
Cursus
Artificial Intelligence begrijpen
2 Hr
409.4K
Een veelgestelde vraag in de self-hosted AI-wereld is hoe je kunt chatten met privédocumenten zonder ze naar een cloud-API te sturen.
AnythingLLM is een populair antwoord. Het regelt alles (documentupload, embeddingen, zoeken en chat) in één interface en sluit aan op een breed scala aan LLM-providers. Zo bouw je privé AI-workflows zonder afhankelijk te zijn van cloudservices.
In deze gids leg ik uit wat AnythingLLM is, loop ik door de architectuur, laat ik zien hoe je het installeert met Docker en Ollama, en demonstreer ik een werkende Retrieval-Augmented Generation (RAG)-pipeline. Ik vergelijk het ook met Open WebUI en ChatGPT.
AnythingLLM is een open-source applicatie, gebouwd door Mintplex Labs onder de MIT-licentie. Het heeft een actieve GitHub-community en frequente releases en wordt veel gebruikt in de self-hosted AI-wereld.
Wat het doet: het zet je documenten om in context die een large language model (LLM) kan gebruiken tijdens gesprekken. Je uploadt bestanden, het systeem verwerkt en slaat ze op, en daarna kan de LLM vragen beantwoorden op basis van jouw data. Het project is snel gegroeid, met een actieve Discord-community en maandelijkse updates die nieuwe LLM-providers en functies toevoegen.
Twee dingen om vooraf te begrijpen. Ten eerste: AnythingLLM is geen model op zich. Het is een brug die je verbindt met externe LLM-providers, zowel lokaal (zoals Ollama) als cloudgebaseerd (zoals OpenAI of Anthropic).
Ten tweede: het platform organiseert alles in workspaces. Zie dit als aparte kamers voor verschillende projecten. Elke workspace heeft eigen documenten en gesprekken die geïsoleerd blijven, tenzij je ze expliciet laat delen.
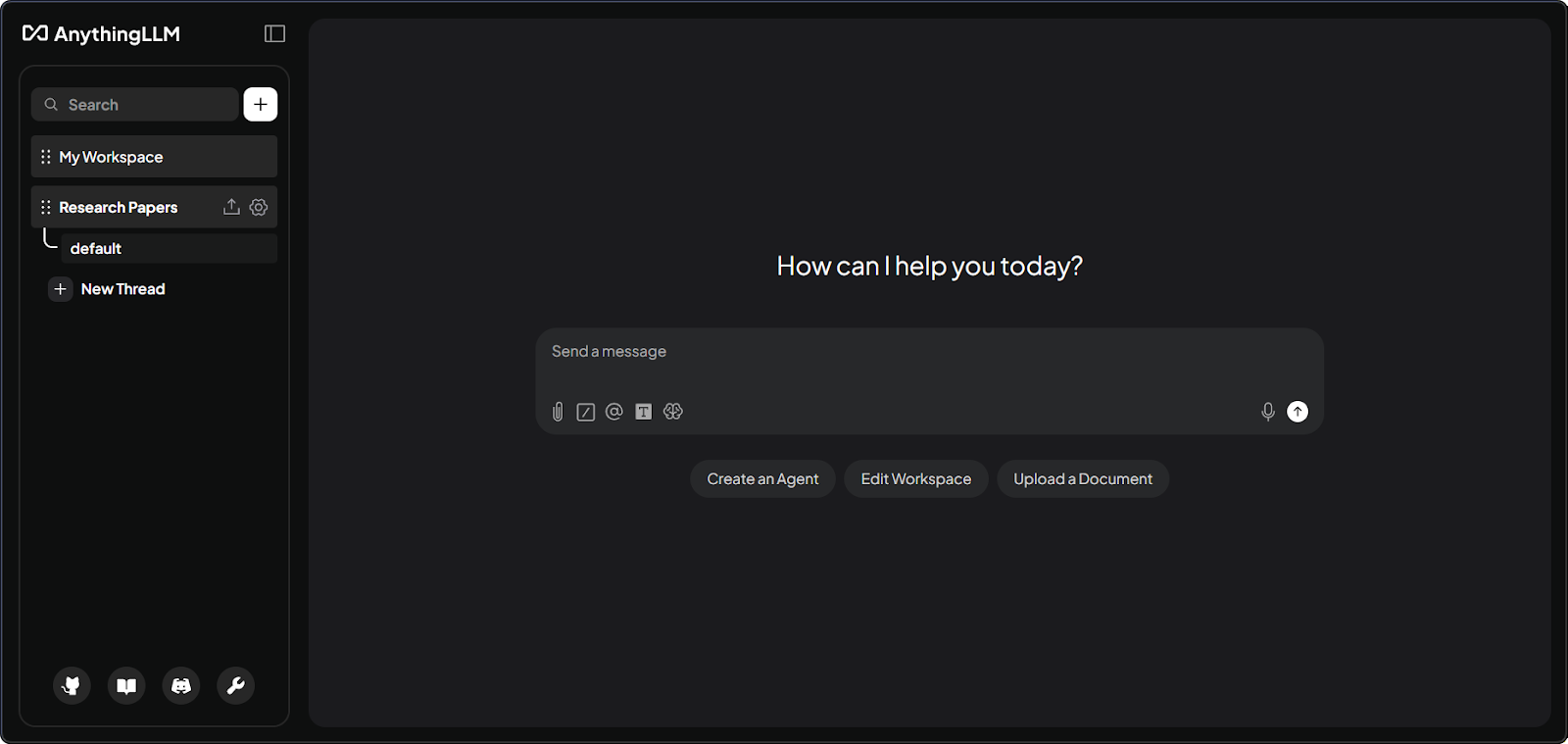
AnythingLLM workspace-interface met documenten. Afbeelding door de auteur.
De desktop-app (macOS, Windows, Linux) is voor individuele gebruikers die alles lokaal draaien. Hij wordt geleverd met een ingebouwde LLM-engine, CPU-gebaseerde embedder en meegeleverde LanceDB. Installatie met één klik, geen configuratie nodig.
De Docker-versie is gebouwd voor teams en servers. Die voegt degelijke toegangscontrole toe met Admin-, Manager- en Default-rollen, plus insluitbare chat-widgets voor websites en white-labeling. Als je teamtoegang of publiek toegankelijke chat-widgets nodig hebt, is Docker je enige optie.
|
Functie |
Desktop |
Docker |
|
Ondersteuning voor meerdere gebruikers |
Nee |
Ja (Admin-, Manager-, Default-rollen) |
|
Ingebouwde LLM-engine |
Ja |
Nee (verbind met externe providers) |
|
Insluitbare chat-widgets |
Nee |
Ja |
|
White-labeling |
Nee |
Ja |
|
Complexiteit van de setup |
Installatie met één klik |
Vereist Docker-kennis |
Nu je weet wat AnythingLLM is en hoe je kiest tussen Desktop en Docker, lopen we door de functies die het nuttig maken voor documentgebaseerde AI-workflows.
Werkt met PDF, DOCX, TXT, Markdown, CSV, XLSX, PPTX, HTML, 50+ codebestandstypen en audiobestanden (met Whisper-transcriptie). Je kunt ook direct content ophalen uit GitHub-repo's, YouTube-transcripten, Confluence-pagina's en websites met de ingebouwde scraper.
LanceDB is ingebouwd en vereist nul setup. Heb je enterprise-functies nodig, dan kun je overschakelen naar Chroma, Milvus, Pinecone, Qdrant, Weaviate, Zilliz, AstraDB of PGVector.
Ondersteunt een breed scala aan providers, waaronder Ollama, LM Studio, OpenAI, Anthropic, Azure OpenAI, Google Gemini, AWS Bedrock, Groq en DeepSeek. Je kiest per workspace modellen, zodat één workspace een lokaal Ollama-model kan gebruiken voor gevoelige zaken terwijl een andere GPT-4o via OpenAI gebruikt.
Typ @agent in elke chat om de no-code agent builder te activeren. Die heeft ingebouwde skills voor zoeken in documenten, samenvatten en webscraping. Agent Flows geeft je een visueel canvas om API-calls, LLM-instructies en bestandsbewerkingen aan elkaar te koppelen. Het ondersteunt ook Model Context Protocol (MCP) voor het koppelen van externe tools.
De developer-API staat op /api/docs (Swagger-docs). Je kunt programmatisch workspaces beheren, documenten embedden en chatberichten sturen.
De applicatie heeft drie delen: de frontend (React/ViteJS) geeft je de interface die je ziet en bedient. De server (Express-backend) handelt alle LLM-interacties, het werk met de vector-database en API-verzoeken af. Hij gebruikt SQLite voor het opslaan van configuratie. De collector is een aparte service die je geüploade documenten parseert en verwerkt. Als je een PDF uploadt, extraheert de collector de tekst, daarna hakt de server die in stukken, embedt ze en slaat ze op.
De pipeline werkt in twee fasen.
Inname: Je documenten gaan naar de collector, die de tekst extraheert. De server splitst deze tekst vervolgens in chunks (tot 1.000 tekens met een kleine overlap om context te behouden). Elke chunk wordt omgezet in een vector door het embeddingmodel en dan opgeslagen in de vector-database. Een vector-cache/ -map vermindert onnodig opnieuw embedden in veel gevallen.
Query: Je vraag wordt omgezet in een vector met hetzelfde embeddingmodel. Vervolgens zoekt het systeem de meest vergelijkbare chunks (meestal vier tot zes). Na filtering op gelijkenisscore wordt de overeenkomende tekst toegevoegd aan de LLM-prompt, samen met je vraag en chathistorie. De LLM leest dit alles (systeemaanwijzingen, opgehaalde context, je vraag en vorige berichten) en genereert het antwoord.
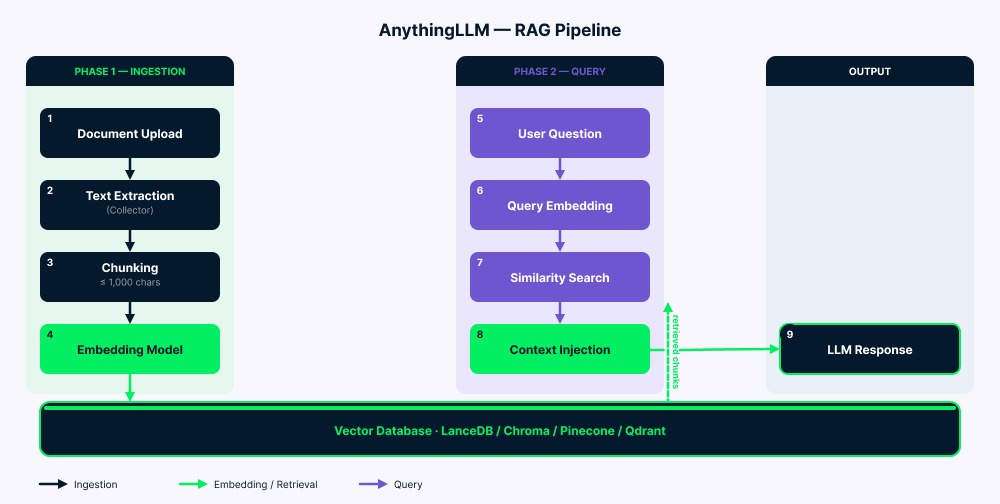
Architectuuroverzicht van de AnythingLLM RAG-pipeline. Afbeelding door de auteur.
Zoals je in de FAQ ziet, is AnythingLLM lichtgewicht: ongeveer 2GB RAM, een 2-core CPU en circa 5GB opslag. Het lokaal draaien van een LLM ernaast vereist meer (een 7B-model heeft meestal 8GB+ RAM/VRAM nodig). Voor deze tutorial gebruik ik een 3B-model dat werkt op beperkte hardware. Zorg dat Docker is geïnstalleerd en draait voordat je begint. Windows-gebruikers hebben ook WSL nodig.
Download Ollama van ollama.com/download, en pull daarna een chatmodel en een embeddingmodel:
ollama pull llama3.2:3b
ollama pull nomic-embed-text
ollama serveIk gebruik llama3.2:3b omdat het goed draait op machines met beperkte VRAM (zoals een RTX 3050 met 6GB). Voor betere kwaliteit kun je llama3.2:8b of deepseek-r1:7b proberen als je hardware het toelaat. Bekijk onze gids over LLMs lokaal draaien voor meer modelopties.
mkdir anythingllm-setup && cd anythingllm-setup
touch .envMaak docker-compose.yml aan:
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
cap_add:
- SYS_ADMIN
volumes:
- anythingllm_storage:/app/server/storage
- ./.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
anythingllm_storage:Een paar aandachtspunten bij deze configuratie. De vlag cap_add: SYS_ADMIN is vereist voor de ingebouwde PuppeteerJS-webscraper, die een gesandboxte Chromium-browser gebruikt.
De regel extra_hosts lost het meest voorkomende Docker-netwerkprobleem op: hij laat de container Ollama bereiken die op je hostmachine draait. Zonder dit zal elke poging om te verbinden met localhost:11434 vanuit de container mislukken omdat Docker-containers hun eigen netwerknamespace hebben.
Ik gebruik een benoemde Docker-volume (anythingllm_storage) in plaats van een bind mount voor betere cross-platform compatibiliteit, vooral op Windows en macOS, waar bind mount-permissies problematisch kunnen zijn.
Wacht ongeveer 30 seconden tot de container is geïnitialiseerd en open dan http://localhost:3001. Je ziet de eerste-installatiewizard. Maar voer eerst dit commando uit:
docker compose up -d
AnythingLLM initiële installatiewizard op Docker. Afbeelding door de auteur.
Selecteer tijdens de installatiewizard Ollama als zowel de LLM- als embeddingprovider, stel de basis-URL in op http://host.docker.internal:11434, kies llama3.2:3b als chatmodel en nomic-embed-text als embedder. Laat LanceDB staan als de standaard vector-database.
Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
