course
Manipularea datelor în SQL
4 oră
324.4K
În bazele de date relaționale, rândurile sunt adesea interdependente, iar pentru a răspunde la o întrebare complexă o interogare trebuie adesea să revină la tabelul pe care îl procesează în acel moment.
Pentru a interoga astfel de tabele, SQL permite folosirea subinterogărilor corelate, care definesc o relație specifică în care interogarea interioară depinde de valorile interogării exterioare. În timp ce o subinterogare standard rulează o singură dată și se încheie, o subinterogare corelată este dinamică, executându-se repetat pentru fiecare rând evaluat de interogarea principală.
În acest tutorial, voi explica modul în care funcționează o subinterogare corelată în SQL, aspectele privind performanța și când este alegerea potrivită în comparație cu join-urile și funcțiile de fereastră. Dacă sunteți la început cu SQL, începeți cu cursul nostru Introduction to SQL sau cu Intermediate SQL dacă aveți deja ceva experiență.
O subinterogare corelată este un tip de subinterogare care depinde de valorile din interogarea exterioară pentru a rula.
În loc să se execute o dată și să returneze un rezultat fix, subinterogarea este evaluată pentru fiecare rând procesat de interogarea exterioară. Acest lucru se întâmplă deoarece interogarea interioară face referire la o coloană din interogarea exterioară, creând o legătură directă între cele două interogări.
Prin comparație, o subinterogare necorelată rulează independent de interogarea exterioară. Se execută o dată, returnează un set de rezultate sau o valoare, iar interogarea exterioară folosește acel rezultat fără a relansa subinterogarea pentru fiecare rând.
O subinterogare corelată tipică în SQL are următorul flux de lucru:
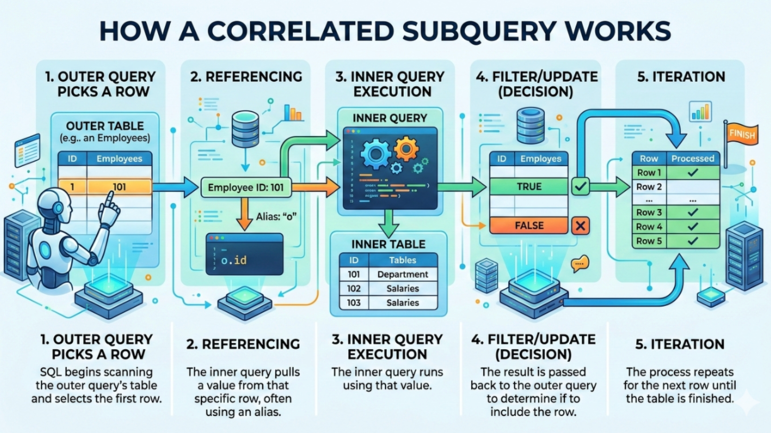
Cum funcționează o subinterogare corelată. Imagine de Gemini.
Până acum, ce am spus este conceptual. Cel mai bun mod de a învăța este prin exemple.
Să presupunem că aveți un tabel employees cu salariile angajaților și ID-urile departamentelor. Doriți să găsiți angajații care câștigă mai mult decât salariul mediu din departamentul lor.
Veți folosi interogarea de mai jos, unde:
Interogarea exterioară selectează angajații din tabelul employees.
Subinterogarea calculează salariul mediu pentru același departament.
Condiția e2.department_id = e.department_id face referire la aliasul interogării exterioare e.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);Puteți folosi și operatorul EXISTS() împreună cu o subinterogare corelată pentru a verifica dacă există în alt tabel înregistrări înrudite.
Să spunem că aveți înregistrări în tabelele customers și orders. Doriți să listați clienții care au plasat cel puțin o comandă. Veți folosi interogarea de mai jos, unde:
Interogarea exterioară scanează rândurile din tabelul customers.
Subinterogarea verifică dacă există cel puțin o comandă pentru acel client.
Condiția o.customer_id = c.customer_id leagă subinterogarea de interogarea exterioară.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);În interogarea de mai sus, SQL verifică dacă există un rând care se potrivește în tabelul orders. Dacă da, operatorul EXISTS() returnează adevărat, iar clientul este inclus în rezultat.
După cum am învățat anterior, subinterogările în SQL se împart în subinterogări necorelate sau corelate. Diferența cheie este dacă interogarea interioară depinde de interogarea exterioară.
Pentru o subinterogare necorelată, baza de date o execută o dată, apoi folosește rezultatul în interogarea exterioară.
De exemplu, interogarea de mai jos găsește angajații care câștigă mai mult decât salariul mediu general.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);În interogarea de mai sus, subinterogarea calculează salariul mediu pentru întregul tabel și rulează o singură dată. Interogarea exterioară compară apoi salariul fiecărui angajat cu acea valoare unică.
Deoarece subinterogările necorelate rulează o dată, ele sunt de obicei mai rapide când rezultatul poate fi reutilizat. Sunt cele mai potrivite pentru comparații globale, precum medii și totaluri generale.
Totuși, subinterogările corelate pot fi mai lente pe tabele mari. Devine utile când condițiile trebuie evaluate relativ la fiecare rând, precum comparații la nivel de departament sau verificări de existență.
Recomand să urmați cursul nostru Introduction to SQL Server pentru a afla mai multe despre grupare și agregarea datelor și despre îmbinarea tabelelor.
Multe subinterogări corelate pot fi rescrise folosind JOIN-uri. În bazele de date relaționale, JOIN-urile au performanțe mai bune deoarece baza de date poate procesa relațiile set-cu-set, nu rând-cu-rând.
Analizați interogarea de mai jos, care folosește o subinterogare corelată. Această interogare listează angajații plătiți peste salariul mediu din departamentul lor
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);Puteți rescrie interogarea folosind clauza JOIN pentru a obține aceleași rezultate.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department averageTabelul de mai jos rezumă diferența dintre subinterogările corelate și JOIN în SQL.
|
Caracteristică |
Subinterogare corelată |
JOIN |
|
Lizibilitate |
Adesea mai ușor de citit deoarece logica este exprimată direct în clauza |
Poate fi ușor mai complex deoarece poate necesita tabele derivate sau CTE-uri. |
|
Exprimarea logicii |
Exprimă natural condițiile. De exemplu, „salariu mai mare decât media departamentului”. |
Necesită calcularea valorilor agregate mai întâi și apoi îmbinarea lor înapoi la tabelul principal. |
|
Comportament la execuție |
Subinterogarea poate rula o dată pentru fiecare rând din interogarea exterioară. |
Rezultatele agregate sunt de obicei calculate o dată și reutilizate. |
|
Performanță |
Poate fi mai lentă pe seturi mari de date din cauza execuțiilor repetate. |
De obicei mai eficientă pentru tabele mari. |
|
Cazuri comune de utilizare |
Verificarea condițiilor specifice rândurilor, filtrarea cu |
Interogări de raportare, agregări și sarcini sensibile la performanță. |
Recomand să urmați cursul nostru Joining Data in SQL pentru a învăța diferitele tipuri de join-uri în SQL și cum să lucrați cu diverse tabele înrudite din baza de date.
În SQL modern, funcțiile de fereastră precum AVG() și OVER (PARTITION BY) pot calcula agregate per rând într-o singură scanare.
De exemplu, interogarea de mai jos returnează angajații al căror salariu este mai mare decât media salariilor din departamentul lor. În interiorul subinterogării, folosește OVER () pentru a transforma agregarea într-o funcție de fereastră și PARTITION BY department_id pentru a împărți tabelul în grupuri (partiții) după departament.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;Totuși, subinterogările corelate rămân utile când doriți să folosiți EXISTS() sau NOT EXISTS() pentru a testa relațiile dintre tabele. De asemenea, puteți folosi subinterogări corelate când lucrați în baze de date sau situații în care funcțiile de fereastră nu sunt disponibile.
Deși subinterogările corelate sunt puternice, ele vin adesea cu unele probleme de performanță.
Deoarece interogarea rulează o dată per rând al interogării exterioare, poate încetini interogările pe tabele mari prin rescănarea datelor interioare de mai multe ori. Dacă tabelul exterior are 100.000 de rânduri, baza de date efectuează 100.000 de sub-sarcini.
Dacă nu aplicați optimizarea corespunzătoare, interogările corelate pot duce la utilizare ridicată a CPU și timpi mari de așteptare, mai ales dacă interogarea interioară efectuează calcule complexe sau scanează tabele mari.
Indexarea coloanelor folosite în corelare va ajuta baza de date să găsească aproape instantaneu rândul înrudit în subinterogare, în loc să scaneze întregul tabel interior de fiecare dată.
Bazele de date moderne optimizează adesea intern subinterogările corelate. Planificatorul de interogări poate transforma interogarea într-o formă mai eficientă, cum ar fi un JOIN sau o agregare memorată în cache, reducând semnificativ timpul de execuție.
Puteți folosi subinterogări corelate dacă doriți să efectuați următoarele:
Filtrare pe baza agregatelor specifice rândului: Folosiți-o când trebuie să comparați o valoare relativ la fiecare rând, cum ar fi angajați care câștigă peste media departamentului.
Verificarea datelor înrudite cu EXISTS(): Puteți folosi subinterogări corelate cu EXISTS() pentru a testa dacă există rânduri înrudite.
Exprimarea logicii imbricate complexe: Subinterogările corelate pot ajuta la exprimarea mai clară a condițiilor complexe decât lanțuri lungi de JOIN-uri.
Totuși, evitați să folosiți subinterogări corelate atunci când:
Funcționează un JOIN simplu: Dacă puteți obține același rezultat cu un LEFT JOIN sau INNER JOIN, folosiți-l, deoarece va fi întotdeauna mai rapid.
Lucrați cu volume mari de date: Dacă condiția corelată face referire la tabele mari fără indici, evaluările repetate pot încetini semnificativ interogarea.
Mai jos sunt câteva probleme comune pe care le puteți întâlni când folosiți subinterogări corelate și cum să le depanați:
Să învățați când și cum să folosiți subinterogările corelate și când să le înlocuiți cu alte tehnici este o abilitate importantă pentru a scrie interogări SQL clare și eficiente.
Ca pas următor, recomand să obțineți certificarea SQL Associate pentru a vă demonstra stăpânirea SQL în analiza datelor și pentru a vă evidenția în rândul profesioniștilor din domeniu. În final, recomand cursul nostru Database Design, unde veți învăța să creați și să gestionați baze de date și să alegeți SGBD-ul potrivit pentru nevoile dumneavoastră.
Învățați SQL cu DataCamp
course
course
course