
Kurs
Lineare Klassifikatoren in Python
4 Std.
66.6K
Hast du schon einmal versucht, in einem Datensatz mit Tausenden von Merkmalen sinnvolle Muster zu finden?
Du weißt, dass in einem riesigen Datensatz eine brauchbare Struktur steckt. Das Problem: Rohdaten enthalten viel Rauschen, Redundanz, fehlende Werte und deutlich mehr Dimensionen, als du tatsächlich brauchst. Die meisten Machine-Learning-Algorithmen kommen damit kaum zurecht oder verlangsamen zumindest das Training massiv.
Die Singulärwertzerlegung (SVD) zerlegt jede Matrix (hier: den Datensatz) in drei einfachere Matrizen und legt so ihre Kernstruktur frei. Dahinter steckt die Mathematik von Empfehlungssystemen, Bildkompression und Dimensionsreduktionstechniken wie PCA – und wenn du sie einmal verstanden hast, wirst du sie in deinem Arbeitsalltag überall entdecken.
In diesem Artikel zeige ich dir, was SVD ist, wie sie funktioniert, wo sie in der Data Science eingesetzt wird und wann du besser zu einer Alternative greifst.
Findest du Konzepte wie Vektoren und Determinanten verwirrend? Lies unseren Demystifying Mathematical Concepts for Deep Learning-Beitrag, bevor du hier weitermachst.
SVD ist eine Methode, die jede Matrix in drei einfachere Matrizen zerlegt.
Stell es dir so vor. Du hast eine Matrix A – das kann ein Datensatz oder ein Bild sein. SVD zerlegt A in drei Teile:
SVD-Formel
U ist eine orthogonale m x m-Matrix. Ihre Spalten heißen linke Singulärvektoren und beschreiben die Beziehungen zwischen den Zeilen von A
\Sigma ist eine diagonale m x n-Matrix. Die Werte auf der Diagonale sind die Singulärwerte – sie sind stets nicht negativ und absteigend sortiert
V* ist die konjugiert transponierte einer orthogonalen n x n-Matrix. Ihre Zeilen heißen rechte Singulärvektoren und beschreiben die Beziehungen zwischen den Spalten von A
Jede Komponente zeigt einen anderen Aspekt der Originaldaten. U enthält die Muster auf Zeilenebene (wie Zeilen zusammenhängen), \Sigma enthält die Wichtigkeitsgewichte (wie stark jedes Muster zählt) und V* die Muster auf Spaltenebene (wie Spalten zusammenhängen).
Hier ist eine Analogie: Stell dir vor, du beschreibst jemandem ein Rezept. Du kannst es in drei Teile zerlegen: die Zutaten (was hinein kommt), die Mengen (wieviel wovon) und die Schritte (wie alles zusammenkommt). Keiner dieser Teile allein ergibt das Gericht, aber zusammen hast du alles, was du wissen musst. SVD macht dasselbe mit Matrizen – sie trennt das „Was“, „Wieviel“ und „Wie“ in eigenständige Bausteine, mit denen du unabhängig arbeiten kannst.
Das Besondere an SVD in der linearen Algebra ist: Sie funktioniert für jede Matrix. Sie muss weder quadratisch sein noch besondere Eigenschaften haben. Jede m x n-Matrix lässt sich so zerlegen – deshalb begegnet sie dir überall in der Data Science.
Schauen wir uns Schritt für Schritt an, wie SVD funktioniert.
Angenommen, du hast eine 3×2-Matrix A:
Matrixzerlegung
SVD zerlegt diese in U (3×3), \Sigma (3×2) und V* (2×2). Die Spalten von U stammen aus den Eigenvektoren von A x A^T, und die Spalten von V aus den Eigenvektoren von A^T x A. Die Singulärwerte in \Sigma sind die Quadratwurzeln der Eigenwerte aus einem der beiden Produkte.
Die gute Nachricht: Du musst das nicht von Hand ausrechnen. In Python reicht eine einzige Codezeile:
import numpy as np
A = np.array([[1, 2], [3, 4], [5, 6]])
U, sigma, Vt = np.linalg.svd(A, full_matrices=True)
Numpy-Ausgabe
Die drei Matrizen wirken per Multiplikation zusammen. U rotiert die Daten im Zeilenraum, \Sigma skaliert sie entlang jeder Achse und V* rotiert im Spaltenraum. Das Ergebnis ist die ursprüngliche Matrix A.
Die Diagonalwerte in \Sigma zeigen, wie stark jede Komponente zur Gesamtmatrix beiträgt.
Der erste Singulärwert ist immer der größte – er erfasst das dominanteste Muster in den Daten. Jeder folgende erfasst weniger. Sind die ersten wenigen Singulärwerte groß und der Rest nahe Null, steckt der Großteil der Information in nur wenigen Komponenten.
Das macht Datenkompression möglich.
Du kannst kleine Singulärwerte (und die zugehörigen Spalten in U sowie Zeilen in V*) weglassen, ohne viel Information zu verlieren. Das Ergebnis ist eine Niedrigrang-Approximation der ursprünglichen Matrix, die kleiner ist und sich schneller verarbeiten lässt.
Die Anzahl der von Null verschiedenen Singulärwerte verrät dir außerdem den Rang der Matrix – also die Zahl linear unabhängiger Zeilen oder Spalten. Hat eine 100×50-Matrix nur 10 nichtverschwindende Singulärwerte, hat die Datenstruktur effektiv nur 10 unabhängige Dimensionen. Die übrigen 40 sind redundant.
Du kannst die Ursprungsmatrix rekonstruieren, indem du die drei Komponenten wieder multiplizierst:
Matrixrekonstruktion
Eigentlich willst du aber eine partielle Rekonstruktion. Statt alle Singulärwerte zu verwenden, behältst du nur die größten k Werte und die zugehörigen Vektoren. So erhältst du eine Rang-k-Approximation von A:
Rang-k-Matrixapproximation
Der Satz von Eckart-Young garantiert, dass diese Rang-k-Approximation die bestmögliche Matrix vom Rang k zur Originalmatrix A ist (gemessen mit der Frobenius-Norm). Mit anderen Worten: Wenn du eine Matrix auf k Dimensionen komprimierst, liefert dir SVD das bestmögliche Ergebnis.
Wenn du darauf achtest, taucht SVD an viel mehr Stellen auf, als du denkst.
Die Idee ist immer dieselbe: eine große Matrix nehmen, das Wesentliche behalten und den Rest entfernen. Was „wesentlich“ ist, hängt vom jeweiligen Problem ab.
Hochdimensionale Datensätze sind schwer zu handhaben und zu interpretieren. Mehr Merkmale bedeuten längere Trainingszeiten und ein höheres Overfitting-Risiko. SVD beugt dem vor, indem sie die Anzahl der Dimensionen reduziert.
Grob gesagt: Du zerlegst deine Datenmatrix, schaust dir die Singulärwerte an und behältst nur die größten k Komponenten. Kleine Singulärwerte stehen für Rauschen und geringe Variation – ihr Entfernen hat kaum Einfluss auf die Datenqualität. Übrig bleibt eine kompakte Darstellung, die den Großteil der ursprünglichen Struktur bewahrt.
Genau so funktioniert die Hauptkomponentenanalyse (PCA). PCA zentriert die Daten und führt anschließend SVD darauf aus. Die Hauptkomponenten sind die rechten Singulärvektoren, und die Singulärwerte zeigen, wie viel Varianz jede Komponente erklärt.
Unternehmen wie Netflix und Amazon haben riesige Benutzer-Item-Matrizen, in denen die meisten Einträge leer sind. Eine Nutzerin bewertet nur wenige Filme von Tausenden – die Matrix ist dünn besetzt. SVD hilft, die Lücken zu füllen.
Die Idee: die Bewertungsmatrix in Nutzerpräferenzen und Item-Eigenschaften zerlegen. Die U-Matrix repräsentiert, worauf einzelne Nutzer achten (Genre, Tempo, Tonalität), V* steht für das, was ein Item bietet. Die Singulärwerte in \Sigma skalieren diese Faktoren nach Wichtigkeit. Multiplizierst du alles wieder zusammen, erhältst du vorhergesagte Bewertungen für Filme, die ein Nutzer noch nicht gesehen hat.
In der Praxis funktioniert die Standard-SVD nicht direkt auf dünn besetzten Matrizen, weil sie fehlende Werte als Nullen behandelt. Deshalb kommen Varianten wie truncated SVD oder Matrixfaktorisierung zum Einsatz, die nur mit beobachteten Einträgen arbeiten.
Ein Graustufenbild ist nichts anderes als eine Matrix aus Pixelwerten. SVD kann es komprimieren, indem nur die wichtigsten Singulärwerte behalten werden.
Angenommen, du hast ein 1000×1000-Bild. Die vollständige SVD liefert 1000 Singulärwerte. Behältst du nur die Top 50, rekonstruierst du das Bild mit nur 50 Komponenten statt 1000. Das Bild wirkt etwas weichgezeichnet, bleibt aber erkennbar – und der Speicherbedarf sinkt von 1.000.000 Werten auf rund 100.500 (50 Spalten von U + 50 Singulärwerte + 50 Zeilen von V*).
Mehr Singulärwerte bedeuten bessere Bildqualität, aber weniger Kompression. Weniger Werte bedeuten kleinere Dateien, aber mehr Verlust. Du entscheidest je nach Anwendungsfall, wo du die Grenze ziehst.
Je größer die Matrix, desto höher die Rechenkosten.
Die vollständige SVD einer m x n-Matrix hat eine Zeitkomplexität von O(mn²) (unter der Annahme m >= n). Für kleine Matrizen ist das in Ordnung. Bei Millionen Zeilen und Tausenden Spalten wird es teuer.
Speicher ist der zweite Engpass. Die vollständige SVD erzeugt drei dichte Matrizen, deren gleichzeitiges Vorhalten den verfügbaren RAM sprengen kann.
Die Lösung: Verzichte auf die vollständige SVD, wenn du sie nicht brauchst. Truncated SVD berechnet nur die größten k Singulärwerte und ihre Vektoren – deutlich schneller. In Python leisten scipy.sparse.linalg.svds und sklearn.decomposition.TruncatedSVD genau das. Randomized SVD geht noch weiter und nutzt Zufallsstichproben zur Approximation der Zerlegung – ideal, wenn du nur die dominanten Komponenten brauchst.
SVD ist in den meisten Fällen numerisch stabil, kann aber mit bestimmten Datenmustern kämpfen.
Stark verrauschte Daten sind ein Beispiel. Ist das Signal-Rausch-Verhältnis gering, trennen sich die größten Singulärwerte nicht klar vom Rauschen. Kürzt du dann ab, behältst du Rauschen oder verlierst Signal.
Schlecht konditionierte Matrizen sind ein weiteres Problem. Wenn das Verhältnis zwischen größtem und kleinstem Singulärwert riesig ist (hohe Konditionszahl), verstärken sich kleine numerische Fehler bei der Berechnung. Das kann unzuverlässige Ergebnisse liefern – besonders bei begrenzter Gleitkomma-Genauigkeit.
Die Lösung: Untersuche deine Singulärwerte vor dem Abschneiden. Plotte sie und achte auf einen klaren Knick zwischen Signal und Rauschen. Wenn der Abfall langsam und ohne eindeutigen „Ellbogen“ verläuft, ist SVD für diesen Datensatz möglicherweise nicht das richtige Werkzeug.
SVD ist nicht die einzige Matrixzerlegung – und nicht immer die beste Wahl.
Jede der folgenden Alternativen löst eine bestimmte Art von Problem. Es sind keine Ersatzwerkzeuge für SVD, weil sie unter anderen Annahmen und Randbedingungen arbeiten. Die richtige Wahl hängt – wie immer – von deiner Aufgabe ab.
Eigendecomposition ist SVD am nächsten verwandt. Sie zerlegt eine quadratische Matrix in Eigenwerte und Eigenvektoren:
Eigendecomposition-Formel
Dabei enthält Q die Eigenvektoren und \Lambda ist eine Diagonalmatrix der Eigenwerte.
Der Haken: Sie funktioniert nur für quadratische Matrizen. Ist deine Datenmatrix m x n mit m != n, kannst du sie nicht direkt eigende-komponieren. SVD funktioniert für jede Form – daher ist sie das allgemeinere Werkzeug.
Für quadratische, symmetrische Matrizen (wie Kovarianzmatrizen) liefern Eigendecomposition und SVD eng verwandte Resultate. Die Singulärwerte einer symmetrischen positiv semidefiniten Matrix sind ihre Eigenwerte. Arbeitest du also in der PCA mit Kovarianzmatrizen, führen beide Methoden zum selben Ergebnis. SVD ist lediglich die Variante, die auch für nicht-quadratische Fälle verallgemeinert.
QR-Zerlegung spaltet eine Matrix in eine orthogonale Matrix Q und eine obere Dreiecksmatrix R:
QR-Zerlegungsformel
Für bestimmte Aufgaben ist sie schneller als SVD, insbesondere zum Lösen linearer Gleichungssysteme und von Least-Squares-Problemen.
Der Preis ist Information. QR liefert keine Singulärwerte – du erfährst also nichts über den Rang deiner Matrix oder die Gewichte der Komponenten. Wenn du Ax = b lösen willst und dir die Struktur egal ist, ist QR eine gute Option. Willst du Daten verstehen oder komprimieren, ist SVD die bessere Wahl.
NMF zerlegt eine Matrix in zwei Matrizen mit ausschließlich nichtnegativen Werten:
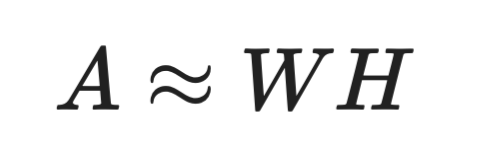
NMF-Formel
Diese Nebenbedingung macht NMF ideal für naturgemäß nichtnegative Daten (z. B. Pixelintensitäten oder Worthäufigkeiten). SVD erzwingt das nicht – die zerlegten Matrizen können negative Werte enthalten, was die Interpretation manchmal erschwert.
NMF ist besonders beliebt im Text Mining und Topic Modeling. Jede Spalte von W kann ein Thema darstellen, und jede Zeile von H zeigt, wie stark dieses Thema in einem Dokument vorkommt. Durch die Nichtnegativität entstehen additive Kombinationen von Wörtern – meist leichter lesbar als SVD-Komponenten mit gemischten Vorzeichen.
Der Nachteil: NMF garantiert keine eindeutige Lösung, und die Ergebnisse hängen von der Initialisierung ab. SVD liefert für dieselben Eingaben stets dieselbe Ausgabe.
Wenn deine Matrix für die vollständige SVD zu groß ist, du aber trotzdem Singulärwerte brauchst, lohnt sich Randomized SVD. Dabei werden Zufallsprojektionen genutzt, um die größten k Singulärwerte und -vektoren zu approximieren, ohne die vollständige Zerlegung zu berechnen. Bibliotheken wie scikit-learn (TruncatedSVD) und Facebooks fbpca implementieren diesen Ansatz und skalieren gut auf Matrizen mit Millionen Zeilen.
Die folgende Tabelle fasst zusammen, wann welche Methode passt.
Alternativen zur SVD
Ein paar typische Stolpersteine verwirren viele angehende Data Scientists.
Erstens: Singulärwerte falsch lesen. Ein großer Singulärwert bedeutet, dass die Komponente viel Varianz in den Daten erklärt – nicht, dass sie inhaltlich „wichtig“ ist. In einer Nutzungsbewertungsmatrix kann der dominierende Singulärwert z. B. abbilden, dass die meisten Leute populäre Filme bewerten – ohne eine echte Präferenzstruktur zu zeigen. Interpretiere Singulärwerte immer im Kontext deiner Daten, nicht nur nach ihrer Größe.
Zweitens: SVD einsetzen, wenn es nicht nötig ist. Bei kleinen Datensätzen (einige Hundert Zeilen, wenige Spalten) bringt SVD unnötige Komplexität. Einfache Methoden wie Korrelationsanalysen oder grundlegende Feature-Selektion erledigen die Aufgabe schneller und mit weniger Code. SVD ist ideal bei hochdimensionalen Daten mit redundanter Struktur – trifft das nicht zu, greife zu einfacheren Methoden.
SVD zerlegt jede Matrix in drei Komponenten, die ihre Struktur sichtbar machen. Die Singulärwerte zeigen, welche Teile der Daten am meisten zählen, und die linken sowie rechten Singulärvektoren offenbaren die Muster auf Zeilen- und Spaltenebene dahinter.
Diese Zerlegung steckt hinter vielen Tools, die du täglich nutzt. Empfehlungssysteme sagen damit fehlende Bewertungen voraus. Die Bildkompression reduziert Dateigrößen bei erhaltener visueller Qualität. Die Mathematik dahinter ist fast identisch – auch wenn die Anwendungsdomänen völlig verschieden sind.
Aber SVD ist nicht immer das richtige Werkzeug. Bei großen Matrizen ist sie rechenintensiv und kann Signal und Rauschen vermischen, wenn sich die Singulärwerte nicht gut trennen. Und für kleine Datensätze ist sie überdimensioniert. Alternativen wie QR-Zerlegung, Eigendecomposition und NMF sind je nach Fall besser geeignet.
Der Schlüssel ist zu wissen, wann du SVD einsetzen solltest – und wann etwas Einfacheres besser ist. Und um dieses Know-how aufzubauen, melde dich zu unserem Machine Learning Scientist in Python track an und mach dich 2026 jobready.
Lerne mit DataCamp
Kurs
Kurs
Kurs