course
Data Manipulation in SQL
4 timmar
324.4K
I relationsdatabaser är rader ofta beroende av varandra, och för att besvara en komplex fråga behöver en fråga ofta titta tillbaka på tabellen den för närvarande bearbetar.
För att fråga sådana tabeller tillåter SQL korrelerade subfrågor, som definierar ett specifikt samband där den inre frågan beror på värdena i den yttre frågan. Medan en standardsubfråga körs en gång och avslutas är en korrelerad subfråga dynamisk och körs upprepade gånger för varje enskild rad som huvudfrågan utvärderar.
I den här handledningen förklarar jag hur en korrelerad subfråga fungerar i SQL, dess prestandaaspekter och när det är rätt val jämfört med joins och fönsterfunktioner. Om du är ny på SQL, börja med vår Introduction to SQL-kurs, eller Intermediate SQL om du har viss erfarenhet.
En korrelerad subfråga är en typ av subfråga som behöver värden från den yttre frågan för att köras.
I stället för att köras en gång och ge ett fast resultat utvärderas subfrågan en gång för varje rad som behandlas av den yttre frågan. Detta sker eftersom den inre frågan refererar till en kolumn från den yttre frågan, vilket skapar en direkt koppling mellan frågorna.
Som jämförelse körs en icke-korrelerad subfråga oberoende av den yttre frågan. Den körs en gång, returnerar en resultatmängd eller ett värde, och den yttre frågan använder det resultatet utan att köra subfrågan igen för varje rad.
Ett typiskt arbetsflöde för en korrelerad subfråga i SQL ser ut så här:
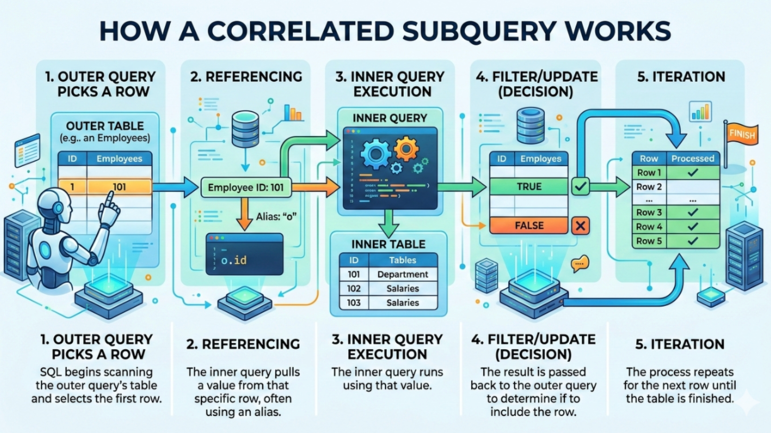
Så fungerar en korrelerad subfråga. Bild av Gemini.
Hittills har jag talat på en konceptuell nivå. Det bästa sättet att lära sig är att arbeta igenom exempel.
Anta att du har en tabell employees med löner och avdelnings-ID:n. Du vill hitta anställda som tjänar mer än genomsnittslönen i sin avdelning.
Du använder frågan nedan, där:
Den yttre frågan väljer anställda från tabellen employees.
Subfrågan beräknar genomsnittslönen för samma avdelning.
Villkoret e2.department_id = e.department_id refererar till aliaset e i den yttre frågan.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);Du kan också använda operatorn EXISTS() med en korrelerad subfråga för att kontrollera om relaterade poster finns i en annan tabell.
Anta att du har poster i tabellerna customers och orders. Du vill lista kunder som har lagt minst en beställning. Du använder frågan nedan, där:
Den yttre frågan skannar rader i tabellen customers.
Subfrågan kontrollerar om det finns minst en beställning för den kunden.
Villkoret o.customer_id = c.customer_id kopplar subfrågan till den yttre frågan.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);I frågan ovan kontrollerar SQL om en matchande rad finns i tabellen orders. Om den gör det returnerar operatorn EXISTS() true, och kunden tas med i resultatet.
Som vi sett tidigare delas subfrågor i SQL in i antingen icke-korrelerade subfrågor eller korrelerade subfrågor. Den avgörande skillnaden är om den inre frågan beror på den yttre frågan.
För en icke-korrelerad subfråga kör databasen den en gång och använder sedan resultatet i den yttre frågan.
Till exempel hittar frågan nedan anställda som tjänar mer än den övergripande genomsnittslönen.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);I frågan ovan beräknar subfrågan genomsnittslönen för hela tabellen och körs en enda gång. Den yttre frågan jämför sedan varje anställds lön med det enda värdet.
Eftersom icke-korrelerade subfrågor körs en gång är de vanligtvis snabbare när resultatet kan återanvändas. De passar bäst för globala jämförelser, till exempel totala genomsnitt och summor.
Korrelerade subfrågor kan dock vara långsammare på stora tabeller. De blir användbara när villkor måste utvärderas relativt varje rad, som jämförelser på avdelningsnivå eller existenskontroller.
Jag rekommenderar vår Introduction to SQL Server-kurs för att lära dig mer om gruppering och dataaggregering samt att göra joins mellan tabeller.
Många korrelerade subfrågor kan skrivas om med JOINs. I relationsdatabaser presterar JOINs bättre eftersom databasen kan bearbeta relationer mängdvis i stället för rad-för-rad.
Betrakta frågan nedan, som använder en korrelerad subfråga. Den här frågan listar anställda som får högre lön än genomsnittet inom sin avdelning
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);Du kan skriva om frågan med klausulen JOIN för att få samma resultat.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department averageTabellen nedan sammanfattar skillnaden mellan korrelerade subfrågor och JOIN i SQL.
|
Funktion |
Korrelerad subfråga |
JOIN |
|
Läsbarhet |
Ofta lättare att läsa eftersom logiken uttrycks direkt i |
Kan vara något mer komplext eftersom det kan kräva härledda tabeller eller CTE:er. |
|
Logikuttryck |
Uttrycker villkor naturligt. Till exempel ”lön högre än avdelningssnitt”. |
Kräver att aggregerade värden först beräknas och sedan joinas tillbaka till huvudtabellen. |
|
Körningsbeteende |
Subfrågan kan köras en gång per rad i den yttre frågan. |
Aggregerade resultat beräknas vanligtvis en gång och återanvänds. |
|
Prestanda |
Kan vara långsammare på stora datamängder på grund av upprepad körning. |
Vanligtvis mer effektivt för stora tabeller. |
|
Vanliga användningsfall |
Kontroll av rad-specifika villkor, filtrering med |
Rapportfrågor, aggregationer och prestandakritiska arbetslaster. |
Jag rekommender att ta vår Joining Data in SQL-kurs för att lära dig de olika typerna av joins i SQL och hur du arbetar med olika relaterade tabeller i databasen.
I modern SQL kan fönsterfunktioner som AVG() och OVER (PARTITION BY) beräkna aggregationer per rad i en enda genomskanning.
Till exempel returnerar frågan nedan anställda vars lön är högre än genomsnittslönen i deras avdelning. Inuti subfrågan används OVER () för att göra om aggregatet till en fönsterfunktion och PARTITION BY department_id för att dela upp tabellen i grupper (partitioner) per avdelning.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;Korrelerade subfrågor är dock fortsatt användbara när du vill använda EXISTS() eller NOT EXISTS() för att testa relationer mellan tabeller. Du kan också använda korrelerade subfrågor när du arbetar i databaser eller situationer där fönsterfunktioner inte är tillgängliga.
Även om korrelerade subfrågor är kraftfulla medför de ofta vissa prestandaproblem.
Eftersom frågan körs en gång per rad i den yttre frågan kan den sakta ner frågor på stora tabeller genom att skanna om inre data flera gånger. Om din yttre tabell har 100 000 rader utför databasen 100 000 deluppgifter.
Om du inte optimerar korrekt kan korrelerade frågor leda till hög CPU-användning och långa väntetider, särskilt om den inre frågan utför komplex matematik eller skannar stora tabeller.
Att indexera de kolumner som används i korrelationen hjälper databasen att hitta den relaterade raden i subfrågan nästan omedelbart, i stället för att skanna hela den inre tabellen varje gång.
Moderna databaser optimerar ofta korrelerade subfrågor internt. Frågeplaneraren kan transformera frågan till en mer effektiv form, såsom en JOIN eller en cachad aggregering, och kraftigt minska körtiden.
Du kan använda korrelerade subfrågor om du vill göra följande:
Filtrera baserat på rad-specifika aggregationer: Använd den när du behöver jämföra ett värde relativt varje rad, till exempel anställda som tjänar över avdelningssnittet.
Kontrollera relaterade data med EXISTS(): Du kan också använda korrelerade subfrågor med EXISTS() för att testa om relaterade rader finns.
Uttrycka komplex nästlad logik: Korrelerade subfrågor kan göra komplexa villkor lättare att läsa och uttrycka jämfört med långa kedjor av JOIN.
Undvik dock att använda korrelerade subfrågor när:
En enkel JOIN fungerar: Om du kan få samma resultat med en LEFT JOIN eller INNER JOIN, använd det, eftersom det nästan alltid är snabbare.
Du arbetar med stora datamängder: Om det korrelerade villkoret refererar till stora tabeller utan index kan de upprepade utvärderingarna göra frågan avsevärt långsammare.
Följande är några vanliga problem du kan stöta på när du använder korrelerade subfrågor, samt hur du felsöker dem:
Att lära sig när och hur man använder korrelerade subfrågor, och när man bör ersätta dem med andra tekniker, är en viktig färdighet för att skriva tydliga och effektiva SQL-frågor.
Som nästa steg rekommenderar jag att du skaffar vår SQL Associate Certification för att visa att du behärskar SQL för dataanalys och sticka ut bland andra dataprofessionella. Slutligen rekommenderar jag vår Database Design-kurs, där du lär dig skapa och hantera databaser och välja rätt DBMS för dina behov.
Lär dig SQL med DataCamp
course
course
course