
Curso
Classificadores Lineares em Python
4 h
66.6K
Você já tentou extrair padrões úteis de um dataset com milhares de variáveis?
Você sabe que um dataset enorme certamente esconde alguma estrutura valiosa. O problema é que dados brutos carregam muito ruído, redundância, valores ausentes e bem mais dimensões do que você realmente precisa. A maioria dos algoritmos de machine learning teria dificuldade para entender esse tipo de dado ou, no melhor dos casos, deixaria o treino muito mais lento.
A decomposição em valores singulares (SVD) divide qualquer matriz (neste caso, um dataset) em três matrizes mais simples que mostram sua estrutura central. É a matemática por trás de sistemas de recomendação, compressão de imagens e técnicas de redução de dimensionalidade como PCA — e, quando você entende, começa a enxergá-la em tudo no seu dia a dia.
Neste artigo, vou explicar o que é SVD, como funciona, onde é usado em ciência de dados e quando é melhor optar por uma alternativa.
Conceitos como vetores e determinantes deixam você confuso? Leia nosso post Desmistificando conceitos matemáticos para deep learning antes de continuar este aqui.
SVD é um método que divide qualquer matriz em três matrizes mais simples.
Pense assim. Você tem uma matriz A — pode ser um dataset ou uma imagem. O SVD divide A em três partes:
Fórmula de SVD
U é uma matriz ortogonal m x m. Suas colunas são chamadas de vetores singulares à esquerda e descrevem as relações entre as linhas de A
\Sigma é uma matriz diagonal m x n. Os valores na diagonal são os valores singulares — sempre não negativos e ordenados do maior para o menor
V* é a transposta conjugada de uma matriz ortogonal n x n. Suas linhas são chamadas de vetores singulares à direita e descrevem as relações entre as colunas de A
Cada parte revela algo diferente sobre os dados originais. U guarda os padrões em nível de linha (como as linhas se relacionam), \Sigma guarda os pesos de importância (quanto cada padrão importa) e V* guarda os padrões em nível de coluna (como as colunas se relacionam).
Uma analogia: imagine que você vai descrever uma receita para alguém. Você pode separar em três partes: os ingredientes (o que entra), as proporções (quanto de cada) e o modo de preparo (como tudo se combina). Nenhuma dessas partes sozinha recria o prato, mas juntas você tem tudo que precisa. O SVD faz o mesmo com matrizes — separa o “o quê”, “quanto” e “como” em componentes distintos com os quais você pode trabalhar separadamente.
O que torna o SVD especial na álgebra linear é que ele funciona em qualquer matriz. Não precisa ser quadrada nem ter propriedades específicas. Qualquer matriz m x n pode ser decomposta assim, por isso ele aparece em todo lugar na ciência de dados.
Vamos ver de perto como o SVD funciona, começando do início.
Suponha que você tenha uma matriz 3×2 A:
Decomposição de matriz
O SVD decompõe isso em U (3×3), \Sigma (3×2) e V* (2×2). As colunas de U vêm dos autovetores de A x A^T, e as colunas de V vêm dos autovetores de A^T x A. Os valores singulares em \Sigma são as raízes quadradas dos autovalores de qualquer um dos produtos.
A boa notícia é que você não precisa calcular isso à mão. Em Python, basta uma linha de código:
import numpy as np
A = np.array([[1, 2], [3, 4], [5, 6]])
U, sigma, Vt = np.linalg.svd(A, full_matrices=True)
Saída do Numpy
As três matrizes interagem por multiplicação. U rotaciona os dados no espaço das linhas, \Sigma escala em cada eixo e V* rotaciona no espaço das colunas. O resultado é a matriz original A.
Os valores na diagonal de \Sigma indicam quanto cada componente contribui para a matriz como um todo.
O primeiro valor singular é sempre o maior — ele captura o padrão mais dominante nos dados. Cada valor seguinte captura menos. Se os primeiros valores singulares forem grandes e o restante próximo de zero, significa que a maior parte da informação está concentrada em poucos componentes.
É isso que viabiliza a compressão de dados.
Você pode descartar os valores singulares pequenos (e suas colunas correspondentes em U e linhas em V*) sem perder muita informação. O resultado é uma aproximação de menor posto da matriz original, menor e mais rápida de trabalhar.
O número de valores singulares não nulos também indica o posto da matriz — o número de linhas ou colunas linearmente independentes. Se uma matriz 100×50 tem apenas 10 valores singulares não nulos, os dados têm só 10 dimensões independentes. As outras 40 são redundantes.
Você pode reconstruir a matriz original multiplicando os três componentes novamente:
Reconstrução de matriz
Mas o que você realmente quer é a reconstrução parcial. Em vez de usar todos os valores singulares, você mantém apenas os k maiores e seus vetores correspondentes. Isso gera uma aproximação de posto k de A:
Aproximação de matriz de posto k
O teorema de Eckart-Young garante que essa aproximação de posto k é a matriz mais próxima possível de posto k da original A (medida pela norma de Frobenius). Em outras palavras, se você vai comprimir uma matriz para k dimensões, o SVD dá o melhor resultado possível.
Quando você começa a procurar, o SVD aparece em muito mais lugares do que imagina.
A ideia é sempre pegar uma matriz grande, manter as partes que importam e remover o resto. O que muda é o que “importa”, dependendo do problema.
Datasets com muitas dimensões são difíceis de trabalhar e interpretar. Mais variáveis significam treinos mais longos e maior risco de overfitting. O SVD evita isso reduzindo o número de dimensões.
Em linhas gerais, você decompõe sua matriz de dados, olha para os valores singulares e mantém apenas os k principais componentes. Os valores singulares pequenos representam ruído e variações menores, então removê-los mal afeta a qualidade. O que sobra é uma representação compacta que preserva a maior parte da estrutura original.
É exatamente assim que o Principal Component Analysis (PCA) funciona. O PCA centraliza os dados e aplica SVD no resultado. Os componentes principais são os vetores singulares à direita, e os valores singulares indicam quanta variância cada componente explica.
Empresas como Netflix e Amazon têm enormes matrizes usuário-itens em que a maioria das entradas está vazia. Um usuário avalia poucos filmes entre milhares, então a matriz é esparsa. O SVD entra para preencher as lacunas.
A ideia é decompor a matriz de avaliações em preferências do usuário e características do item. A matriz U representa o que cada usuário valoriza (gênero, ritmo, tom), e V* representa o que cada item oferece. Os valores singulares em \Sigma escalam esses fatores por importância. Ao multiplicá-los novamente, você obtém avaliações previstas para filmes que o usuário ainda não viu.
Na prática, o SVD padrão não funciona diretamente em matrizes esparsas porque trata valores ausentes como zeros. Por isso, sistemas usam variações como SVD truncado ou métodos de fatoração de matrizes que operam apenas nas entradas observadas.
Uma imagem em escala de cinza é apenas uma matriz de valores de pixels. O SVD pode comprimi-la mantendo apenas os valores singulares mais importantes.
Suponha uma imagem 1000×1000. O SVD completo gera 1000 valores singulares. Mas, se você mantiver apenas os 50 maiores, reconstrói a imagem com 50 componentes em vez de 1000. A imagem ficará um pouco mais borrada, mas reconhecível — e o armazenamento cai de 1.000.000 valores para cerca de 100.500 (50 colunas de U + 50 valores singulares + 50 linhas de V*).
Mais valores singulares significam melhor qualidade de imagem, porém menos compressão. Menos valores significam arquivos menores, mas mais perda. Você escolhe o ponto de equilíbrio conforme o seu caso de uso.
Quanto maior a matriz, maior o custo computacional que você vai encarar.
O SVD completo em uma matriz m x n tem complexidade de tempo O(mn²) (assumindo m >= n). Para matrizes pequenas, tudo bem. Para uma matriz com milhões de linhas e milhares de colunas, fica caro.
Memória é outro gargalo. O SVD completo produz três matrizes densas, e armazená-las ao mesmo tempo pode ultrapassar sua RAM disponível.
A solução é evitar calcular o SVD completo quando não for necessário. O SVD truncado calcula apenas os k maiores valores singulares e seus vetores — muito mais rápido. Em Python, scipy.sparse.linalg.svds e sklearn.decomposition.TruncatedSVD fazem isso. O SVD randomizado vai além, usando amostragem aleatória para aproximar a decomposição — ótimo quando você só precisa dos componentes dominantes.
O SVD é numericamente estável na maioria dos casos, mas pode ter dificuldades com alguns padrões de dados.
Dados com muito ruído são um exemplo. Se a razão sinal-ruído é baixa, os maiores valores singulares não se separam do ruído. Você pode acabar mantendo ruído na aproximação ou reduzindo sinal ao truncar.
Matrizes mal condicionadas são outro problema. Quando a razão entre o maior e o menor valor singular é enorme (número de condicionamento alto), pequenos erros numéricos durante o cálculo são amplificados. Isso pode gerar resultados pouco confiáveis, especialmente com limitações de precisão em ponto flutuante.
A solução é inspecionar os valores singulares antes de truncar. Plote-os e procure uma queda clara entre sinal e ruído. Se a queda for gradual, sem um “cotovelo” evidente, o SVD pode não ser a melhor ferramenta para aquele dataset.
O SVD não é a única decomposição de matrizes e nem sempre é a melhor opção para toda tarefa.
Cada alternativa abaixo resolve um tipo específico de problema. Não são substitutos do SVD porque partem de premissas e restrições diferentes. A escolha certa, como sempre, depende da tarefa que você quer realizar.
Eigendecomposition é a mais próxima do SVD. Ela decompõe uma matriz quadrada em autovalores e autovetores:
Fórmula da decomposição espectral
Em que Q guarda os autovetores e \Lambda é uma matriz diagonal de autovalores.
A questão é que ela só funciona em matrizes quadradas. Se sua matriz de dados é m x n com m != n, a eigendecomposition não funciona diretamente. O SVD funciona em qualquer formato, por isso é a ferramenta mais geral.
Para matrizes quadradas e simétricas (como matrizes de covariância), eigendecomposition e SVD produzem resultados muito próximos. Os valores singulares de uma matriz simétrica semidefinida positiva são seus autovalores. Então, se você trabalha com matrizes de covariância no PCA, ambos chegam aos mesmos resultados. O SVD é apenas a versão que generaliza para casos não quadrados.
A decomposição QR divide uma matriz em uma matriz ortogonal Q e uma matriz triangular superior R:
Fórmula da decomposição QR
Ela é mais rápida que o SVD para certas tarefas, especialmente para resolver sistemas de equações lineares e problemas de mínimos quadrados.
O trade-off é informação. A QR não fornece valores singulares, então não informa o posto da matriz nem quais componentes carregam mais peso. Se você precisa resolver Ax = b e não se importa com a estrutura subjacente, QR é uma boa opção. Mas se você precisa entender ou comprimir os dados, SVD é a melhor escolha.
A NMF decompõe uma matriz em duas matrizes cujos valores são todos não negativos:
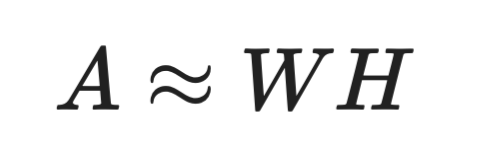
Fórmula de NMF
Essa restrição torna a NMF ótima para dados que são intrinsecamente não negativos (pense em intensidades de pixels ou contagem de palavras). Já o SVD não impõe isso: suas matrizes decompostas podem ter valores negativos, o que às vezes gera componentes difíceis de interpretar.
A NMF é especialmente popular em mineração de texto e modelagem de tópicos. Cada coluna de W pode representar um tópico, e cada linha de H mostra quanto daquele tópico aparece em cada documento. A restrição de não negatividade faz com que os tópicos sejam combinações aditivas de palavras, o que os torna mais fáceis de ler do que os componentes com sinais mistos do SVD.
O ponto negativo é que a NMF não garante solução única e seus resultados dependem da inicialização. O SVD sempre produz a mesma saída para a mesma entrada.
Se sua matriz é grande demais para SVD completo mas você ainda quer valores singulares, o SVD randomizado vale a pena. Ele usa projeções aleatórias para aproximar os k maiores valores singulares e vetores sem calcular a decomposição completa. Bibliotecas como scikit-learn (TruncatedSVD) e o fbpca do Facebook implementam essa abordagem, que escala bem para matrizes com milhões de linhas.
A tabela abaixo resume quando escolher cada método.
Alternativas ao SVD
Algumas coisas comuns confundem quem está começando em ciência de dados.
A primeira é interpretar mal os valores singulares. Um valor singular grande significa que aquele componente explica muita variância nos dados — não que ele seja “importante” do ponto de vista do domínio. Por exemplo, o valor singular dominante em uma matriz de avaliações de usuários pode capturar o fato de que a maioria das pessoas avalia filmes populares, e não um padrão de preferência relevante. Sempre interprete os valores singulares no contexto dos seus dados, não apenas pela magnitude.
A segunda é recorrer ao SVD quando não precisa. Em datasets pequenos (algumas centenas de linhas e poucas colunas), o SVD só adiciona complexidade desnecessária. Métodos simples como análise de correlação ou seleção básica de variáveis costumam resolver mais rápido e com menos código. O SVD é ótimo quando você tem dados de alta dimensionalidade com estrutura redundante — se seu dataset não se encaixa nisso, prefira métodos mais simples.
O SVD divide qualquer matriz em três componentes que revelam sua estrutura. Os valores singulares mostram quais partes dos dados mais importam, e os vetores singulares à esquerda e à direita revelam os padrões de linhas e colunas por trás deles.
Essa decomposição está por trás de várias ferramentas práticas que você usa no dia a dia. Sistemas de recomendação a usam para prever avaliações ausentes. Compressão de imagens a usa para reduzir o tamanho de arquivos mantendo a qualidade visual. A matemática é quase idêntica, mesmo com domínios completamente diferentes.
Mas o SVD nem sempre é a melhor ferramenta. Ele é caro em matrizes grandes e pode misturar sinal com ruído quando os valores singulares não se separam bem. Além disso, é exagero para datasets pequenos. Alternativas como decomposição QR, eigendecomposition e NMF lidam melhor com casos específicos.
A chave é saber quando usar o SVD e quando algo mais simples resolve melhor. E para adquirir esse conhecimento, inscreva-se na nossa trilha Machine Learning Scientist in Python e fique pronto para o mercado em 2026.
Aprenda com a DataCamp
Curso
Curso
Curso