course
Data Manipulation in SQL
4 godz.
324.2K
W relacyjnych bazach danych wiersze są często współzależne, a odpowiedź na złożone pytanie wymaga, by zapytanie odwołało się ponownie do tabeli, którą właśnie przetwarza.
Aby odpytywać takie tabele, SQL umożliwia stosowanie zapytań skorelowanych, które definiują konkretną relację, w której zapytanie wewnętrzne zależy od wartości z zapytania zewnętrznego. Podczas gdy standardowe podzapytanie uruchamia się raz i kończy, zapytanie skorelowane jest dynamiczne – wykonuje się wielokrotnie dla każdego wiersza ocenianego przez zapytanie główne.
W tym poradniku wyjaśnię, jak działa zapytanie skorelowane w SQL, omówię kwestie wydajności oraz to, kiedy jest właściwym wyborem w porównaniu z JOIN-ami i funkcjami okienkowymi. Jeśli dopiero zaczyna Pan/Pani pracę z SQL, proszę zacząć od naszego kursu Wprowadzenie do SQL, a jeśli ma Pan/Pani pewne doświadczenie – kursu SQL średnio zaawansowany.
Zapytanie skorelowane to rodzaj podzapytania, które do działania zależy od wartości z zapytania zewnętrznego.
Zamiast wykonać się raz i zwrócić stały wynik, podzapytanie jest oceniane dla każdego wiersza przetwarzanego przez zapytanie zewnętrzne. Dzieje się tak, ponieważ zapytanie wewnętrzne odwołuje się do kolumny z zapytania zewnętrznego, tworząc bezpośrednie powiązanie między tymi dwoma zapytaniami.
Dla porównania, podzapytanie nieskorelowane działa niezależnie od zapytania zewnętrznego. Wykonuje się raz, zwraca zbiór wyników lub wartość, a zapytanie zewnętrzne korzysta z tego wyniku bez ponownego uruchamiania podzapytania dla każdego wiersza.
Typowy przebieg zapytania skorelowanego w SQL wygląda następująco:
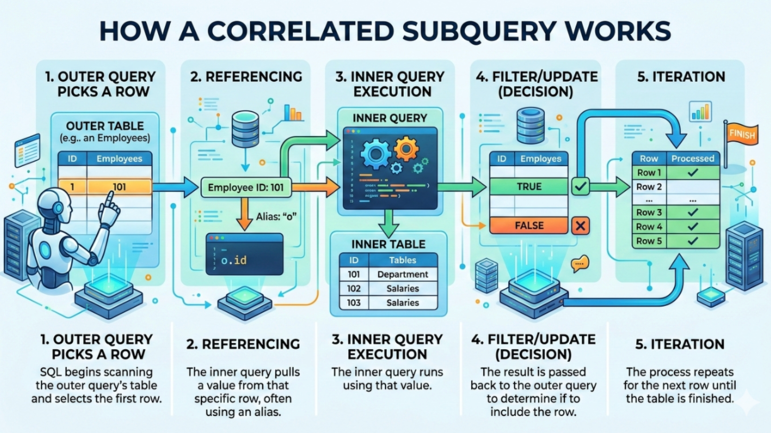
Jak działa zapytanie skorelowane. Ilustracja: Gemini.
Jak dotąd mówiliśmy koncepcyjnie. Najlepiej uczyć się na przykładach.
Załóżmy, że ma Pan/Pani tabelę employees z wynagrodzeniami pracowników i identyfikatorami działów. Chce Pan/Pani znaleźć pracowników, którzy zarabiają więcej niż średnia w ich dziale.
Użyje Pan/Pani poniższego zapytania, w którym:
Zapytanie zewnętrzne wybiera pracowników z tabeli employees.
Podzapytanie oblicza średnie wynagrodzenie dla tego samego działu.
Warunek e2.department_id = e.department_id odwołuje się do aliasu e z zapytania zewnętrznego.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);Można również użyć operatora EXISTS() z zapytaniem skorelowanym, aby sprawdzić, czy w innej tabeli istnieją powiązane rekordy.
Załóżmy, że ma Pan/Pani rekordy w tabelach customers i orders. Chce Pan/Pani wyświetlić klientów, którzy złożyli co najmniej jedno zamówienie. Użyje Pan/Pani poniższego zapytania, w którym:
Zapytanie zewnętrzne skanuje wiersze w tabeli customers.
Podzapytanie sprawdza, czy dla danego klienta istnieje przynajmniej jedno zamówienie.
Warunek o.customer_id = c.customer_id łączy podzapytanie z zapytaniem zewnętrznym.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);W powyższym zapytaniu SQL sprawdza, czy w tabeli orders istnieje pasujący wiersz. Jeśli tak, operator EXISTS() zwraca wartość true i klient jest uwzględniany w wyniku.
Jak już wspomnieliśmy, podzapytania w SQL dzielą się na nieskorelowane i skorelowane. Kluczowa różnica polega na tym, czy zapytanie wewnętrzne zależy od zapytania zewnętrznego.
W przypadku podzapytania nieskorelowanego baza danych wykonuje je raz, a następnie wykorzystuje wynik w zapytaniu zewnętrznym.
Na przykład poniższe zapytanie wyszukuje pracowników, którzy zarabiają więcej niż ogólna średnia płac.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);W powyższym zapytaniu podzapytanie oblicza średnie wynagrodzenie dla całej tabeli i uruchamiane jest jednokrotnie. Zapytanie zewnętrzne porównuje następnie wynagrodzenie każdego pracownika z tą jedną wartością.
Ponieważ podzapytania nieskorelowane uruchamiają się raz, zwykle są szybsze, gdy wynik można ponownie wykorzystać. Najlepiej sprawdzają się przy porównaniach globalnych, takich jak ogólne średnie i sumy.
Z kolei zapytania skorelowane mogą być wolniejsze na dużych tabelach. Są przydatne, gdy warunki muszą być oceniane względem każdego wiersza, np. porównań na poziomie działu lub sprawdzania istnienia rekordów.
Polecam nasz kurs Wprowadzenie do SQL Server, aby dowiedzieć się więcej o grupowaniu, agregacji danych i łączeniu tabel.
Wiele zapytań skorelowanych można przepisać przy użyciu JOIN-ów. W relacyjnych bazach danych JOIN-y zwykle działają szybciej, ponieważ baza może przetwarzać relacje zestawami, a nie wiersz po wierszu.
Proszę rozważyć poniższe zapytanie z użyciem podzapytania skorelowanego. Zwraca ono pracowników, którzy zarabiają powyżej średniej w swoim dziale.
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);To zapytanie można przepisać za pomocą klauzuli JOIN, aby uzyskać te same wyniki.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department averagePoniższa tabela podsumowuje różnice między zapytaniami skorelowanymi a JOIN w SQL.
|
Cecha |
Zapytanie skorelowane |
JOIN |
|
Czytelność |
Często łatwiejsze do czytania, ponieważ logika jest wyrażona bezpośrednio w klauzuli |
Może być nieco bardziej złożone, ponieważ może wymagać tabel pochodnych lub CTE. |
|
Wyrażenie logiki |
Naturalnie wyraża warunki. Na przykład „wynagrodzenie większe niż średnia w dziale”. |
Wymaga najpierw obliczenia wartości zagregowanych, a następnie dołączenia ich z powrotem do tabeli głównej. |
|
Zachowanie wykonania |
Podzapytanie może wykonywać się raz dla każdego wiersza w zapytaniu zewnętrznym. |
Wyniki agregacji są zwykle obliczane raz i ponownie wykorzystywane. |
|
Wydajność |
Może być wolniejsze na dużych zbiorach danych ze względu na powtarzane wykonania. |
Zazwyczaj bardziej wydajne dla dużych tabel. |
|
Typowe zastosowania |
Sprawdzanie warunków specyficznych dla wiersza, filtrowanie z |
Zapytania raportowe, agregacje i obciążenia wrażliwe na wydajność. |
Polecam kurs Łączenie danych w SQL, aby poznać różne typy JOIN-ów w SQL i nauczyć się pracy z powiązanymi tabelami w bazie danych.
We współczesnym SQL funkcje okienkowe, takie jak AVG() i OVER (PARTITION BY), potrafią obliczać agregaty na wiersz w jednym skanowaniu.
Na przykład poniższe zapytanie zwraca pracowników, których wynagrodzenie jest wyższe niż średnia w ich dziale. Wewnątrz podzapytania użyto OVER (), aby przekształcić agregację w funkcję okienkową, oraz PARTITION BY department_id, aby podzielić tabelę na grupy (partycje) według działu.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;Zapytania skorelowane pozostają jednak przydatne, gdy chce Pan/Pani użyć EXISTS() lub NOT EXISTS() do testowania relacji między tabelami. Można też sięgać po nie w bazach lub sytuacjach, w których funkcje okienkowe są niedostępne.
Choć zapytania skorelowane są potężne, często wiążą się z pewnymi problemami wydajnościowymi.
Ponieważ zapytanie uruchamia się raz na każdy wiersz zapytania zewnętrznego, na dużych tabelach może spowalniać działanie poprzez wielokrotne skanowanie danych wewnętrznych. Jeśli tabela zewnętrzna ma 100 000 wierszy, baza wykona 100 000 podzadań.
Bez odpowiedniej optymalizacji zapytania skorelowane mogą powodować wysokie użycie CPU i długie czasy oczekiwania, zwłaszcza gdy zapytanie wewnętrzne wykonuje złożone obliczenia lub skanuje duże tabele.
Zaindeksowanie kolumn używanych w korelacji pomoże bazie danych niemal natychmiast znajdować powiązane wiersze w podzapytaniu, zamiast za każdym razem skanować całą tabelę wewnętrzną.
Współczesne bazy często optymalizują zapytania skorelowane wewnętrznie. Planista może przekształcić zapytanie w bardziej wydajną formę, np. JOIN lub buforowaną agregację, znacząco skracając czas wykonania.
Można użyć zapytań skorelowanych, jeśli chce Pan/Pani wykonać następujące operacje:
Filtrowanie na podstawie agregatów specyficznych dla wiersza: Proszę użyć, gdy trzeba porównać wartość względnie do każdego wiersza, np. pracowników zarabiających powyżej średniej w dziale.
Sprawdzanie powiązanych danych z EXISTS(): Można także używać zapytań skorelowanych z EXISTS(), aby sprawdzać, czy istnieją powiązane wiersze.
Wyrażanie złożonej zagnieżdżonej logiki: Zapytania skorelowane mogą ułatwiać czytelne wyrażanie złożonych warunków w porównaniu z długimi łańcuchami JOIN.
Należy jednak unikać zapytań skorelowanych, gdy:
Wystarczy prosty JOIN: Jeśli ten sam wynik można uzyskać przy pomocy LEFT JOIN lub INNER JOIN, lepiej z niego skorzystać, bo będzie szybszy.
Praca na dużych danych: Jeśli korelowany warunek odwołuje się do dużych tabel bez indeksów, powtarzane ewaluacje mogą znacząco spowolnić zapytanie.
Poniżej przedstawiamy typowe problemy, na jakie można natrafić przy korzystaniu z zapytań skorelowanych, oraz sposoby ich rozwiązania:
Umiejętność rozpoznania, kiedy i jak używać zapytań skorelowanych oraz kiedy zastępować je innymi technikami, jest kluczowa dla pisania czytelnych i wydajnych zapytań SQL.
Kolejnym krokiem polecam uzyskanie certyfikacji SQL Associate, aby potwierdzić biegłość w używaniu SQL do analizy danych i wyróżnić się wśród specjalistów danych. Na koniec polecam nasz kurs Projektowanie baz danych, w którym nauczy się Pan/Pani tworzyć i zarządzać bazami oraz wybierać odpowiedni system DBMS do swoich potrzeb.
Ucz się SQL z DataCamp
course
course
course