
Curso
Clasificadores lineales en Python
4 h
66.6K
¿Alguna vez has intentado extraer patrones útiles de un conjunto de datos con miles de variables?
Sabes que en un dataset enorme tiene que haber cierta estructura valiosa escondida. El problema es que los datos en bruto arrastran mucho ruido, redundancia, valores perdidos y muchas más dimensiones de las que realmente necesitas. La mayoría de algoritmos de machine learning no sabrán interpretar bien este tipo de datos o, en el mejor de los casos, alargarán el tiempo de entrenamiento.
La descomposición en valores singulares (SVD) divide cualquier matriz (en este caso, el dataset) en tres matrices más simples que muestran su estructura esencial. Es la base matemática de los sistemas de recomendación, la compresión de imágenes y técnicas de reducción de dimensionalidad como PCA. Una vez la entiendas, la verás por todas partes en tu día a día.
En este artículo, te explicaré qué es SVD, cómo funciona, dónde se usa en ciencia de datos y cuándo conviene optar por una alternativa.
¿Te resultan confusos conceptos como vectores y determinantes? Lee antes nuestra publicación Desmitificando conceptos matemáticos para deep learning antes de continuar con esta.
SVD es un método que descompone cualquier matriz en tres matrices más simples.
Piensa en esto. Tienes una matriz A —puede ser un dataset o una imagen—. SVD divide A en tres piezas:
Fórmula de SVD
U es una matriz ortogonal m x m. Sus columnas se llaman vectores singulares izquierdos y describen las relaciones entre las filas de A
\Sigma es una matriz diagonal m x n. Los valores de la diagonal son los valores singulares: siempre no negativos y ordenados de mayor a menor
V* es la traspuesta conjugada de una matriz ortogonal n x n. Sus filas se llaman vectores singulares derechos y describen las relaciones entre las columnas de A
Cada pieza muestra algo distinto de los datos originales. U contiene los patrones a nivel de filas (cómo se relacionan entre sí), \Sigma guarda los pesos de importancia (cuánto aporta cada patrón) y V* contiene los patrones a nivel de columnas (cómo se relacionan entre sí).
Una analogía: imagina que le explicas una receta a alguien. Puedes dividirla en tres partes: los ingredientes (qué entra), las proporciones (cuánto de cada uno) y los pasos (cómo se combinan). Ninguna de estas partes por sí sola recrea el plato, pero juntas te dan todo lo necesario. SVD hace lo mismo con matrices: separa el "qué", el "cuánto" y el "cómo" en componentes que puedes manipular por separado.
Lo que distingue a SVD en álgebra lineal es que funciona con cualquier matriz. No tiene que ser cuadrada ni cumplir propiedades especiales. Cualquier matriz m x n puede descomponerse así, por eso aparece por todas partes en ciencia de datos.
Vamos a ver con detalle cómo funciona SVD, empezando por lo básico.
Supón que tienes una matriz 3×2 A:
Descomposición de matrices
SVD la descompone en U (3×3), \Sigma (3×2) y V* (2×2). Las columnas de U provienen de los vectores propios de A x A^T y las columnas de V provienen de los vectores propios de A^T x A. Los valores singulares en \Sigma son las raíces cuadradas de los valores propios de cualquiera de los dos productos.
La buena noticia es que no tienes que calcularlo a mano. En Python, te basta con una línea de código:
import numpy as np
A = np.array([[1, 2], [3, 4], [5, 6]])
U, sigma, Vt = np.linalg.svd(A, full_matrices=True)
Salida de Numpy
Las tres matrices interactúan mediante multiplicación. U rota los datos en el espacio de filas, \Sigma los escala en cada eje y V* los rota en el espacio de columnas. El resultado es la matriz original A.
Los valores de la diagonal de \Sigma te indican cuánto aporta cada componente a la matriz en su conjunto.
El primer valor singular siempre es el mayor: captura el patrón más dominante en los datos. Cada valor siguiente captura menos. Si los primeros valores singulares son grandes y el resto están cerca de cero, significa que la mayor parte de la información se concentra en unos pocos componentes.
Esto es lo que hace posible la compresión de datos.
Puedes descartar los valores singulares pequeños (y sus columnas correspondientes en U y filas en V*) sin perder apenas información. El resultado es una aproximación de rango inferior de la matriz original, más pequeña y ágil de manejar.
El número de valores singulares no nulos también te da el rango de la matriz —el número de filas o columnas linealmente independientes—. Si una matriz 100×50 tiene solo 10 valores singulares no nulos, significa que los datos tienen solo 10 dimensiones independientes. Las otras 40 son redundantes.
Puedes reconstruir la matriz original multiplicando de nuevo los tres componentes:
Reconstrucción de la matriz
Pero lo que realmente quieres es una reconstrucción parcial. En lugar de usar todos los valores singulares, conservas solo los k mayores y sus vectores correspondientes. Así obtienes una aproximación de rango k de A:
Aproximación de matriz de rango k
El teorema de Eckart-Young garantiza que esta aproximación de rango k es la matriz más cercana posible de rango k a la A original (medida con la norma de Frobenius). En otras palabras, si vas a comprimir una matriz a k dimensiones, SVD te da el mejor resultado posible.
Cuando te fijas, SVD aparece en más sitios de los que imaginas.
La idea siempre es tomar una matriz grande, quedarte con lo que importa y eliminar el resto. Lo que cambia es qué significa "importa" según el problema.
Los datasets de alta dimensionalidad son difíciles de manejar e interpretar. Más variables implican entrenamientos más largos y mayor riesgo de sobreajuste. SVD lo evita reduciendo el número de dimensiones.
En líneas generales: descompones tu matriz de datos, miras los valores singulares y conservas solo los k primeros componentes. Los valores singulares pequeños suelen representar ruido y variaciones menores, así que eliminarlos apenas afecta a la calidad. Lo que te queda es una representación compacta que conserva la mayor parte de la estructura original.
Así es exactamente como funciona principal component analysis (PCA). PCA centra los datos y luego ejecuta SVD sobre el resultado. Los componentes principales son los vectores singulares derechos, y los valores singulares te dicen cuánta varianza explica cada componente.
Empresas como Netflix y Amazon tienen enormes matrices usuario–ítem donde la mayoría de entradas están vacías. Un usuario puntúa unas pocas películas de entre miles, así que la matriz es dispersa. SVD ayuda a rellenar esos huecos.
La idea es descomponer la matriz de valoraciones en preferencias de usuario y características de ítem. La matriz U representa lo que valora cada usuario (género, ritmo, tono) y V* lo que ofrece cada ítem. Los valores singulares en \Sigma escalan estos factores por importancia. Al multiplicarlas de nuevo, obtienes valoraciones previstas para películas que el usuario aún no ha visto.
En la práctica, la SVD estándar no funciona directamente con matrices dispersas porque trata los valores faltantes como ceros. Por eso se usan variantes como la SVD truncada o métodos de factorización de matrices que operan solo sobre las entradas observadas.
Una imagen en escala de grises no es más que una matriz de valores de píxel. SVD puede comprimirla quedándose solo con los valores singulares más importantes.
Imagina una imagen de 1000×1000. La SVD completa te da 1000 valores singulares. Pero si conservas solo los 50 primeros, reconstruyes la imagen con 50 componentes en lugar de 1000. Se verá algo más borrosa, pero reconocible, y el almacenamiento baja de 1.000.000 valores a unos 100.500 (50 columnas de U + 50 valores singulares + 50 filas de V*).
Más valores singulares implican mejor calidad de imagen pero menos compresión. Menos valores implican archivos más pequeños pero más pérdida. Tú decides dónde está el equilibrio según tu caso de uso.
Cuanto mayor sea tu matriz, mayor será el coste computacional.
La SVD completa sobre una matriz m x n tiene una complejidad temporal de O(mn²) (asumiendo m >= n). Para matrices pequeñas, bien. Para una con millones de filas y miles de columnas, es costoso.
La memoria es el otro cuello de botella. La SVD completa produce tres matrices densas y almacenarlas todas a la vez puede superar tu RAM disponible.
La solución es evitar calcular la SVD completa cuando no la necesitas. La SVD truncada calcula solo los k valores singulares superiores y sus vectores, mucho más rápido. En Python, scipy.sparse.linalg.svds y sklearn.decomposition.TruncatedSVD lo implementan. La SVD aleatoria va más allá usando muestreo aleatorio para aproximar la descomposición y funciona bien cuando solo necesitas los componentes dominantes.
SVD es numéricamente estable en la mayoría de casos, pero puede tener dificultades con ciertos patrones de datos.
Los datos con mucho ruido son un ejemplo. Si la relación señal-ruido es baja, los valores singulares superiores no se separan del ruido. Terminarás conservando ruido en tu aproximación o reduciendo señal al truncar.
Las matrices mal condicionadas son otro problema. Cuando la relación entre el mayor y el menor valor singular es enorme (número de condición alto), pequeños errores numéricos durante el cálculo se amplifican. Esto puede dar resultados poco fiables, sobre todo con las limitaciones de precisión en coma flotante.
La solución es inspeccionar tus valores singulares antes de truncar. Represéntalos y busca una caída clara entre señal y ruido. Si el decaimiento es gradual y sin un "codo" evidente, quizá SVD no sea la mejor herramienta para ese dataset.
SVD no es la única descomposición de matrices que existe, ni siempre es la mejor opción para cada tarea.
Cada alternativa que verás a continuación resuelve un tipo de problema concreto. No sustituyen a SVD porque parten de supuestos y restricciones distintos. La elección adecuada, como siempre, depende de lo que quieras hacer.
Eigendecomposition es la más cercana a SVD. Descompone una matriz cuadrada en valores propios y vectores propios:
Fórmula de eigendecomposition
Donde Q contiene los vectores propios y \Lambda es una matriz diagonal de valores propios.
El pero es que solo funciona con matrices cuadradas. Si tu matriz de datos es m x n y m != n, eigendecomposition no puede aplicarse directamente. SVD funciona con cualquier forma, por eso es la herramienta más general.
Para matrices cuadradas y simétricas (como las de covarianzas), eigendecomposition y SVD dan resultados estrechamente relacionados. Los valores singulares de una matriz simétrica semidefinida positiva son sus valores propios. Así que si trabajas con matrices de covarianza en PCA, ambos métodos te llevan a lo mismo. SVD es simplemente la versión que se generaliza a casos no cuadrados.
QR decomposition divide una matriz en una matriz ortogonal Q y una matriz triangular superior R:
Fórmula de la descomposición QR
Es más rápida que SVD para ciertas tareas, especialmente para resolver sistemas de ecuaciones lineales y problemas de mínimos cuadrados.
El peaje es la información. QR no te da valores singulares, así que no puede decirte nada sobre el rango de tu matriz ni qué componentes pesan más. Si necesitas resolver Ax = b y no te preocupa la estructura subyacente, QR es una buena opción. Pero si necesitas entender o comprimir los datos, SVD es mejor elección.
NMF descompone una matriz en dos matrices con todos sus valores no negativos:
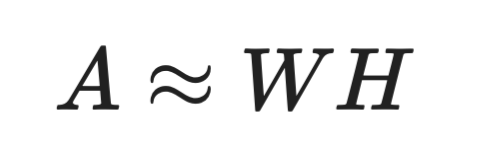
Fórmula de NMF
Esta restricción hace que NMF encaje muy bien con datos intrínsecamente no negativos (piensa en intensidades de píxel o recuentos de palabras). En cambio, SVD no impone esa condición: sus matrices descompuestas pueden tener valores negativos, lo que a veces produce componentes difíciles de interpretar.
NMF es especialmente popular en minería de texto y modelización de temas. Cada columna de W puede representar un tema y cada fila de H indica cuánto de ese tema aparece en cada documento. La restricción de no negatividad implica que los temas se construyen como combinaciones aditivas de palabras, lo que los hace más fáciles de leer que los componentes con signos mixtos de SVD.
La desventaja es que NMF no garantiza una solución única y los resultados dependen de la inicialización. SVD siempre produce la misma salida para la misma entrada.
Si tu matriz es demasiado grande para una SVD completa pero aún quieres valores singulares, la SVD aleatoria es una buena opción. Usa proyecciones aleatorias para aproximar los k valores singulares y vectores superiores sin calcular la descomposición completa. Librerías como scikit-learn (TruncatedSVD) y el fbpca de Facebook implementan este enfoque y escalan bien a matrices con millones de filas.
La tabla siguiente resume cuándo optar por cada método.
Alternativas a SVD
Hay un par de cosas habituales que confunden a quienes empiezan en ciencia de datos.
La primera es interpretar mal los valores singulares. Un valor singular grande significa que ese componente explica mucha varianza en los datos; no significa que sea "importante" en el sentido del dominio. Por ejemplo, el valor singular dominante en una matriz de valoraciones de usuarios puede reflejar que la mayoría puntúa las películas populares, no un patrón real de preferencias. Interprétalos siempre en el contexto de tus datos, no solo por su magnitud.
La segunda es recurrir a SVD cuando no hace falta. En datasets pequeños (unos cientos de filas y pocas columnas), SVD añade complejidad innecesaria. Métodos sencillos como el análisis de correlación o la selección básica de variables suelen bastar y son más rápidos. SVD es ideal cuando tienes datos de alta dimensionalidad con estructura redundante; si tu dataset no encaja en esa descripción, opta por métodos más simples.
SVD descompone cualquier matriz en tres componentes que revelan su estructura. Los valores singulares te dicen qué partes de los datos tienen más peso y los vectores singulares izquierdo y derecho muestran los patrones de filas y columnas que hay detrás.
Esa descomposición está detrás de muchas herramientas prácticas que usas a diario. Los sistemas de recomendación la usan para predecir valoraciones faltantes. La compresión de imágenes la usa para reducir el tamaño de archivo manteniendo la calidad visual. Las matemáticas detrás son casi idénticas, aunque el dominio sea completamente distinto.
Pero SVD no siempre es la herramienta adecuada. Es costosa en matrices grandes y puede mezclar señal y ruido cuando los valores singulares no se separan bien. Además, es excesiva para datasets pequeños. Alternativas como la descomposición QR, eigendecomposition y NMF resuelven mejor casos específicos.
La clave es saber cuándo usar SVD y cuándo algo más simple funcionará mejor. Y para adquirir ese criterio, apúntate a nuestro Machine Learning Scientist in Python track y prepárate para trabajar en 2026.
Aprende con DataCamp
Curso
Curso
Curso