Course
Data Manipulation in SQL
4 ч
324.2K
В реляционных базах данных строки часто взаимосвязаны, и для ответа на сложный вопрос запросу нередко требуется обратиться к той же таблице, которую он сейчас обрабатывает.
Для работы с такими таблицами SQL позволяет использовать коррелированные подзапросы, которые определяют особую связь, при которой внутренний запрос зависит от значений внешнего запроса. В то время как обычный подзапрос выполняется один раз и завершается, коррелированный подзапрос динамический: он выполняется повторно для каждой строки, которую оценивает основной запрос.
В этом уроке я объясню, как работает коррелированный подзапрос в SQL, на что обратить внимание с точки зрения производительности и когда он — правильный выбор по сравнению с соединениями (JOIN) и оконными функциями. Если вы новичок в SQL, начните с нашего курса Introduction to SQL или курса Intermediate SQL, если у вас уже есть опыт.
Коррелированный подзапрос — это вид подзапроса, выполнение которого зависит от значений внешнего запроса.
Вместо одноразового выполнения с возвратом фиксированного результата подзапрос вычисляется для каждой строки, обрабатываемой внешним запросом. Это происходит потому, что внутренний запрос ссылается на столбец из внешнего запроса, создавая прямую связь между ними.
Для сравнения: некоррелированный подзапрос выполняется независимо от внешнего запроса. Он запускается один раз, возвращает набор результатов или значение, и внешний запрос использует этот результат без повторного запуска подзапроса для каждой строки.
Типовой коррелированный подзапрос в SQL работает так:
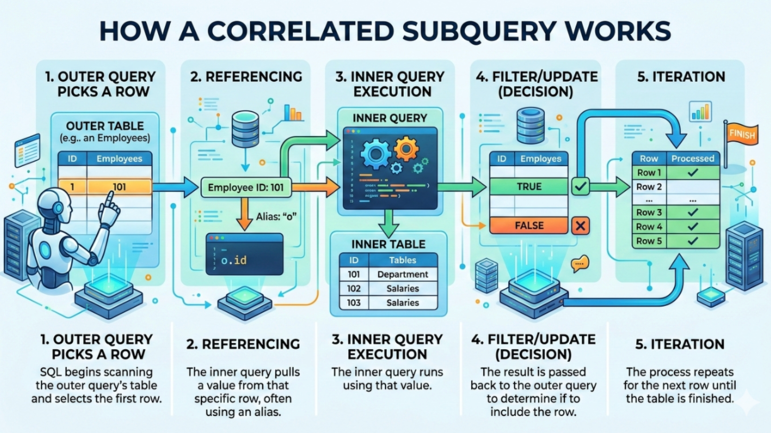
Как работает коррелированный подзапрос. Изображение: Gemini.
Пока что это было на концептуальном уровне. Лучше всего учиться на примерах.
Допустим, у вас есть таблица employees с зарплатами сотрудников и ID отделов. Вы хотите найти сотрудников, которые зарабатывают больше среднего по своему отделу.
Используйте следующий запрос, где:
Внешний запрос выбирает сотрудников из таблицы employees.
Подзапрос вычисляет среднюю зарплату для того же отдела.
Условие e2.department_id = e.department_id ссылается на псевдоним внешнего запроса e.
-- Fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary) -- Calculate the average salary
FROM employees e2
WHERE e2.department_id = e.department_id
-- Correlation: references the outer query's department_id
);Вы также можете использовать оператор EXISTS() с коррелированным подзапросом, чтобы проверить наличие связанных записей в другой таблице.
Предположим, у вас есть записи в таблицах customers и orders. Вы хотите вывести клиентов, которые сделали хотя бы один заказ. Используйте запрос ниже, где:
Внешний запрос сканирует строки таблицы customers.
Подзапрос проверяет, существует ли хотя бы один заказ для этого клиента.
Условие o.customer_id = c.customer_id связывает подзапрос с внешним запросом.
-- Fetch customers with at least one order
SELECT
c.customer_id,
c.customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
-- Correlation: references the outer query customer_id
);В этом запросе SQL проверяет, существует ли совпадающая строка в таблице заказов. Если да, оператор EXISTS() возвращает true, и клиент включается в результат.
Как мы уже видели, подзапросы в SQL делятся на некоррелированные и коррелированные. Ключевое различие — зависит ли внутренний запрос от внешнего.
Для некоррелированного подзапроса база данных выполняет его один раз, а затем использует результат во внешнем запросе.
Например, запрос ниже находит сотрудников, которые зарабатывают больше, чем средняя зарплата по всей таблице.
-- Query employees who earn more than the overall average salary
SELECT
employee_id,
employee_name,
salary
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
);В этом запросе подзапрос вычисляет среднюю зарплату по всей таблице и выполняется один раз. Затем внешний запрос сравнивает зарплату каждого сотрудника с этим значением.
Поскольку некоррелированные подзапросы выполняются один раз, они обычно быстрее, когда результат можно переиспользовать. Они лучше всего подходят для глобальных сравнений, таких как общие средние и итоги.
Однако коррелированные подзапросы могут быть медленнее на больших таблицах. Они полезны, когда условия нужно оценивать относительно каждой строки — например, для сравнений на уровне отдела или проверок существования записей.
Рекомендую пройти наш курс Introduction to SQL Server, чтобы узнать больше о группировках, агрегировании данных и соединениях таблиц.
Многие коррелированные подзапросы можно переписать, используя JOIN. В реляционных БД JOIN обычно работают быстрее, потому что база может обрабатывать связи наборами, а не построчно.
Рассмотрим запрос ниже с коррелированным подзапросом. Он выводит сотрудников, чья зарплата выше средней по их отделу.
-- Use subquery to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(e2.salary)
FROM employees e2
WHERE e2.department_id = e.department_id
);Тот же результат можно получить, переписав запрос с использованием JOIN.
-- Use JOIN to fetch employees earning more than the average salary in dept
SELECT
e.employee_id,
e.employee_name,
e.salary,
e.department_id
FROM employees e
JOIN (
SELECT
department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
-- Precompute the department average once per department
) dept_avg
ON e.department_id = dept_avg.department_id
-- Match employees with their department averages
WHERE e.salary > dept_avg.avg_salary;
-- Compare salary with the computed department averageТаблица ниже резюмирует различия между коррелированными подзапросами и JOIN в SQL.
|
Характеристика |
Коррелированный подзапрос |
JOIN |
|
Читаемость |
Часто проще читать, так как логика выражена прямо в секции |
Может быть немного сложнее, так как может потребоваться производная таблица или CTE. |
|
Выражение логики |
Естественно выражает условия. Например: «зарплата больше, чем средняя по отделу». |
Требуется сначала вычислить агрегаты, а затем присоединить их обратно к основной таблице. |
|
Поведение выполнения |
Подзапрос может выполняться по одному разу для каждой строки внешнего запроса. |
Агрегированные результаты обычно вычисляются один раз и переиспользуются. |
|
Производительность |
Может быть медленнее на больших наборах данных из‑за повторных запусков. |
Обычно эффективнее для больших таблиц. |
|
Типичные случаи использования |
Проверка построчных условий, фильтрация с |
Отчётные запросы, агрегирование и ресурсоёмкие задачи. |
Я рекомендую пройти наш курс Joining Data in SQL, чтобы изучить различные типы соединений в SQL и работу с взаимосвязанными таблицами в базе данных.
В современном SQL оконные функции, такие как AVG() и OVER (PARTITION BY), позволяют вычислять агрегаты для каждой строки за один проход.
Например, запрос ниже возвращает сотрудников, чья зарплата выше средней по их отделу. Внутри подзапроса используется OVER (), чтобы превратить агрегат в оконную функцию, и PARTITION BY department_id, чтобы разделить таблицу на группы (разделы) по отделам.
-- Use window function to get employees earning more than dept average salary
SELECT
employee_id,
employee_name,
salary,
department_id
FROM (
SELECT
employee_id,
employee_name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary
-- Window function calculates department average once per partition
FROM employees
) t
WHERE salary > dept_avg_salary;Тем не менее, коррелированные подзапросы по‑прежнему полезны, когда вы хотите использовать EXISTS() или NOT EXISTS() для проверки связей между таблицами. Также их применяют в базах данных или ситуациях, где оконные функции недоступны.
Хотя коррелированные подзапросы мощные, они часто связаны с вопросами производительности.
Поскольку запрос запускается для каждой строки внешнего запроса, на больших таблицах он может замедляться из‑за повторных сканирований внутренних данных. Если во внешней таблице 100 000 строк, база данных выполняет 100 000 подзадач.
Без должной оптимизации коррелированные запросы могут приводить к высокой загрузке CPU и долгому ожиданию, особенно если внутренний запрос выполняет сложные вычисления или сканирует большие таблицы.
Индексация столбцов, используемых в корреляции, поможет базе данных находить связанные строки в подзапросе почти мгновенно, вместо сканирования всей внутренней таблицы каждый раз.
Современные базы данных часто оптимизируют коррелированные подзапросы внутренне. Планировщик может преобразовать запрос в более эффективную форму, такую как JOIN или кешированная агрегация, и заметно сократить время выполнения.
Используйте коррелированные подзапросы, если хотите выполнить следующее:
Фильтрация на основе построчных агрегатов: используйте, когда нужно сравнивать значение относительно каждой строки, например сотрудников, зарабатывающих выше среднего по отделу.
Проверка связанных данных с EXISTS(): можно использовать коррелированные подзапросы с EXISTS(), чтобы проверить наличие связанных строк.
Выражение сложной вложенной логики: коррелированные подзапросы могут упростить чтение и выражение сложных условий по сравнению с длинными цепочками JOIN.
Однако избегайте коррелированных подзапросов, когда:
Подходит простой JOIN: если тот же результат можно получить с помощью LEFT JOIN или INNER JOIN, используйте их — это почти всегда быстрее.
Работа с большими данными: если корреляция ссылается на большие неиндексированные таблицы, повторные вычисления могут значительно замедлить запрос.
Ниже перечислены частые проблемы, с которыми вы можете столкнуться при использовании коррелированных подзапросов, и способы их устранения:
Умение понимать, когда и как использовать коррелированные подзапросы, а когда заменить их другими приёмами, — важный навык для написания понятных и эффективных запросов SQL.
Далее рекомендую получить нашу сертификацию SQL Associate, чтобы подтвердить своё мастерство применения SQL для анализа данных и выгодно выделиться среди других специалистов. Напоследок рекомендую пройти курс Database Design, где вы научитесь создавать и администрировать базы данных и подбирать подходящую СУБД под ваши задачи.
Изучайте SQL с DataCamp
Course
Course
Course