
Curso
Manipulación de datos en SQL
4 h
324.1K
En las bases de datos relacionales, las filas suelen estar interrelacionadas y, para responder preguntas complejas, a menudo una consulta necesita mirar de nuevo a la misma tabla que está procesando.
Para consultar este tipo de tablas, SQL permite usar subconsultas correlacionadas, que definen una relación específica en la que la consulta interna depende de los valores de la consulta externa. Mientras que una subconsulta estándar se ejecuta una vez y termina, una subconsulta correlacionada es dinámica: se ejecuta repetidamente para cada una de las filas que evalúa la consulta principal.
En este tutorial, te explico cómo funciona una subconsulta correlacionada en SQL, qué implicaciones de rendimiento tiene y cuándo conviene usarla frente a los joins y las funciones de ventana. Si estás empezando con SQL, comienza con nuestro curso Introduction to SQL o con Intermediate SQL si ya tienes algo de experiencia.
Una subconsulta correlacionada es un tipo de subconsulta que depende de valores de la consulta externa para ejecutarse.
En lugar de ejecutarse una sola vez y devolver un resultado fijo, la subconsulta se evalúa una vez por cada fila procesada por la consulta externa. Esto ocurre porque la consulta interna referencia una columna de la consulta externa, creando un vínculo directo entre ambas.
En cambio, una subconsulta no correlacionada se ejecuta de forma independiente a la consulta externa. Se ejecuta una vez, devuelve un conjunto de resultados o un valor, y la consulta externa utiliza ese resultado sin volver a ejecutar la subconsulta para cada fila.
Una subconsulta correlacionada típica en SQL sigue este flujo:
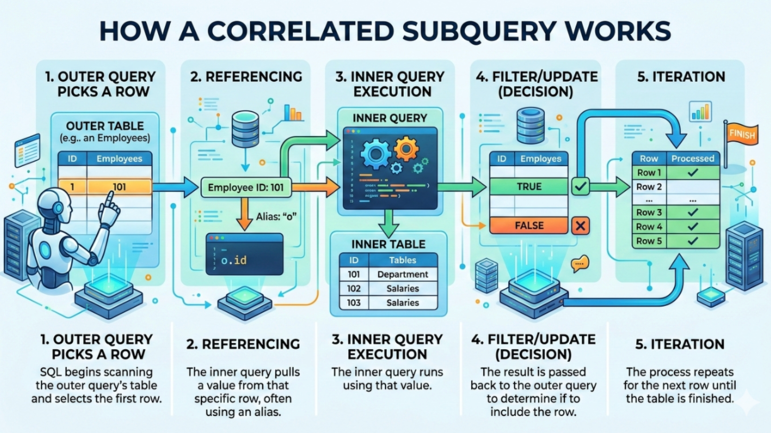
Cómo funciona una subconsulta correlacionada. Imagen de Gemini.
Hasta ahora hemos visto la parte conceptual. La mejor forma de aprender es con ejemplos.
Supón que tienes una tabla employees con los salarios y los identificadores de departamento. Quieres encontrar a quienes ganan más que el salario medio de su departamento.
Usarás la consulta siguiente, donde:
La consulta externa selecciona empleados de la tabla employees.
La subconsulta calcula el salario medio del mismo departamento.
La condición e2.department_id = e.department_id referencia el alias e de la consulta externa.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);También puedes usar el operador EXISTS() con una subconsulta correlacionada para comprobar si existen registros relacionados en otra tabla.
Imagina que tienes registros en las tablas customers y orders. Quieres listar los clientes que han hecho al menos un pedido. Usarás la consulta de abajo, donde:
La consulta externa recorre las filas de la tabla customers.
La subconsulta comprueba si existe al menos un pedido para ese cliente.
La condición o.customer_id = c.customer_id vincula la subconsulta con la consulta externa.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);En esta consulta, SQL comprueba si existe una fila coincidente en la tabla de pedidos. Si existe, el operador EXISTS() devuelve verdadero y el cliente se incluye en el resultado.
Como hemos visto, las subconsultas en SQL pueden ser no correlacionadas o correlacionadas. La diferencia clave es si la consulta interna depende o no de la externa.
En una subconsulta no correlacionada, la base de datos la ejecuta una vez y después usa el resultado en la consulta externa.
Por ejemplo, la consulta siguiente encuentra a los empleados que ganan más que el salario medio general.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Aquí, la subconsulta calcula el salario medio de toda la tabla y se ejecuta una sola vez. La consulta externa compara el salario de cada empleado con ese único valor.
Dado que las subconsultas no correlacionadas se ejecutan una vez, suelen ser más rápidas cuando el resultado se puede reutilizar. Son ideales para comparaciones globales, como medias o totales generales.
Sin embargo, las subconsultas correlacionadas pueden ser más lentas en tablas grandes. Resultan útiles cuando las condiciones deben evaluarse en relación con cada fila, como comparaciones a nivel de departamento o comprobaciones de existencia.
Te recomiendo nuestro curso Introduction to SQL Server para profundizar en agrupaciones, agregaciones de datos y joins entre tablas.
Muchas subconsultas correlacionadas pueden reescribirse usando JOIN. En bases de datos relacionales, los JOIN suelen rendir mejor porque el motor procesa las relaciones por conjuntos y no fila a fila.
Considera la consulta siguiente, que usa una subconsulta correlacionada. Devuelve los empleados que cobran por encima del salario medio de su departamento.
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);Puedes reescribirla con la cláusula JOIN para obtener el mismo resultado.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department averageLa siguiente tabla resume la diferencia entre subconsultas correlacionadas y JOIN en SQL.
|
Característica |
Subconsulta correlacionada |
JOIN |
|
Legibilidad |
A menudo más fácil de leer porque la lógica se expresa directamente en la cláusula |
Puede ser algo más compleja porque puede requerir tablas derivadas o CTE. |
|
Expresión de la lógica |
Expresa condiciones de forma natural. Por ejemplo, “salario superior a la media del departamento”. |
Requiere calcular primero los valores agregados y luego unirlos a la tabla principal. |
|
Comportamiento de ejecución |
La subconsulta puede ejecutarse una vez por cada fila de la consulta externa. |
Los resultados agregados suelen calcularse una vez y reutilizarse. |
|
Rendimiento |
Puede ser más lenta en conjuntos de datos grandes por la ejecución repetida. |
Suele ser más eficiente en tablas grandes. |
|
Casos de uso habituales |
Comprobar condiciones específicas por fila, filtrar con |
Consultas de reporting, agregaciones y cargas sensibles al rendimiento. |
Te recomiendo el curso Joining Data in SQL para aprender los distintos tipos de joins en SQL y cómo trabajar con tablas relacionadas en la base de datos.
En SQL moderno, las funciones de ventana como AVG() y OVER (PARTITION BY) pueden calcular agregados por fila en un solo escaneo.
Por ejemplo, la consulta siguiente devuelve empleados cuyo salario es superior a la media de su departamento. Dentro de la subconsulta, usa OVER () para convertir el agregado en función de ventana y PARTITION BY department_id para dividir la tabla en grupos (particiones) por departamento.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;Aun así, las subconsultas correlacionadas siguen siendo útiles cuando quieres usar EXISTS() o NOT EXISTS() para comprobar relaciones entre tablas. También puedes recurrir a ellas cuando trabajes en bases de datos o contextos donde no haya funciones de ventana disponibles.
Aunque las subconsultas correlacionadas son potentes, a menudo conllevan ciertos problemas de rendimiento.
Como la consulta se ejecuta una vez por cada fila de la consulta externa, puede ralentizarse en tablas grandes al volver a escanear los datos internos muchas veces. Si tu tabla externa tiene 100.000 filas, la base de datos realiza 100.000 subtareas.
Si no optimizas correctamente, las consultas correlacionadas pueden generar un alto uso de CPU y tiempos de espera largos, sobre todo si la consulta interna realiza cálculos complejos o escanea tablas voluminosas.
Indexar las columnas usadas en la correlación ayuda a que la base de datos encuentre casi al instante la fila relacionada en la subconsulta, en lugar de escanear la tabla interna completa cada vez.
Las bases de datos modernas suelen optimizar internamente las subconsultas correlacionadas. El planificador puede transformar la consulta en una forma más eficiente, como un JOIN o una agregación en caché, y reducir significativamente el tiempo de ejecución.
Úsala cuando quieras realizar lo siguiente:
Filtrar según agregados por fila: cuando necesites comparar un valor en relación con cada fila, por ejemplo, empleados que ganan por encima de la media de su departamento.
Comprobar datos relacionados con EXISTS(): también puedes usar subconsultas correlacionadas con EXISTS() para comprobar si existen filas relacionadas.
Expresar lógica anidada compleja: pueden ayudarte a hacer más legibles condiciones complejas frente a cadenas largas de JOIN.
Evítalas cuando:
Un JOIN simple basta: si puedes obtener el mismo resultado con un LEFT JOIN o un INNER JOIN, utilízalo: será más rápido.
Trabajas con datos masivos: si la condición correlacionada referencia tablas grandes sin índices, las evaluaciones repetidas pueden ralentizar mucho la consulta.
Estos son algunos problemas habituales y cómo solucionarlos:
Saber cuándo y cómo usar subconsultas correlacionadas, y cuándo sustituirlas por otras técnicas, es clave para escribir consultas SQL claras y eficientes.
Como siguiente paso, te recomiendo obtener nuestra SQL Associate Certification para demostrar tu dominio de SQL para análisis de datos y destacar entre otros profesionales. Para terminar, te recomiendo el curso Database Design, donde aprenderás a crear y gestionar bases de datos y a elegir el SGBD adecuado para tus necesidades.
Aprende SQL con DataCamp
Curso
Curso
Curso
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Travis Tang
Tutorial
Allan Ouko

