
Cursus
Gegevens manipuleren in SQL
4 Hr
324.1K
In relationele databases zijn rijen vaak onderling afhankelijk, en om een complexe vraag te beantwoorden moet een query vaak terugkijken naar de tabel die hij op dat moment verwerkt.
Om zulke tabellen te bevragen, kun je in SQL gecorreleerde subquery’s gebruiken, waarbij de binnenste query afhankelijk is van de waarden uit de buitenste query. Waar een standaard subquery één keer draait en klaar is, is een gecorreleerde subquery dynamisch: hij wordt herhaaldelijk uitgevoerd voor elke rij die de hoofdquery evalueert.
In deze tutorial leg ik uit hoe een gecorreleerde subquery in SQL werkt, welke performance-overwegingen er zijn, en wanneer dit de juiste keuze is vergeleken met joins en windowfuncties. Als je nieuw bent met SQL, begin dan met onze Introduction to SQL-cursus, of de Intermediate SQL-cursus als je al wat ervaring hebt.
Een gecorreleerde subquery is een type subquery dat waarden uit de buitenste query nodig heeft om te draaien.
In plaats van één keer uit te voeren en een vaste uitkomst te geven, wordt de subquery één keer geëvalueerd voor elke rij die door de buitenste query wordt verwerkt. Dat gebeurt omdat de binnenste query naar een kolom uit de buitenste query verwijst, waardoor er een directe koppeling ontstaat tussen de twee queries.
Ter vergelijking: een niet-gecorreleerde subquery draait onafhankelijk van de buitenste query. Hij voert één keer uit, retourneert een resultaatset of waarde, en de buitenste query gebruikt dat resultaat zonder de subquery per rij opnieuw te draaien.
Een typische gecorreleerde subquery in SQL werkt als volgt:
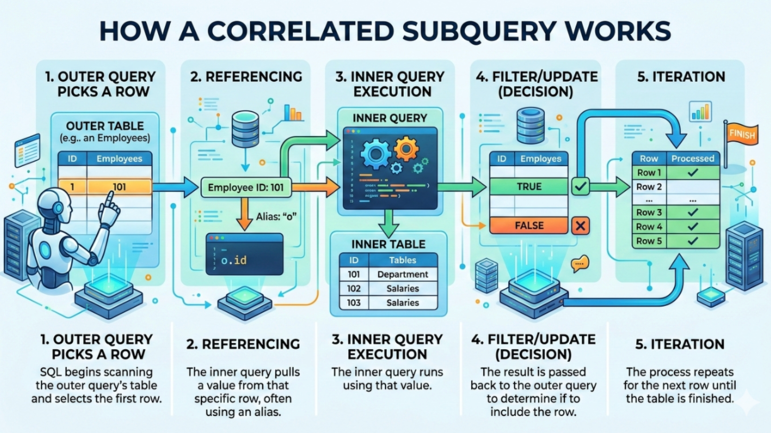
Hoe een gecorreleerde subquery werkt. Afbeelding door Gemini.
Tot nu toe was dit vooral conceptueel. De beste manier om te leren is door voorbeelden te bekijken.
Stel, je hebt een tabel employees met salarissen en afdelings-ID’s. Je wilt werknemers vinden die meer verdienen dan het gemiddelde salaris binnen hun afdeling.
Je gebruikt de onderstaande query, waarin:
De buitenste query werknemers selecteert uit de tabel employees.
De subquery het gemiddelde salaris voor dezelfde afdeling berekent.
De voorwaarde e2.department_id = e.department_id verwijst naar de alias e uit de buitenste query.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);Je kunt de operator EXISTS() ook gebruiken met een gecorreleerde subquery om te controleren of er gerelateerde records bestaan in een andere tabel.
Stel dat je records hebt in de tabellen customers en orders. Je wilt klanten tonen die minstens één bestelling hebben geplaatst. Je gebruikt de onderstaande query, waarin:
De buitenste query door de rijen in de tabel customers loopt.
De subquery controleert of er ten minste één bestelling voor die klant bestaat.
De voorwaarde o.customer_id = c.customer_id de subquery koppelt aan de buitenste query.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);In de bovenstaande query controleert SQL of er een overeenkomende rij bestaat in de tabel orders. Als dat zo is, geeft de operator EXISTS() true terug en wordt de klant in het resultaat opgenomen.
Zoals we eerder zagen, vallen subquery’s in SQL in twee categorieën: niet-gecorreleerde subquery’s en gecorreleerde subquery’s. Het belangrijkste verschil is of de binnenste query afhankelijk is van de buitenste query.
Bij een niet-gecorreleerde subquery voert de database deze één keer uit en gebruikt vervolgens het resultaat in de buitenste query.
De onderstaande query zoekt bijvoorbeeld werknemers die meer verdienen dan het algemene gemiddelde salaris.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);In de bovenstaande query berekent de subquery het gemiddelde salaris voor de hele tabel, en die draait één keer. De buitenste query vergelijkt vervolgens het salaris van elke werknemer met die ene waarde.
Omdat niet-gecorreleerde subquery’s één keer draaien, zijn ze meestal sneller wanneer het resultaat kan worden hergebruikt. Ze zijn het best voor globale vergelijkingen, zoals algemene gemiddelden en totalen.
Gecorreleerde subquery’s kunnen echter trager zijn op grote tabellen. Ze zijn nuttig wanneer voorwaarden relatief ten opzichte van elke rij moeten worden geëvalueerd, zoals vergelijkingen op afdelingsniveau of existence-checks.
Ik raad onze Introduction to SQL Server-cursus aan om meer te leren over groeperen en aggregatie, en het joinen van tabellen.
Veel gecorreleerde subquery’s kun je herschrijven met JOINs. In relationele databases presteren JOINs beter omdat de database relaties set-voor-set kan verwerken in plaats van rij-voor-rij.
Bekijk de onderstaande query met een gecorreleerde subquery. Deze query toont werknemers die boven het gemiddelde salaris binnen hun afdeling worden betaald
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);Je kunt de query herschrijven met de JOIN-clausule om hetzelfde resultaat te krijgen.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department averageDe onderstaande tabel vat het verschil samen tussen gecorreleerde subquery’s en JOIN in SQL.
|
Kenmerk |
Gecorreleerde subquery |
JOIN |
|
Leesbaarheid |
Vaak makkelijker te lezen omdat de logica direct in de |
Kan iets complexer zijn omdat er afgeleide tabellen of CTE’s nodig kunnen zijn. |
|
Logische uitdrukking |
Drukt voorwaarden natuurlijk uit. Bijvoorbeeld: “salaris hoger dan afdelingsgemiddelde”. |
Vereist eerst het berekenen van geaggregeerde waarden en die daarna terug te joinen met de hoofdtabel. |
|
Uitvoeringsgedrag |
De subquery kan één keer per rij in de buitenste query draaien. |
Geaggregeerde resultaten worden doorgaans één keer berekend en hergebruikt. |
|
Performance |
Kan trager zijn op grote datasets door herhaalde uitvoering. |
Meestal efficiënter voor grote tabellen. |
|
Veelvoorkomende use-cases |
Controleren van rij-specifieke voorwaarden, filteren met |
Rapportagequeries, aggregaties en performance-gevoelige workloads. |
Ik raad het aan om onze Joining Data in SQL-cursus te volgen om de verschillende soorten joins in SQL te leren en hoe je met gerelateerde tabellen in de database werkt.
In moderne SQL kunnen windowfuncties zoals AVG() en OVER (PARTITION BY) per rij aggregaten berekenen in één scan.
De onderstaande query retourneert bijvoorbeeld werknemers wier salaris hoger is dan het gemiddelde salaris van hun afdeling. Binnen de subquery wordt OVER () gebruikt om de aggregatie in een windowfunctie te veranderen en PARTITION BY department_id om de tabel per afdeling in groepen (partities) te verdelen.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;Gecorreleerde subquery’s blijven echter nuttig wanneer je EXISTS() of NOT EXISTS() wilt gebruiken om relaties tussen tabellen te testen. Je kunt ook gecorreleerde subquery’s gebruiken in databases of situaties waar windowfuncties niet beschikbaar zijn.
Hoewel gecorreleerde subquery’s krachtig zijn, brengen ze vaak performanceproblemen met zich mee.
Omdat de query één keer per rij van de buitenste query draait, kunnen queries op grote tabellen vertragen doordat de binnenste data meerdere keren opnieuw wordt gescand. Als je buitentabel 100.000 rijen heeft, voert de database 100.000 subtaken uit.
Zonder goede optimalisatie kunnen gecorreleerde queries leiden tot hoge CPU-belasting en lange wachttijden, vooral als de binnenste query complexe berekeningen uitvoert of grote tabellen scant.
Het indexeren van de kolommen die in de correlatie worden gebruikt, helpt de database om de gerelateerde rij in de subquery vrijwel direct te vinden, in plaats van elke keer de volledige binnentabel te scannen.
Moderne databases optimaliseren gecorreleerde subquery’s vaak intern. De query planner kan de query transformeren naar een efficiëntere vorm, zoals een JOIN of een gecachte aggregatie, en zo de querytijd aanzienlijk verlagen.
Je kunt gecorreleerde subquery’s gebruiken als je het volgende wilt doen:
Filteren op rij-specifieke aggregaten: gebruik dit wanneer je een waarde relatief ten opzichte van elke rij moet vergelijken, zoals werknemers die boven hun afdelingsgemiddelde verdienen.
Gerelateerde data controleren met EXISTS(): je kunt gecorreleerde subquery’s met EXISTS() gebruiken om te testen of gerelateerde rijen bestaan.
Complexe geneste logica uitdrukken: gecorreleerde subquery’s kunnen complexe voorwaarden leesbaarder maken dan lange ketens van JOINs.
Vermijd echter gecorreleerde subquery’s wanneer:
Een simpele JOIN volstaat: als je hetzelfde resultaat kunt krijgen met een LEFT JOIN of INNER JOIN, gebruik die dan — die zijn vrijwel altijd sneller.
Werken met big data: als de gecorreleerde voorwaarde naar grote tabellen zonder indexen verwijst, kunnen de herhaalde evaluaties de query aanzienlijk vertragen.
Dit zijn enkele veelvoorkomende problemen die je kunt tegenkomen bij gecorreleerde subquery’s, plus hoe je ze oplost:
Weten wanneer en hoe je gecorreleerde subquery’s gebruikt, en wanneer je ze vervangt door andere technieken, is een belangrijke vaardigheid om duidelijke, efficiënte SQL-queries te schrijven.
Als volgende stap raad ik onze SQL Associate Certification aan om je beheersing van SQL voor data-analyse aan te tonen en je te onderscheiden van andere dataprofessionals. Tot slot raad ik onze Database Design-cursus aan, waarin je leert databases te ontwerpen en beheren en de juiste DBMS te kiezen voor jouw behoeften.
Leer SQL met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
