formule de la décomposition QR
Elle est plus rapide que la SVD pour certaines tâches, notamment pour résoudre des systèmes d’équations linéaires et des problèmes aux moindres carrés.
Le compromis porte sur l’information. La QR ne fournit pas de valeurs singulières ; elle ne renseigne donc ni sur le rang de la matrice ni sur le poids relatif des composantes. Si vous devez résoudre Ax = b et que la structure sous-jacente importe peu, la QR est une bonne option. Si vous devez comprendre ou compresser les données, préférez la SVD.
La NMF décompose une matrice en deux matrices dont toutes les valeurs sont non négatives :
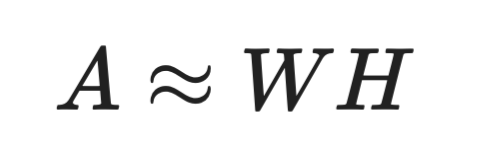
Formule de la NMF
Cette contrainte rend la NMF idéale pour des données intrinsèquement non négatives (intensités de pixels, occurrences de mots). À l’inverse, la SVD n’impose pas cette contrainte ; ses matrices décomposées peuvent contenir des valeurs négatives, ce qui peut compliquer l’interprétation.
La NMF est particulièrement prisée en text mining et en modélisation de sujets. Chaque colonne de W peut représenter un thème, et chaque ligne de H indique dans quelle mesure ce thème apparaît dans chaque document. La contrainte de non-négativité implique des combinaisons additives de mots, plus lisibles que les composantes à signes mixtes de la SVD.
Inconvénient : la NMF ne garantit pas une solution unique, et son résultat dépend de l’initialisation. La SVD, elle, donne toujours le même résultat pour une entrée donnée.
Si votre matrice est trop grande pour une SVD complète mais que vous souhaitez tout de même des valeurs singulières, la SVD randomisée vaut le détour. Elle utilise des projections aléatoires pour approximer les k plus grandes valeurs singulières et leurs vecteurs sans calculer la décomposition complète. Des bibliothèques comme scikit-learn (TruncatedSVD) et fbpca de Facebook implémentent cette approche, qui passe à l’échelle pour des matrices de plusieurs millions de lignes.
Le tableau ci-dessous récapitule quand choisir chaque méthode.
Alternatives à la SVD
Deux écueils reviennent souvent chez les débutants en data science.
Le premier concerne la mauvaise interprétation des valeurs singulières. Une grande valeur singulière signifie qu’une composante explique beaucoup de variance — pas qu’elle est « importante » au sens métier. Par exemple, la valeur singulière dominante dans une matrice de notes utilisateurs peut simplement refléter que la plupart des gens notent les films populaires, sans préférence significative. Interprétez toujours ces valeurs dans le contexte de vos données, pas seulement à partir de leur amplitude.
Le second est de recourir à la SVD sans nécessité. Sur de petits jeux de données (quelques centaines de lignes et peu de colonnes), la SVD ajoute de la complexité inutile. Des méthodes simples comme l’analyse de corrélation ou une sélection basique de variables font souvent le travail plus vite et avec moins de code. La SVD est idéale avec des données de haute dimension au fort potentiel de redondance ; si ce n’est pas votre cas, restez simple.
La SVD décompose toute matrice en trois composantes qui en révèlent la structure. Les valeurs singulières indiquent les parties qui comptent le plus, et les vecteurs singuliers gauches et droits dévoilent les motifs respectifs des lignes et des colonnes.
Cette décomposition sous-tend de nombreux outils concrets que vous utilisez au quotidien. Les systèmes de recommandation prédisent les notes manquantes grâce à elle. La compression d’images réduit la taille des fichiers tout en préservant la qualité visuelle. Les mathématiques derrière ces usages sont quasi identiques, bien que les domaines diffèrent.
Mais la SVD n’est pas toujours l’outil adéquat. Elle est coûteuse pour de grandes matrices et peut mêler signal et bruit quand les valeurs singulières se séparent mal. C’est aussi excessif pour de petits jeux de données. Des alternatives comme la décomposition QR, l’eigendecomposition et la NMF couvrent mieux certains cas.
L’essentiel est de savoir quand utiliser la SVD et quand une approche plus simple fera mieux. Pour acquérir ce discernement, inscrivez-vous à notre parcours Machine Learning Scientist in Python et soyez prêt·e pour l’emploi en 2026.
Apprenez avec DataCamp
Cours
Cours
Cours