Courses
SQL 中的数据处理
4小时
324.1K
在关系型数据库中,行与行之间往往相互依赖,回答复杂问题时,查询常常需要回看它正在处理的那张表。
为查询此类数据表,SQL 允许使用相关子查询,它定义了一种特定关系:内部查询依赖于外部查询的值。标准子查询运行一次即可结束,而相关子查询是动态的,会对主查询评估的每一行重复执行。
在本教程中,我将解释 SQL 中相关子查询的工作方式、性能考量,以及与 JOIN 和窗口函数相比何时应选择它。如果您是 SQL 新手,请从我们的SQL 入门课程开始;如果已有一定经验,可学习SQL 进阶课程。
相关子查询是一类子查询,其运行依赖于外部查询的值。
它不是执行一次返回固定结果,而是对外部查询处理的每一行都评估一次。这是因为内部查询引用了外部查询中的某个列,二者形成了直接关联。
相比之下,非相关子查询独立于外部查询。它执行一次,返回一个结果集或值,外部查询随后使用该结果,而不会为每一行重新运行子查询。
SQL 中典型的相关子查询一般按以下流程运行:
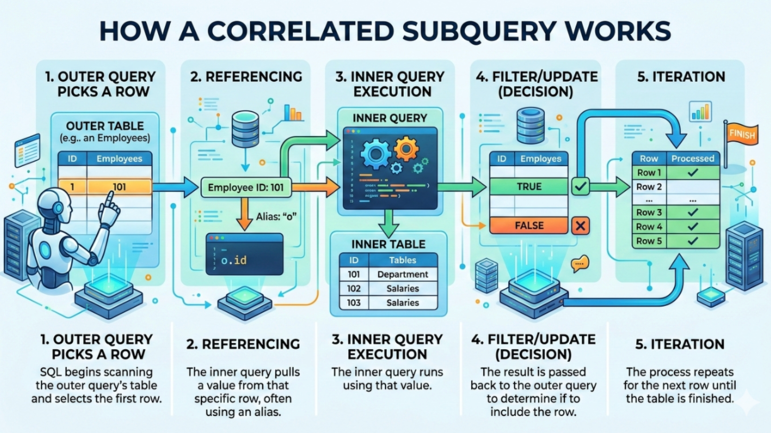
相关子查询的工作原理。图片来源:Gemini。
目前为止我们讨论的都是概念。最好的学习方式是通过示例动手实践。
假设您有一张 employees 表,包含员工薪资和部门 ID。您想找到那些薪资高于其所在部门平均值的员工。
可以使用下面的查询,其中:
外部查询从 employees 表中选择员工。
子查询计算同一部门的平均薪资。
条件 e2.department_id = e.department_id 引用了外部查询的别名 e。
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);您也可以将EXISTS() 运算符与相关子查询配合使用,以检查另一张表中是否存在相关记录。
假设您在 customers 和 orders 表中都有记录。您想列出至少下过一笔订单的客户。可使用下面的查询,其中:
外部查询扫描 customers 表中的行。
子查询检查该客户是否至少有一笔订单。
条件 o.customer_id = c.customer_id 将子查询与外部查询关联起来。
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);在上述查询中,SQL 会检查 orders 表中是否存在匹配的行。若存在,EXISTS() 运算符返回 true,该客户将包含在结果中。
如前所述,SQL 中的子查询分为非相关子查询和相关子查询。关键区别在于内部查询是否依赖于外部查询。
对于非相关子查询,数据库仅执行一次,然后在外部查询中使用其结果。
例如,下面的查询查找薪资高于全表平均薪资的员工。
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);在上述查询中,子查询计算整张表的平均薪资,只运行一次。随后外部查询将每位员工的薪资与该单个值进行比较。
由于非相关子查询只运行一次,当结果可被复用时通常更快。它们最适合用于全局比较,例如整体平均值与总数。
然而,在大型数据表上,相关子查询可能更慢。当需要针对每一行进行相对条件评估(如部门级比较或存在性检查)时,它们就很有用。
我建议学习我们的SQL Server 入门课程,以进一步了解分组与数据聚合,以及表连接。
许多相关子查询都可以改写为使用JOIN。在关系型数据库中,JOIN 的性能更好,因为数据库可以以集合为单位而非逐行处理关系。
考虑下面这个使用相关子查询的查询。该查询列出在其部门内薪资高于平均值的员工。
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);您可以使用 JOIN 子句重写该查询,以产生相同的结果。
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department average下表总结了 SQL 中相关子查询与 JOIN 的差异。
|
特性 |
相关子查询 |
JOIN |
|
可读性 |
通常更易读,因为逻辑直接表达在 |
可能略显复杂,因为可能需要派生表或 CTE。 |
|
逻辑表达 |
能自然表达条件,例如“薪资高于部门平均值”。 |
需要先计算聚合值,再将其回连到主表。 |
|
执行行为 |
子查询可能会对外部查询的每一行运行一次。 |
聚合结果通常计算一次并被复用。 |
|
性能 |
在大型数据集上可能较慢,因为会重复执行。 |
对大型表通常更高效。 |
|
常见用例 |
检查逐行条件、结合 |
报表查询、聚合以及对性能敏感的工作负载。 |
我建议学习我们的
Joining Data in SQL课程,系统学习 SQL 中的不同连接类型,以及如何在数据库中处理不同的关联表。在现代 SQL 中,窗口函数如 AVG() 和 OVER (PARTITION BY),可以在一次扫描中按行计算聚合。
例如,下面的查询返回薪资高于所在部门平均薪资的员工。在子查询中,使用 OVER () 将聚合函数变为窗口函数,并用 PARTITION BY department_id 按部门将表划分为多个分区。
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;不过,当您希望使用 EXISTS() 或 NOT EXISTS() 来测试表间关系时,相关子查询仍然非常有用。在某些数据库或场景下,如果窗口函数不可用,也可以使用相关子查询。
尽管相关子查询功能强大,但往往伴随一定的性能问题。
由于它会对外部查询的每一行运行一次,在大型数据表上会因多次重新扫描内部数据而拖慢查询速度。如果外部表有 100,000 行,数据库就需要执行 100,000 次子任务。
如果没有进行适当的优化,相关查询可能会导致高 CPU 占用与长时间等待,尤其当内部查询进行复杂计算或扫描大型数据表时。
为参与关联的列建立索引,有助于数据库几乎瞬时地在子查询中找到相关行,而不是每次都扫描整个内部表。
现代数据库常会在内部优化相关子查询。查询规划器可能将查询转换为更高效的形式,如 JOIN 或缓存的聚合,从而显著降低查询时间。
在以下场景中,您可以使用相关子查询:
基于逐行聚合进行筛选:当您需要相对每一行进行比较时使用,例如薪资高于其部门平均值的员工。
使用 EXISTS() 检查关联数据:您也可以将相关子查询与 EXISTS() 配合,测试是否存在相关行。
表达复杂的嵌套逻辑:与冗长的 JOIN 链相比,相关子查询有时能让复杂条件更易读、更易表达。
但在以下情况下应避免使用相关子查询:
简单的 JOIN 就能解决:如果使用 LEFT JOIN 或 INNER JOIN 就能得到相同结果,请优先使用,它通常更快。
处理大数据时:如果关联条件引用的是未建立索引的大表,重复评估会显著拖慢查询。
以下是使用相关子查询时常见的问题及排查思路:
了解何时以及如何使用相关子查询,以及何时用其他技术替代它,是编写清晰高效 SQL 查询的重要技能。
下一步,我建议获取我们的SQL Associate 认证,以展示您在数据分析中运用 SQL 的能力,并在数据专业人士中脱颖而出。最后,我还建议学习我们的数据库设计课程,在其中您将学习如何创建和管理数据库,并选择适合您需求的 DBMS。
与 DataCamp 一起学习 SQL
Courses
Courses
Courses