
Curso
Manipulação de dados em SQL
4 h
324.3K
Em bancos de dados relacionais, as linhas costumam ser interdependentes, e responder a perguntas complexas muitas vezes exige que a consulta volte a olhar para a mesma tabela que está sendo processada.
Para consultar esse tipo de tabela, o SQL permite usar subconsultas correlacionadas, que definem uma relação específica em que a consulta interna depende dos valores da consulta externa. Enquanto uma subconsulta padrão roda uma vez e termina, uma subconsulta correlacionada é dinâmica, executando repetidamente para cada linha avaliada pela consulta principal.
Neste tutorial, vou explicar como uma subconsulta correlacionada funciona em SQL, considerações de desempenho e quando ela é a melhor escolha em comparação com JOINs e funções de janela. Se você está começando em SQL, comece pelo nosso curso Introduction to SQL, ou pelo curso Intermediate SQL se você já tem alguma experiência.
Uma subconsulta correlacionada é um tipo de subconsulta que depende de valores da consulta externa para rodar.
Em vez de executar uma vez e retornar um resultado fixo, a subconsulta é avaliada uma vez para cada linha processada pela consulta externa. Isso acontece porque a consulta interna faz referência a uma coluna da consulta externa, criando um vínculo direto entre as duas.
Em comparação, uma subconsulta não correlacionada roda de forma independente da consulta externa. Ela executa uma vez, retorna um conjunto de resultados ou um valor, e a consulta externa usa esse resultado sem reexecutar a subconsulta para cada linha.
Uma subconsulta correlacionada típica em SQL segue o fluxo abaixo:
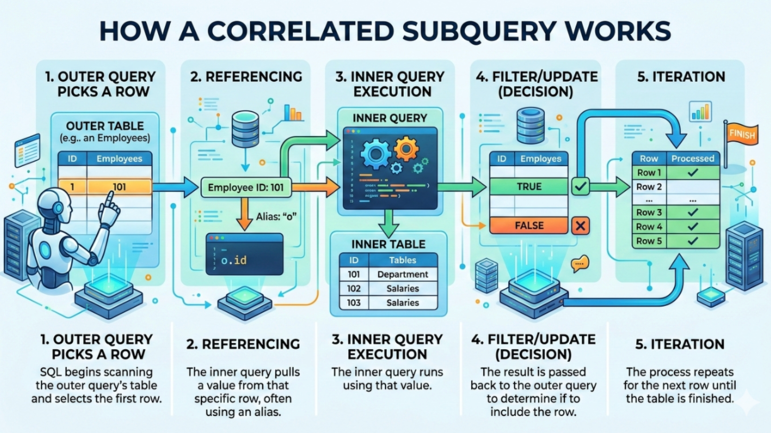
Como uma subconsulta correlacionada funciona. Imagem por Gemini.
Até aqui, falamos de forma conceitual. A melhor forma de aprender é na prática, com exemplos.
Suponha que você tenha uma tabela employees com salários e IDs de departamento. Você quer encontrar os funcionários que ganham mais do que a média salarial do seu departamento.
Use a consulta abaixo, em que:
A consulta externa seleciona funcionários da tabela employees.
A subconsulta calcula a média salarial para o mesmo departamento.
A condição e2.department_id = e.department_id faz referência ao alias e da consulta externa.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);Você também pode usar o operador EXISTS() com uma subconsulta correlacionada para verificar se existem registros relacionados em outra tabela.
Suponha que você tenha registros nas tabelas customers e orders. Você quer listar os clientes que fizeram pelo menos um pedido. Use a consulta abaixo, em que:
A consulta externa percorre as linhas da tabela customers.
A subconsulta verifica se existe ao menos um pedido para aquele cliente.
A condição o.customer_id = c.customer_id vincula a subconsulta à consulta externa.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);Na consulta acima, o SQL verifica se existe uma linha correspondente na tabela de pedidos. Se existir, o operador EXISTS() retorna verdadeiro, e o cliente é incluído no resultado.
Como vimos, as subconsultas em SQL podem ser não correlacionadas ou correlacionadas. A principal diferença é se a consulta interna depende da consulta externa.
Em uma subconsulta não correlacionada, o banco de dados a executa uma única vez e depois usa o resultado na consulta externa.
Por exemplo, a consulta abaixo encontra funcionários que ganham mais do que a média geral de salários.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Na consulta acima, a subconsulta calcula a média salarial para a tabela inteira e roda apenas uma vez. A consulta externa então compara o salário de cada funcionário com esse único valor.
Como subconsultas não correlacionadas rodam uma vez, elas costumam ser mais rápidas quando o resultado pode ser reutilizado. São ideais para comparações globais, como médias e totais gerais.
Já subconsultas correlacionadas podem ser mais lentas em tabelas grandes. Elas se tornam úteis quando as condições precisam ser avaliadas em relação a cada linha, como comparações por departamento ou verificações de existência.
Recomendo fazer nosso curso Introduction to SQL Server para aprender mais sobre agrupamento, agregação de dados e junção de tabelas.
Muitas subconsultas correlacionadas podem ser reescritas usando JOINs. Em bancos de dados relacionais, JOINs tendem a ter melhor desempenho porque o banco processa os relacionamentos em conjuntos, e não linha a linha.
Considere a consulta abaixo, que usa uma subconsulta correlacionada. Ela lista funcionários que recebem acima da média salarial do seu departamento.
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);Você pode reescrever a consulta usando a cláusula JOIN para produzir o mesmo resultado.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department averageA tabela abaixo resume a diferença entre subconsultas correlacionadas e JOIN em SQL.
|
Recurso |
Subconsulta correlacionada |
JOIN |
|
Legibilidade |
Geralmente mais fácil de ler porque a lógica é expressa diretamente na cláusula |
Pode ser um pouco mais complexo, pois pode exigir tabelas derivadas ou CTEs. |
|
Expressão da lógica |
Expressa condições de forma natural. Por exemplo, “salário maior que a média do departamento”. |
Exige calcular valores agregados primeiro e depois juntá-los de volta à tabela principal. |
|
Comportamento de execução |
A subconsulta pode rodar uma vez para cada linha da consulta externa. |
Resultados agregados normalmente são calculados uma vez e reutilizados. |
|
Desempenho |
Pode ser mais lento em grandes volumes de dados devido à execução repetida. |
Geralmente mais eficiente para tabelas grandes. |
|
Casos de uso comuns |
Verificar condições específicas por linha, filtrar com |
Consultas de relatórios, agregações e workloads sensíveis a desempenho. |
Recomendo fazer nosso curso Joining Data in SQL para aprender os diferentes tipos de joins em SQL e como trabalhar com tabelas relacionadas no banco de dados.
No SQL moderno, funções de janela como AVG() e OVER (PARTITION BY) conseguem calcular agregações por linha em uma única varredura.
Por exemplo, a consulta abaixo retorna os funcionários cujo salário é maior que a média salarial do seu departamento. Dentro da subconsulta, ela usa OVER () para transformar a agregação em uma função de janela e PARTITION BY department_id para dividir a tabela em grupos (partições) por departamento.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;Ainda assim, subconsultas correlacionadas continuam úteis quando você quer usar EXISTS() ou NOT EXISTS() para testar relacionamentos entre tabelas. Você também pode recorrer a subconsultas correlacionadas quando estiver em bancos de dados ou situações em que funções de janela não estão disponíveis.
Embora poderosas, subconsultas correlacionadas frequentemente trazem algumas questões de desempenho.
Como a consulta roda uma vez por linha da consulta externa, isso pode desacelerar consultas em tabelas grandes ao revarrer dados internos várias vezes. Se sua tabela externa tiver 100.000 linhas, o banco executará 100.000 sub-tarefas.
Sem otimização adequada, consultas correlacionadas podem gerar alto uso de CPU e longos tempos de espera, especialmente se a consulta interna fizer cálculos complexos ou varrer grandes tabelas.
Indexar as colunas usadas na correlação ajuda o banco a encontrar a linha relacionada na subconsulta quase instantaneamente, em vez de varrer a tabela interna inteira a cada execução.
Bancos modernos costumam otimizar subconsultas correlacionadas internamente. O planejador pode transformar a consulta em uma forma mais eficiente, como um JOIN ou uma agregação em cache, reduzindo bastante o tempo de execução.
Use subconsultas correlacionadas quando quiser realizar o seguinte:
Filtrar com base em agregações por linha: use quando precisar comparar um valor relativo a cada linha, como funcionários que ganham acima da média do seu departamento.
Checar dados relacionados com EXISTS(): você também pode usar subconsultas correlacionadas com EXISTS() para verificar se existem linhas relacionadas.
Expressar lógica aninhada complexa: subconsultas correlacionadas podem deixar condições complexas mais fáceis de ler e escrever, em comparação com cadeias longas de JOIN.
Por outro lado, evite subconsultas correlacionadas quando:
Um JOIN simples resolve: se você consegue o mesmo resultado com LEFT JOIN ou INNER JOIN, prefira-os, pois quase sempre serão mais rápidos.
Trabalhando com big data: se a condição correlacionada referencia tabelas grandes sem índices, as reavaliações repetidas podem deixar a consulta bem lenta.
A seguir estão alguns problemas comuns ao usar subconsultas correlacionadas e como solucioná-los:
Saber quando e como usar subconsultas correlacionadas, e quando substituí-las por outras técnicas, é uma habilidade importante para escrever consultas SQL claras e eficientes.
Como próximo passo, recomendo obter nossa SQL Associate Certification para comprovar sua proficiência em usar SQL para análise de dados e se destacar entre outros profissionais da área. Por fim, recomendo fazer nosso curso Database Design, em que você vai aprender a criar e gerenciar bancos de dados e escolher o SGBD adequado às suas necessidades.
Aprenda SQL com a DataCamp
Curso
Curso
Curso
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
Abid Ali Awan
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
DataCamp Team

