
Kursus
Memahami Kecerdasan Buatan
2 Hr
409.4K
Pertanyaan umum di ranah AI self-hosted adalah bagaimana cara mengobrol dengan dokumen privat tanpa mengirimkannya ke API cloud.
AnythingLLM adalah jawaban populer. Ia menangani semuanya (unggah dokumen, embedding, pencarian, dan chat) dalam satu antarmuka dan terhubung ke berbagai penyedia LLM. Ini memungkinkan Anda membangun alur kerja AI privat tanpa bergantung pada layanan cloud.
Dalam panduan ini, saya akan menjelaskan apa itu AnythingLLM, menelusuri arsitekturnya, menunjukkan cara memasangnya dengan Docker dan Ollama, dan mendemonstrasikan pipeline Retrieval-Augmented Generation (RAG) yang berfungsi. Saya juga akan membandingkannya dengan Open WebUI dan ChatGPT.
AnythingLLM adalah aplikasi open-source yang dibuat oleh Mintplex Labs di bawah lisensi MIT. Memiliki komunitas GitHub yang aktif dan rilis yang sering, serta banyak digunakan di ranah AI self-hosted.
Inilah fungsinya: ia mengubah dokumen Anda menjadi konteks yang dapat digunakan large language model (LLM) selama percakapan. Anda mengunggah file, sistem memproses dan menyimpannya, lalu LLM dapat menjawab pertanyaan berdasarkan data Anda. Proyek ini berkembang pesat, dengan komunitas Discord yang aktif dan pembaruan bulanan yang menambahkan penyedia LLM dan fitur baru.
Ada dua hal yang perlu dipahami di awal. Pertama, AnythingLLM bukanlah model itu sendiri. Ini adalah jembatan yang menghubungkan Anda ke penyedia LLM eksternal, baik lokal (seperti Ollama) maupun berbasis cloud (seperti OpenAI atau Anthropic).
Kedua, platform ini mengatur semuanya ke dalam workspace. Anggap ini sebagai ruangan terpisah untuk proyek berbeda. Setiap workspace memiliki dokumen dan percakapan sendiri yang tetap terisolasi kecuali Anda mengonfigurasikan untuk berbagi.
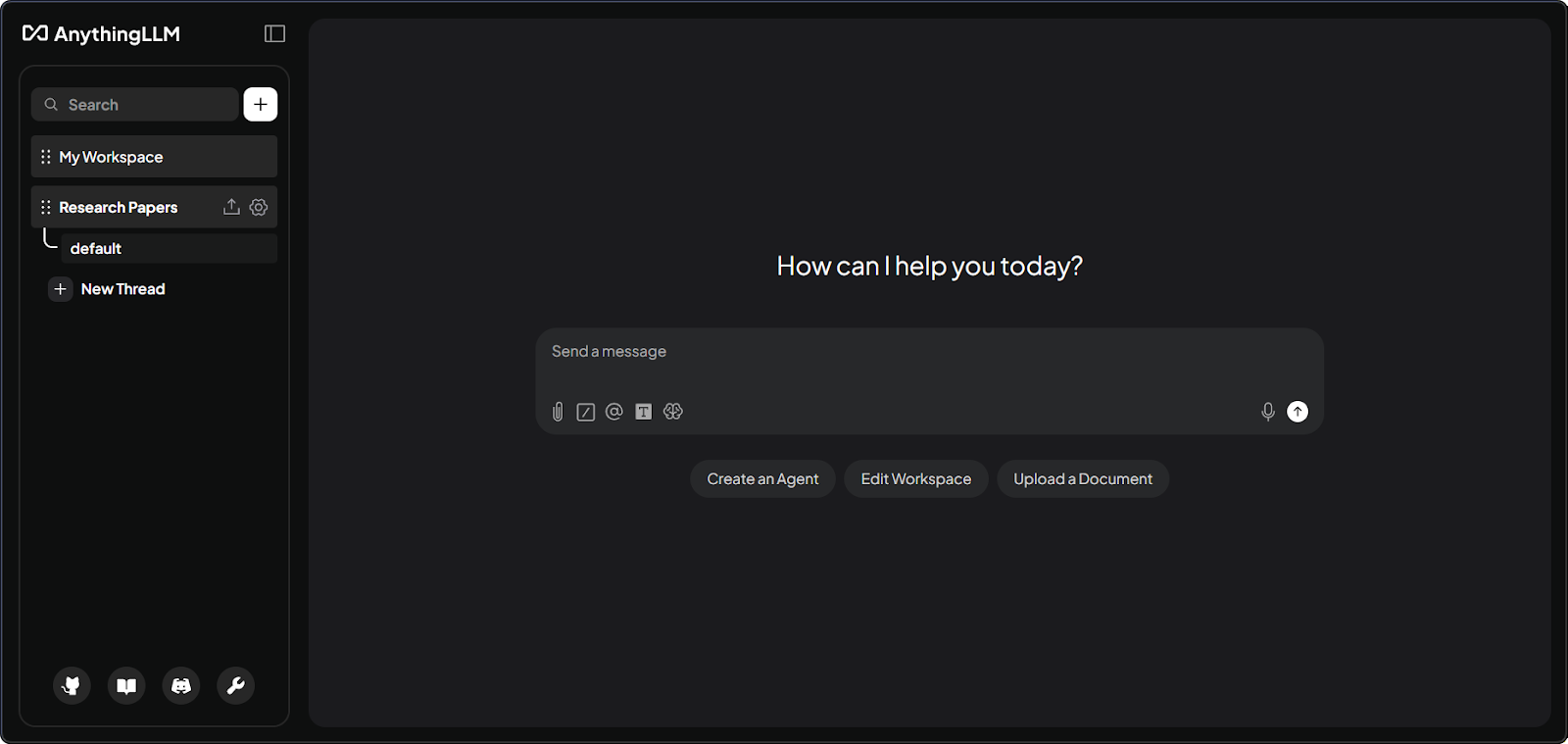
Antarmuka workspace AnythingLLM dengan dokumen. Gambar oleh Penulis.
Aplikasi desktop (macOS, Windows, Linux) ditujukan untuk pengguna tunggal yang menjalankan semuanya secara lokal. Aplikasi ini dilengkapi mesin LLM bawaan, embedder berbasis CPU, dan LanceDB terpaket. Instal sekali klik, tanpa perlu konfigurasi.
Versi Docker dibuat untuk tim dan server. Ia menambahkan kontrol akses yang tepat dengan peran Admin, Manager, dan Default, plus widget chat yang bisa disematkan di situs web dan white-labeling. Jika Anda memerlukan akses tim atau widget chat untuk publik, Docker adalah satu-satunya opsi.
|
Fitur |
Desktop |
Docker |
|
Dukungan multi-pengguna |
Tidak |
Ya (peran Admin, Manager, Default) |
|
Mesin LLM bawaan |
Ya |
Tidak (hubungkan ke penyedia eksternal) |
|
Widget chat yang dapat disematkan |
Tidak |
Ya |
|
White-labeling |
Tidak |
Ya |
|
Kompleksitas setup |
Instal sekali klik |
Memerlukan pengetahuan Docker |
Sekarang Anda sudah tahu apa itu AnythingLLM dan cara memilih antara Desktop dan Docker, mari kita telusuri fitur-fitur yang membuatnya berguna untuk alur kerja AI berbasis dokumen.
Bekerja dengan PDF, DOCX, TXT, Markdown, CSV, XLSX, PPTX, HTML, 50+ jenis file kode, dan file audio (menggunakan transkripsi Whisper). Anda juga dapat menarik konten langsung dari repo GitHub, transkrip YouTube, halaman Confluence, dan situs web menggunakan scraper bawaan.
LanceDB sudah terpasang dan tidak perlu setup. Jika Anda memerlukan fitur enterprise, Anda bisa beralih ke Chroma, Milvus, Pinecone, Qdrant, Weaviate, Zilliz, AstraDB, atau PGVector.
Mendukung berbagai penyedia, termasuk Ollama, LM Studio, OpenAI, Anthropic, Azure OpenAI, Google Gemini, AWS Bedrock, Groq, dan DeepSeek. Anda memilih model per workspace, sehingga satu workspace dapat memakai model Ollama lokal untuk data sensitif sementara workspace lain memakai GPT-4o lewat OpenAI.
Ketik @agent di chat mana pun untuk mengaktifkan pembuat agen tanpa kode. Memiliki skill bawaan untuk pencarian dokumen, rangkuman, dan web scraping. Agent Flows memberi kanvas visual untuk merangkai panggilan API, instruksi LLM, dan operasi file. Juga mendukung Model Context Protocol (MCP) untuk menghubungkan tool eksternal.
API untuk pengembang tersedia di /api/docs (dokumentasi Swagger). Anda dapat mengelola workspace, melakukan embedding dokumen, dan mengirim pesan chat secara terprogram.
Aplikasi ini memiliki tiga bagian: frontend (React/ViteJS) memberi antarmuka yang Anda lihat dan gunakan. Server (backend Express) menangani semua interaksi LLM, pekerjaan basis data vektor, dan permintaan API. Ia menggunakan SQLite untuk menyimpan konfigurasi. Collector adalah layanan terpisah yang mengurai dan memproses dokumen yang Anda unggah. Saat Anda mengunggah PDF, collector mengekstrak teks, lalu server memecah, melakukan embedding, dan menyimpannya.
Pipeline bekerja dalam dua fase.
Ingesti: Dokumen Anda masuk ke collector, yang mengekstrak teks. Server kemudian membagi teks ini menjadi potongan (hingga 1.000 karakter dengan sedikit overlap untuk menjaga konteks). Setiap potongan diubah menjadi vektor oleh model embedding, lalu disimpan di basis data vektor. Folder vector-cache/ mengurangi embedding ulang yang tidak perlu dalam banyak kasus.
Kueri: Pertanyaan Anda diubah menjadi vektor menggunakan model embedding yang sama. Lalu sistem mencari potongan yang paling mirip (biasanya empat hingga enam). Setelah difilter berdasarkan skor kemiripan, teks yang cocok ditambahkan ke prompt LLM bersama dengan pertanyaan dan riwayat chat Anda. LLM membaca semuanya (instruksi sistem, konteks yang diambil, pertanyaan Anda, dan pesan sebelumnya) lalu menghasilkan jawabannya.
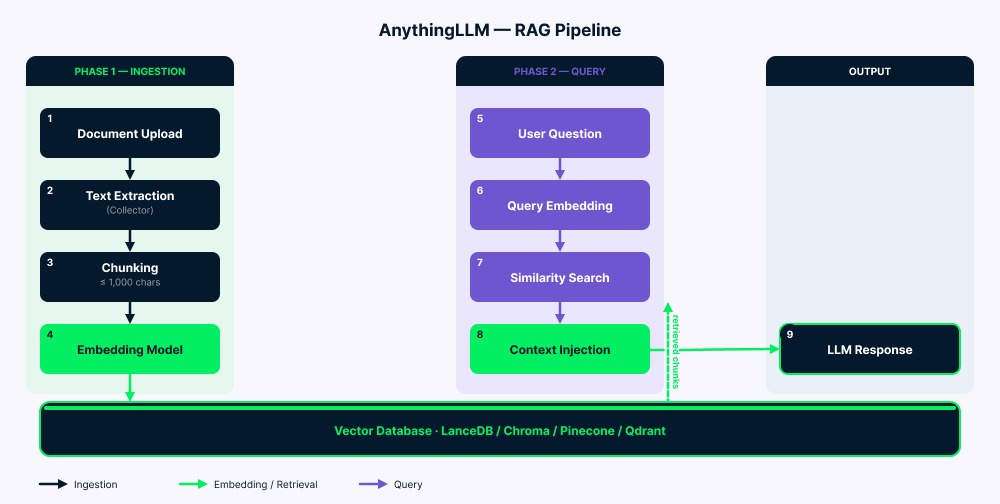
Tinjauan arsitektur pipeline RAG AnythingLLM. Gambar oleh Penulis.
Seperti yang akan Anda lihat di FAQ, AnythingLLM ringan: sekitar 2GB RAM, CPU 2-core, dan sekitar 5GB penyimpanan. Menjalankan LLM lokal bersamaan memerlukan lebih banyak (model 7B biasanya butuh 8GB+ RAM/VRAM). Untuk tutorial ini, saya menggunakan model 3B yang bekerja pada hardware terbatas. Pastikan Docker terinstal dan berjalan sebelum memulai. Pengguna Windows juga memerlukan WSL.
Unduh Ollama dari ollama.com/download, lalu tarik sebuah model chat dan model embedding:
ollama pull llama3.2:3b
ollama pull nomic-embed-text
ollama serveSaya memakai llama3.2:3b karena berjalan baik pada mesin dengan VRAM terbatas (seperti RTX 3050 dengan 6GB). Untuk kualitas lebih baik, coba llama3.2:8b atau deepseek-r1:7b jika hardware Anda memungkinkan. Lihat panduan kami tentang menjalankan LLM secara lokal untuk opsi model lainnya.
mkdir anythingllm-setup && cd anythingllm-setup
touch .envBuat docker-compose.yml:
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
cap_add:
- SYS_ADMIN
volumes:
- anythingllm_storage:/app/server/storage
- ./.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
anythingllm_storage:Beberapa hal terkait konfigurasi ini. Flag cap_add: SYS_ADMIN diperlukan untuk web scraper PuppeteerJS bawaan, yang menggunakan browser Chromium tersandbox.
Baris extra_hosts menyelesaikan masalah jaringan Docker yang paling umum: ia memungkinkan container menjangkau Ollama yang berjalan di mesin host Anda. Tanpa ini, setiap upaya menghubungkan ke localhost:11434 dari dalam container akan gagal karena container Docker memiliki namespace jaringan sendiri.
Saya menggunakan volume Docker bernama (anythingllm_storage) alih-alih bind mount untuk kompatibilitas lintas platform yang lebih baik, terutama di Windows dan macOS, di mana izin bind mount bisa bermasalah.
Tunggu sekitar 30 detik hingga container inisialisasi, lalu buka http://localhost:3001. Anda akan melihat wizard setup pertama. Namun sebelumnya, jalankan perintah ini:
docker compose up -d
Wizard setup awal AnythingLLM di Docker. Gambar oleh Penulis.
Selama wizard setup, pilih Ollama sebagai penyedia LLM dan embedding, setel base URL ke http://host.docker.internal:11434, pilih llama3.2:3b sebagai model chat, dan nomic-embed-text sebagai embedder. Biarkan LanceDB sebagai basis data vektor default.
Belajar bersama DataCamp
Kursus
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
