
Corso
Manipolazione dei dati in SQL
4 h
324.2K
Nei database relazionali, le righe sono spesso interdipendenti e, per rispondere a una domanda complessa, una query deve spesso tornare a consultare la tabella che sta elaborando.
Per interrogare tali tabelle, SQL consente di usare sottoquery correlate, che definiscono una relazione specifica in cui la query interna dipende dai valori della query esterna. Mentre una sottoquery standard viene eseguita una volta e termina, una sottoquery correlata è dinamica e viene eseguita ripetutamente per ogni singola riga valutata dalla query principale.
In questo tutorial ti spiegherò come funziona una sottoquery correlata in SQL, le considerazioni sulle prestazioni e quando è la scelta giusta rispetto a join e funzioni finestra. Se sei alle prime armi con SQL, inizia con il nostro corso Introduzione a SQL, oppure con il corso SQL intermedio se hai già un po’ di esperienza.
Una sottoquery correlata è un tipo di sottoquery che per essere eseguita dipende dai valori della query esterna.
Invece di eseguirsi una volta restituendo un risultato fisso, la sottoquery viene valutata una volta per ogni riga elaborata dalla query esterna. Questo accade perché la query interna fa riferimento a una colonna della query esterna, creando un collegamento diretto tra le due query.
Al contrario, una sottoquery non correlata viene eseguita in modo indipendente dalla query esterna. Si esegue una volta, restituisce un set di risultati o un valore, e la query esterna utilizza quel risultato senza rieseguire la sottoquery per ogni riga.
Una tipica sottoquery correlata in SQL segue il seguente flusso di lavoro:
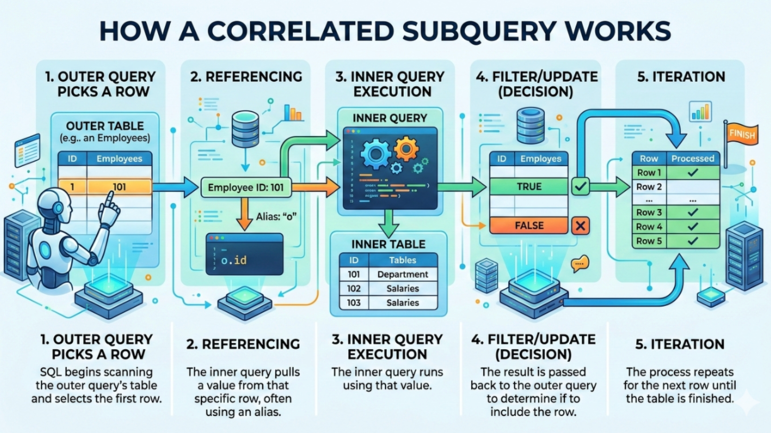
Come funziona una sottoquery correlata. Immagine di Gemini.
Finora abbiamo ragionato in modo concettuale. Il modo migliore per imparare è attraverso gli esempi.
Supponiamo di avere una tabella employees con gli stipendi dei dipendenti e gli ID dei reparti. Vuoi trovare i dipendenti che guadagnano più della media del loro reparto.
Userai la query qui sotto, in cui:
La query esterna seleziona i dipendenti dalla tabella employees.
La sottoquery calcola lo stipendio medio per lo stesso reparto.
La condizione e2.department_id = e.department_id fa riferimento all’alias e della query esterna.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);Puoi anche usare l’operatore EXISTS() con una sottoquery correlata per verificare se esistono record correlati in un’altra tabella.
Poniamo di avere record nelle tabelle customers e orders. Vuoi elencare i clienti che hanno effettuato almeno un ordine. Userai la query seguente, in cui:
La query esterna scansiona le righe nella tabella customers.
La sottoquery verifica se esiste almeno un ordine per quel cliente.
La condizione o.customer_id = c.customer_id collega la sottoquery alla query esterna.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);Nella query sopra, SQL verifica se esiste una riga corrispondente nella tabella degli ordini. Se sì, l’operatore EXISTS() restituisce true e il cliente viene incluso nel risultato.
Come abbiamo visto, le sottoquery in SQL si dividono in sottoquery non correlate e sottoquery correlate. La differenza chiave è se la query interna dipende dalla query esterna.
Per una sottoquery non correlata, il database la esegue una volta e poi usa il risultato nella query esterna.
Per esempio, la query seguente trova i dipendenti che guadagnano più della media complessiva degli stipendi.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);Nella query sopra, la sottoquery calcola lo stipendio medio per l’intera tabella ed è eseguita una sola volta. La query esterna confronta quindi lo stipendio di ogni dipendente con quel valore.
Poiché le sottoquery non correlate si eseguono una volta, di solito sono più veloci quando il risultato può essere riutilizzato. Sono ideali per confronti globali, come medie e totali complessivi.
Le sottoquery correlate, invece, possono essere più lente su tabelle di grandi dimensioni. Tornano utili quando le condizioni devono essere valutate in relazione a ciascuna riga, come confronti a livello di reparto o verifiche di esistenza.
Ti consiglio di seguire il nostro corso Introduzione a SQL Server per approfondire raggruppamenti e aggregazioni di dati, e le join tra tabelle.
Molte sottoquery correlate possono essere riscritte usando le JOIN. Nei database relazionali, le JOIN offrono prestazioni migliori perché il database può elaborare le relazioni per insiemi anziché riga per riga.
Considera la query seguente, che usa una sottoquery correlata. Questa query elenca i dipendenti che sono pagati sopra la media del loro reparto
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);Puoi riscrivere la query usando la clausola JOIN per ottenere gli stessi risultati.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department averageLa tabella seguente riassume la differenza tra sottoquery correlate e JOIN in SQL.
|
Caratteristica |
Sottoquery correlata |
JOIN |
|
Leggibilità |
Spesso più facile da leggere perché la logica è espressa direttamente nella clausola |
Può essere leggermente più complessa perché può richiedere tabelle derivate o CTE. |
|
Espressione della logica |
Esprime naturalmente le condizioni. Ad esempio, “stipendio maggiore della media del reparto”. |
Richiede di calcolare prima i valori aggregati e poi ricollegarli alla tabella principale tramite join. |
|
Comportamento di esecuzione |
La sottoquery può essere eseguita una volta per ciascuna riga della query esterna. |
I risultati aggregati sono in genere calcolati una volta e riutilizzati. |
|
Prestazioni |
Può essere più lenta su dataset di grandi dimensioni a causa delle esecuzioni ripetute. |
Di solito più efficiente per tabelle grandi. |
|
Casi d’uso comuni |
Verifica di condizioni specifiche per riga, filtraggio con |
Query di reporting, aggregazioni e carichi di lavoro sensibili alle prestazioni. |
Ti consiglio di seguire il nostro corso Joining Data in SQL per imparare i diversi tipi di join in SQL e come lavorare con tabelle relazionate nel database.
Nel SQL moderno, le funzioni finestra come AVG() e OVER (PARTITION BY) possono calcolare aggregati per riga in un’unica scansione.
Per esempio, la query sotto restituisce i dipendenti il cui stipendio è superiore alla media del loro reparto. All’interno della sottoquery, usa OVER () per trasformare l’aggregazione in una funzione finestra e PARTITION BY department_id per dividere la tabella in gruppi (partizioni) per reparto.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;Tuttavia, le sottoquery correlate restano utili quando vuoi usare EXISTS() o NOT EXISTS() per testare le relazioni tra tabelle. Puoi anche usarle quando lavori con database o in situazioni in cui le funzioni finestra non sono disponibili.
Sebbene le sottoquery correlate siano potenti, spesso presentano alcune criticità in termini di performance.
Poiché la query viene eseguita una volta per ogni riga della query esterna, su tabelle grandi può rallentare la query effettuando più volte la scansione dei dati interni. Se la tua tabella esterna ha 100.000 righe, il database esegue 100.000 sotto-attività.
Senza un’adeguata ottimizzazione, le query correlate possono comportare un elevato utilizzo della CPU e lunghi tempi di attesa, soprattutto se la query interna esegue calcoli complessi o scansiona tabelle grandi.
Indicizzare le colonne usate nella correlazione aiuterà il database a trovare quasi all’istante la riga correlata nella sottoquery, invece di scansionare ogni volta l’intera tabella interna.
I database moderni spesso ottimizzano internamente le sottoquery correlate. Il query planner può trasformare la query in una forma più efficiente, come una JOIN o un’aggregazione in cache, riducendo sensibilmente i tempi di esecuzione.
Puoi usare le sottoquery correlate quando vuoi eseguire le seguenti operazioni:
Filtrare in base ad aggregazioni specifiche per riga: usale quando devi confrontare un valore in relazione a ciascuna riga, ad esempio i dipendenti che guadagnano sopra la media del loro reparto.
Verifica di dati correlati con EXISTS(): puoi anche usare le sottoquery correlate con EXISTS() per testare l’esistenza di righe correlate.
Esprimere logiche annidate complesse: le sottoquery correlate possono aiutare a rendere più leggibili e chiare condizioni complesse rispetto a lunghe catene di JOIN.
Evita invece le sottoquery correlate quando:
Basta una semplice JOIN: se puoi ottenere lo stesso risultato con una LEFT JOIN o una INNER JOIN, usa quella soluzione: sarà sempre più veloce.
Lavori con big data: se la condizione correlata fa riferimento a tabelle grandi senza indici, le valutazioni ripetute possono rallentare notevolmente la query.
Ecco alcuni problemi comuni che potresti incontrare usando le sottoquery correlate e come risolverli:
Capire quando e come usare le sottoquery correlate, e quando sostituirle con altre tecniche, è una competenza importante per scrivere query SQL chiare ed efficienti.
Come passo successivo, ti consiglio di ottenere la nostra Certificazione SQL Associate per dimostrare la tua padronanza di SQL per l’analisi dei dati e distinguerti tra gli altri professionisti del dato. Infine, ti consiglio il nostro corso Database Design, dove imparerai a creare e gestire database e a scegliere il DBMS più adatto alle tue esigenze.
Impara SQL con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

