courses
SQL에서의 데이터 조작
4
324.3K
관계형 데이터베이스에서는 행들이 서로 의존적인 경우가 많아, 복잡한 질문에 답하려면 현재 처리 중인 테이블을 다시 참조해야 하는 경우가 자주 있습니다.
이러한 테이블을 질의하기 위해 SQL은 상관 서브쿼리를 제공합니다. 상관 서브쿼리는 내부 쿼리가 외부 쿼리의 값에 의존하는 특정 관계를 정의합니다. 일반적인 서브쿼리가 한 번 실행되어 종료되는 것과 달리, 상관 서브쿼리는 동적으로 동작하여 메인 쿼리가 평가하는 각 행마다 반복 실행됩니다.
이 튜토리얼에서는 SQL에서 상관 서브쿼리가 어떻게 동작하는지, 성능 측면에서의 고려 사항, 그리고 JOIN이나 윈도 함수와 비교했을 때 어떤 상황에서 적합한지 설명합니다. SQL이 처음이라면 먼저 Introduction to SQL 과정을, 어느 정도 경험이 있다면 Intermediate SQL 과정을 권장합니다.
상관 서브쿼리는 실행을 위해 외부 쿼리의 값에 의존하는 유형의 서브쿼리입니다.
한 번 실행되어 고정된 결과를 반환하는 대신, 외부 쿼리가 처리하는 각 행마다 서브쿼리가 한 번씩 평가됩니다. 이는 내부 쿼리가 외부 쿼리의 열을 참조하여 두 쿼리 간에 직접적인 연결이 생기기 때문입니다.
반면 비상관 서브쿼리는 외부 쿼리와 독립적으로 실행됩니다. 한 번 실행되어 결과 집합이나 값을 반환하고, 외부 쿼리는 각 행마다 서브쿼리를 재실행하지 않고 그 결과를 사용합니다.
일반적인 SQL 상관 서브쿼리는 다음과 같은 흐름으로 수행됩니다.
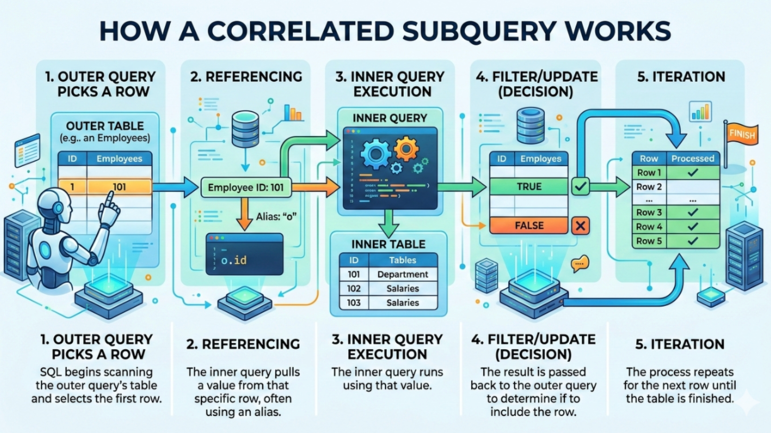
상관 서브쿼리의 동작 방식. 이미지 출처: Gemini.
지금까지는 개념적 설명이었습니다. 학습에는 예제를 직접 따라 해보는 것이 가장 좋습니다.
직원 급여와 부서 ID를 가진 employees 테이블이 있다고 가정해 보겠습니다. 각 직원이 소속 부서의 평균 급여보다 많이 받는 직원을 찾고자 합니다.
아래 쿼리를 사용할 수 있으며, 여기서:
외부 쿼리는 employees 테이블에서 직원을 선택합니다.
서브쿼리는 같은 부서의 평균 급여를 계산합니다.
e2.department_id = e.department_id 조건은 외부 쿼리의 별칭 e를 참조합니다.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);EXISTS() 연산자를 상관 서브쿼리와 함께 사용하여 다른 테이블에 관련 레코드가 존재하는지 확인할 수도 있습니다.
예를 들어 customers와 orders 테이블이 있다고 합시다. 최소 한 번이라도 주문을 한 고객을 나열하려고 합니다. 아래 쿼리를 사용할 수 있으며, 여기서:
customers 테이블의 행을 외부 쿼리가 스캔합니다.
해당 고객에 대해 최소 한 건의 주문이 있는지 서브쿼리가 확인합니다.
o.customer_id = c.customer_id 조건이 서브쿼리를 외부 쿼리와 연결합니다.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);위 쿼리에서 SQL은 orders 테이블에 일치하는 행이 존재하는지 확인합니다. 존재하면 EXISTS() 연산자는 true를 반환하고, 해당 고객이 결과에 포함됩니다.
앞서 살펴본 것처럼 SQL의 서브쿼리는 비상관 서브쿼리와 상관 서브쿼리로 나뉩니다. 핵심 차이는 내부 쿼리가 외부 쿼리에 의존하는지 여부입니다.
비상관 서브쿼리는 데이터베이스가 한 번 실행한 뒤, 그 결과를 외부 쿼리에서 사용합니다.
예를 들어, 아래 쿼리는 전체 평균 급여보다 많이 받는 직원을 찾습니다.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);위 쿼리에서 서브쿼리는 전체 테이블의 평균 급여를 계산하며, 한 번만 실행됩니다. 이후 외부 쿼리는 각 직원의 급여를 그 단일 값과 비교합니다.
비상관 서브쿼리는 한 번만 실행되므로, 결과를 재사용할 수 있을 때 일반적으로 더 빠릅니다. 전체 평균이나 합계처럼 전역 비교에 적합합니다.
반면 상관 서브쿼리는 큰 테이블에서 느릴 수 있습니다. 부서 단위 비교나 존재 여부 확인처럼 각 행에 상대적인 조건을 평가해야 하는 경우 유용합니다.
그룹화, 집계, 테이블 조인에 대해 더 배우려면 Introduction to SQL Server 과정을 권장합니다.
많은 상관 서브쿼리는 JOIN으로 다시 작성할 수 있습니다. 관계형 데이터베이스에서는 JOIN이 행 단위가 아닌 집합 단위로 관계를 처리할 수 있어 성능이 더 좋은 경우가 많습니다.
아래는 상관 서브쿼리를 사용한 예시입니다. 이 쿼리는 해당 부서 평균보다 급여를 더 많이 받는 직원을 나열합니다.
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);동일한 결과를 내기 위해 JOIN 절을 사용해 쿼리를 다시 작성할 수 있습니다.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department average아래 표는 SQL에서 상관 서브쿼리와 JOIN의 차이를 요약합니다.
|
항목 |
상관 서브쿼리 |
JOIN |
|
가독성 |
|
파생 테이블 또는 CTE가 필요할 수 있어 다소 복잡할 수 있습니다. |
|
논리 표현 |
조건을 자연스럽게 표현합니다. 예: “부서 평균보다 급여가 높다”. |
먼저 집계 값을 계산한 다음 메인 테이블과 다시 조인해야 합니다. |
|
실행 특성 |
외부 쿼리의 각 행마다 서브쿼리가 실행될 수 있습니다. |
집계 결과는 보통 한 번 계산되어 재사용됩니다. |
|
성능 |
반복 실행으로 인해 대규모 데이터셋에서는 느려질 수 있습니다. |
대용량 테이블에서 대체로 더 효율적입니다. |
|
주요 사용 사례 |
행별 조건 확인, |
리포팅 쿼리, 집계, 성능 민감한 워크로드. |
SQL의 다양한 조인 유형과 데이터베이스의 관련 테이블을 다루는 방법을 배우려면 Joining Data in SQL 과정을 권장합니다.
현대 SQL에서는 윈도 함수인 AVG()와 OVER (PARTITION BY)를 사용해 한 번의 스캔으로 행별 집계를 계산할 수 있습니다.
예를 들어 아래 쿼리는 각 부서 평균 급여보다 더 많이 받는 직원을 반환합니다. 서브쿼리 내부에서 OVER()를 사용해 집계를 윈도 함수로 변환하고, PARTITION BY department_id로 테이블을 부서별 파티션으로 나눕니다.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;그러나 테이블 간 관계를 테스트하기 위해 EXISTS()나 NOT EXISTS()를 사용하려는 경우에는 상관 서브쿼리가 여전히 유용합니다. 또한 윈도 함수를 사용할 수 없는 데이터베이스나 환경에서는 상관 서브쿼리를 사용할 수 있습니다.
상관 서브쿼리는 강력하지만, 성능 문제가 발생하는 경우가 자주 있습니다.
외부 쿼리의 각 행마다 한 번씩 실행되므로, 내부 데이터를 여러 번 재스캔해 큰 테이블에서는 쿼리가 느려질 수 있습니다. 외부 테이블에 100,000개의 행이 있다면 데이터베이스는 100,000개의 하위 작업을 수행합니다.
적절히 최적화하지 않으면, 상관 쿼리는 CPU 사용량 증가와 대기 시간 증가로 이어질 수 있습니다. 특히 내부 쿼리가 복잡한 연산을 수행하거나 큰 테이블을 스캔하는 경우에 그렇습니다.
상관에 사용되는 열에 인덱스를 생성하면, 데이터베이스가 서브쿼리에서 관련 행을 전체 내부 테이블을 매번 스캔하지 않고도 거의 즉시 찾을 수 있습니다.
최신 데이터베이스는 종종 내부적으로 상관 서브쿼리를 최적화합니다. 쿼리 플래너가 쿼리를 JOIN이나 캐시된 집계 같은 더 효율적인 형태로 변환해 쿼리 시간을 크게 줄일 수 있습니다.
다음과 같은 경우 상관 서브쿼리를 사용할 수 있습니다.
행별 집계에 기반한 필터링: 각 행에 상대적으로 값을 비교해야 할 때 사용합니다. 예: 부서 평균보다 더 많이 버는 직원.
EXISTS()로 관련 데이터 확인: 상관 서브쿼리를 EXISTS()와 함께 사용해 관련 행의 존재 여부를 테스트할 수 있습니다.
복잡한 중첩 논리 표현: 긴 JOIN 체인보다 상관 서브쿼리가 조건을 더 읽기 쉽게 표현하는 데 도움이 될 수 있습니다.
다만 다음과 같은 경우에는 상관 서브쿼리 사용을 피하십시오.
간단한 JOIN으로 충분할 때: LEFT JOIN이나 INNER JOIN으로 동일한 결과를 얻을 수 있다면, 항상 그쪽이 더 빠릅니다.
빅데이터를 다룰 때: 상관 조건이 인덱스 없는 대형 테이블을 참조하면, 반복 평가로 인해 쿼리가 크게 느려질 수 있습니다.
다음은 상관 서브쿼리를 사용할 때 자주 발생하는 문제와 해결 방법입니다.
상관 서브쿼리를 언제 어떻게 사용하고, 언제 다른 기법으로 대체할지 아는 것은 명료하고 효율적인 SQL 쿼리를 작성하는 데 중요한 역량입니다.
다음 단계로, 데이터 분석을 위한 SQL 활용 역량을 증명할 수 있는 SQL Associate Certification 취득을 권장합니다. 또한 Database Design 과정에서는 데이터베이스를 설계하고 관리하며, 필요에 맞는 DBMS를 선택하는 법을 배울 수 있습니다.
DataCamp로 SQL 배우기
courses
courses
courses