
Kurs
Datenbearbeitung in SQL
4 Std.
324.1K
In relationalen Datenbanken hängen Zeilen oft voneinander ab. Um komplexe Fragen zu beantworten, muss eine Abfrage daher manchmal auf die Tabelle zurückgreifen, die sie gerade verarbeitet.
Für solche Tabellen erlaubt SQL korrelierte Unterabfragen. Sie definieren eine Beziehung, bei der die innere Abfrage von den Werten der äußeren Abfrage abhängt. Während eine normale Unterabfrage einmal ausgeführt wird und fertig ist, ist eine korrelierte Unterabfrage dynamisch und läuft für jede einzelne Zeile, die die Hauptabfrage prüft, erneut.
In diesem Tutorial erkläre ich, wie eine korrelierte Unterabfrage in SQL funktioniert, worauf du bei der Performance achten solltest und wann sie die bessere Wahl ist als JOINs und Fensterfunktionen. Wenn du neu in SQL bist, starte mit unserem Kurs Introduction to SQL oder, falls du schon Erfahrung hast, mit Intermediate SQL.
Eine korrelierte Unterabfrage ist eine Form der Unterabfrage, die zum Ausführen Werte aus der äußeren Abfrage benötigt.
Statt einmal zu laufen und ein fixes Ergebnis zu liefern, wird die Unterabfrage für jede Zeile der äußeren Abfrage ausgewertet. Das liegt daran, dass die innere Abfrage eine Spalte der äußeren Abfrage referenziert und so eine direkte Verknüpfung zwischen beiden herstellt.
Im Gegensatz dazu läuft eine nicht korrelierte Unterabfrage unabhängig von der äußeren Abfrage. Sie wird einmal ausgeführt, liefert ein Ergebnis (Menge oder Wert), und die äußere Abfrage nutzt dieses Ergebnis, ohne die Unterabfrage pro Zeile neu zu starten.
Eine typische korrelierte Unterabfrage in SQL folgt diesem Ablauf:
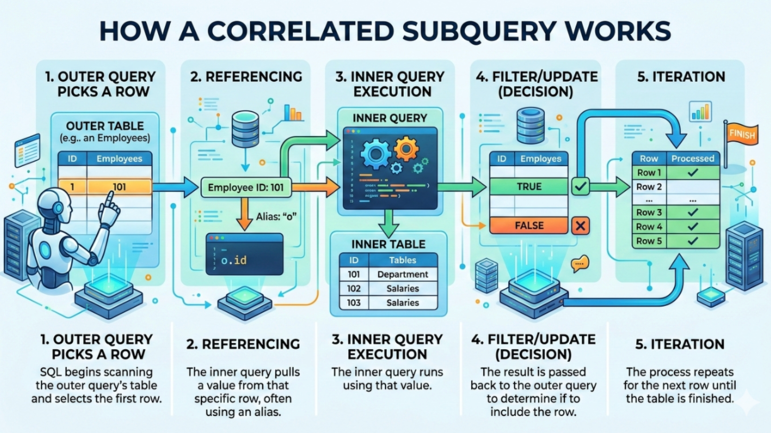
So arbeitet eine korrelierte Unterabfrage. Bild von Gemini.
Bisher war das eher konzeptionell. Am besten lernst du anhand von Beispielen.
Angenommen, du hast eine Tabelle employees mit Gehältern und Abteilungs-IDs. Du möchtest alle Mitarbeitenden finden, die mehr verdienen als der Durchschnitt ihrer Abteilung.
Dafür verwendest du die folgende Abfrage, bei der:
Die äußere Abfrage Mitarbeitende aus der Tabelle employees auswählt.
Die Unterabfrage den durchschnittlichen Abteilungslohn berechnet.
Die Bedingung e2.department_id = e.department_id den Alias e der äußeren Abfrage referenziert.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);Du kannst den Operator EXISTS() mit einer korrelierten Unterabfrage nutzen, um zu prüfen, ob zugehörige Datensätze in einer anderen Tabelle vorhanden sind.
Angenommen, es gibt Datensätze in den Tabellen customers und orders. Du willst alle Kundinnen und Kunden auflisten, die mindestens eine Bestellung aufgegeben haben. Dazu verwendest du die folgende Abfrage, bei der:
Die äußere Abfrage die Zeilen in der Tabelle customers scannt.
Die Unterabfrage prüft, ob es mindestens eine Bestellung für diese Person gibt.
Die Bedingung o.customer_id = c.customer_id die Unterabfrage mit der äußeren Abfrage verknüpft.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);In dieser Abfrage prüft SQL, ob es eine passende Zeile in der Tabelle orders gibt. Falls ja, liefert EXISTS() true und die Kundin bzw. der Kunde wird im Ergebnis aufgeführt.
Wie bereits erwähnt, unterscheidet SQL zwischen nicht korrelierten und korrelierten Unterabfragen. Der entscheidende Unterschied: Hängt die innere Abfrage von der äußeren ab oder nicht?
Bei einer nicht korrelierten Unterabfrage führt die Datenbank diese einmal aus und nutzt das Ergebnis anschließend in der äußeren Abfrage.
Zum Beispiel findet die folgende Abfrage Mitarbeitende, die mehr als den gesamten Durchschnittslohn verdienen.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Hier berechnet die Unterabfrage den Durchschnittslohn für die gesamte Tabelle und läuft genau einmal. Die äußere Abfrage vergleicht dann das Gehalt jeder Person mit diesem einen Wert.
Weil nicht korrelierte Unterabfragen nur einmal laufen, sind sie meist schneller, wenn sich das Ergebnis wiederverwenden lässt. Sie eignen sich für globale Vergleiche wie Gesamtmittelwerte und Summen.
Korrelierte Unterabfragen können auf großen Tabellen dagegen langsamer sein. Sie sind nützlich, wenn Bedingungen relativ zu jeder einzelnen Zeile bewertet werden müssen, etwa bei Abteilungsvergleichen oder Existenzprüfungen.
Ich empfehle dir unseren Kurs Introduction to SQL Server, um mehr über Gruppierung, Aggregation und das Verbinden von Tabellen zu lernen.
Viele korrelierte Unterabfragen lassen sich mit JOINs umschreiben. In relationalen Datenbanken sind JOINs oft performanter, weil die Datenbank Beziehungen satzweise statt zeilenweise verarbeiten kann.
Betrachte die folgende Abfrage mit korrelierter Unterabfrage. Sie listet Mitarbeitende, die über dem Abteilungsdurchschnitt verdienen.
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);Du kannst die Abfrage mit JOIN umschreiben und das gleiche Ergebnis erzielen.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department averageDie folgende Tabelle fasst die Unterschiede zwischen korrelierten Unterabfragen und JOINs in SQL zusammen.
|
Merkmal |
Korrelierte Unterabfrage |
JOIN |
|
Lesbarkeit |
Oft leichter zu lesen, weil die Logik direkt in der |
Mitunter etwas komplexer, da abgeleitete Tabellen oder CTEs nötig sein können. |
|
Logikausdruck |
Drückt Bedingungen natürlich aus, z. B. „Gehalt größer als Abteilungsdurchschnitt“. |
Erfordert zunächst die Berechnung von Aggregaten und anschließend das Zurückjoinen auf die Haupttabelle. |
|
Ausführungsverhalten |
Die Unterabfrage kann für jede Zeile der äußeren Abfrage einmal laufen. |
Aggregierte Ergebnisse werden typischerweise einmal berechnet und wiederverwendet. |
|
Performance |
Kann bei großen Datenmengen langsamer sein, da wiederholt ausgeführt. |
Meist effizienter bei großen Tabellen. |
|
Typische Anwendungsfälle |
Zeilenspezifische Bedingungen, Filtern mit |
Reporting-Abfragen, Aggregationen und performancekritische Workloads. |
Ich empfehle unseren Kurs Joining Data in SQL, um die verschiedenen JOIN-Typen in SQL kennenzulernen und mit verknüpften Tabellen zu arbeiten.
In modernem SQL können Fensterfunktionen wie AVG() und OVER (PARTITION BY) Aggregationen pro Zeile in einem Durchlauf berechnen.
Die folgende Abfrage gibt Mitarbeitende zurück, deren Gehalt über dem Durchschnitt ihrer Abteilung liegt. In der Unterabfrage wird OVER () verwendet, um die Aggregation zur Fensterfunktion zu machen, und PARTITION BY department_id, um die Tabelle nach Abteilungen zu partitionieren.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;Korrelierte Unterabfragen bleiben jedoch nützlich, wenn du mit EXISTS() oder NOT EXISTS() Beziehungen zwischen Tabellen prüfen willst. Außerdem sind sie hilfreich, wenn du mit Datenbanken oder in Situationen arbeitest, in denen Fensterfunktionen nicht verfügbar sind.
Korrelierte Unterabfragen sind mächtig, bringen aber oft Performance-Themen mit sich.
Weil die innere Abfrage pro Zeile der äußeren Abfrage läuft, können große Tabellen ausgebremst werden: dieselben Innendaten werden vielfach neu gescannt. Hat die äußere Tabelle 100.000 Zeilen, führt die Datenbank 100.000 Teilaufgaben aus.
Ohne passende Optimierung können korrelierte Abfragen zu hoher CPU-Last und langen Wartezeiten führen, besonders wenn die innere Abfrage komplex rechnet oder große Tabellen scannt.
Indiziere die in der Korrelation verwendeten Spalten. So findet die Datenbank die zugehörigen Zeilen in der Unterabfrage fast sofort, statt jedes Mal die gesamte Tabelle zu scannen.
Moderne Datenbanken optimieren korrelierte Unterabfragen häufig intern. Der Query Planner kann die Abfrage in eine effizientere Form transformieren, etwa einen JOIN oder eine zwischengespeicherte Aggregation, und so die Laufzeit deutlich reduzieren.
Setze korrelierte Unterabfragen ein, wenn du Folgendes brauchst:
Filtern anhand zeilenspezifischer Aggregate: Vergleiche Werte relativ zu jeder Zeile, z. B. Gehälter über dem Abteilungsdurchschnitt.
Prüfen verwandter Daten mit EXISTS(): Nutze korrelierte Unterabfragen mit EXISTS(), um zu testen, ob zugehörige Zeilen existieren.
Komplexe, verschachtelte Logik ausdrücken: Korrelierte Unterabfragen können lange JOIN-Ketten lesbarer machen.
Vermeide korrelierte Unterabfragen, wenn:
Ein einfacher JOIN ausreicht: Wenn du mit LEFT JOIN oder INNER JOIN dasselbe Ergebnis bekommst, nutze das – es ist nahezu immer schneller.
Du mit großen Datenmengen arbeitest: Wenn die Korrelation große, nicht indizierte Tabellen referenziert, können die wiederholten Auswertungen die Abfrage stark verlangsamen.
Das sind typische Stolpersteine bei korrelierten Unterabfragen – und wie du sie vermeidest:
Zu wissen, wann und wie du korrelierte Unterabfragen nutzt – und wann du sie durch andere Techniken ersetzt –, ist entscheidend für klare, effiziente SQL-Abfragen.
Als nächsten Schritt empfehle ich unsere SQL Associate Certification, um deine Kompetenz in SQL für Datenanalyse nachzuweisen und dich von anderen Datenprofis abzuheben. Außerdem lohnt sich unser Kurs Database Design: Du lernst, Datenbanken zu erstellen und zu verwalten und das passende DBMS für deine Anforderungen zu wählen.
Lerne SQL mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Mark Pedigo
Tutorial
Laiba Siddiqui
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Aditya Sharma
Tutorial
Derrick Mwiti
