
Cours
Comprendre l'intelligence artificielle
2 h
408.4K
Une question récurrente dans l’univers de l’IA auto-hébergée est la suivante : comment discuter avec des documents privés sans les envoyer à une API cloud ?
AnythingLLM est une réponse plébiscitée. Il gère tout (téléversement de documents, embeddings, recherche et chat) dans une seule interface et se connecte à un large écosystème de fournisseurs de LLM. Vous pouvez bâtir des workflows d’IA privés sans dépendre de services cloud.
Dans ce guide, j’explique ce qu’est AnythingLLM, j’en décris l’architecture, je vous montre comment l’installer avec Docker et Ollama, et je démontre un pipeline Retrieval-Augmented Generation (RAG) opérationnel. Je le comparerai également à Open WebUI et à ChatGPT.
AnythingLLM est une application open source de Mintplex Labs sous licence MIT. Elle dispose d’une communauté GitHub active, de sorties fréquentes, et est largement adoptée dans l’écosystème de l’IA auto-hébergée.
Son rôle : transformer vos documents en contexte exploitable par un grand modèle de langage (LLM) pendant la conversation. Vous téléversez des fichiers, le système les traite et les stocke, puis le LLM peut répondre à des questions en s’appuyant sur vos données. Le projet a rapidement gagné en ampleur, avec une communauté Discord active et des mises à jour mensuelles ajoutant de nouveaux fournisseurs et fonctionnalités.
Deux points clés : premièrement, AnythingLLM n’est pas un modèle en soi. C’est un pont vers des fournisseurs de LLM externes, locaux (comme Ollama) ou cloud (OpenAI, Anthropic, etc.).
Deuxièmement, la plateforme s’organise en espaces de travail. Imaginez des salles distinctes pour chaque projet. Chaque espace dispose de ses propres documents et conversations, qui restent isolés sauf configuration explicite de partage.
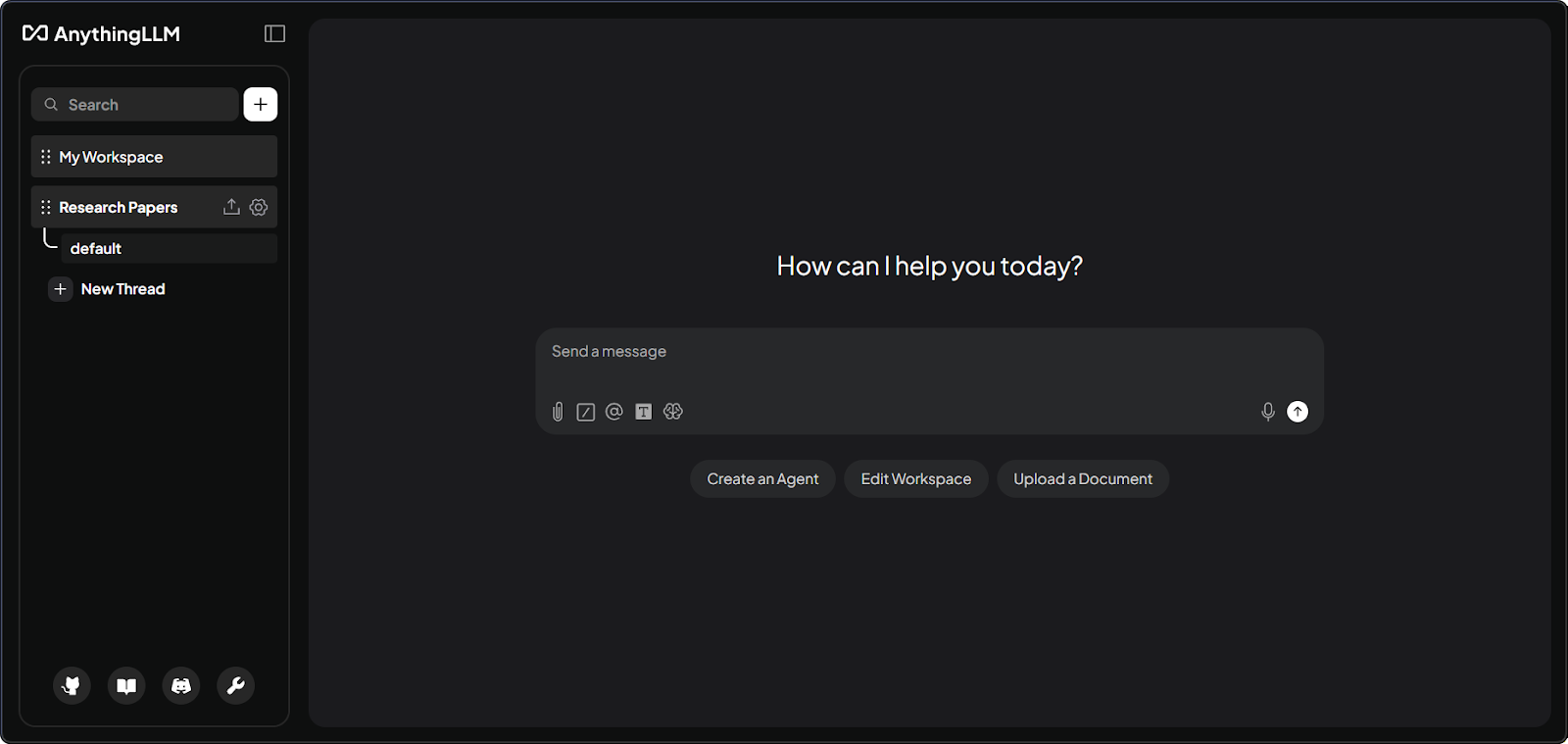
Interface d’espace de travail AnythingLLM avec documents. Image par l’auteur.
L’application de bureau (macOS, Windows, Linux) s’adresse à un utilisateur unique qui exécute tout en local. Elle inclut un moteur LLM intégré, un embedder sur CPU, et LanceDB embarqué. Installation en un clic, sans configuration.
La version Docker est conçue pour les équipes et les serveurs. Elle ajoute un contrôle d’accès (rôles Admin, Manager, Default), des widgets de chat embarquables pour sites web et le white-label. Si vous avez besoin d’accès équipe ou de widgets publics, Docker est votre seule option.
|
Fonctionnalité |
Bureau |
Docker |
|
Support multi-utilisateurs |
Non |
Oui (rôles Admin, Manager, Default) |
|
Moteur LLM intégré |
Oui |
Non (connexion à des fournisseurs externes) |
|
Widgets de chat embarquables |
Non |
Oui |
|
White-label |
Non |
Oui |
|
Complexité d'installation |
Installation en un clic |
Nécessite des compétences Docker |
Maintenant que vous savez ce qu’est AnythingLLM et comment choisir entre Bureau et Docker, passons en revue les atouts qui le rendent utile pour des workflows d’IA centrés documents.
Compatible avec PDF, DOCX, TXT, Markdown, CSV, XLSX, PPTX, HTML, plus de 50 types de fichiers code, et fichiers audio (via la transcription Whisper). Vous pouvez aussi aspirer du contenu directement depuis des dépôts GitHub, des transcriptions YouTube, des pages Confluence et des sites web via le scraper intégré.
LanceDB est intégré et ne demande aucune configuration. Pour des besoins entreprise, vous pouvez passer à Chroma, Milvus, Pinecone, Qdrant, Weaviate, Zilliz, AstraDB ou PGVector.
Large choix de fournisseurs : Ollama, LM Studio, OpenAI, Anthropic, Azure OpenAI, Google Gemini, AWS Bedrock, Groq, DeepSeek. Vous choisissez les modèles par espace de travail : un espace peut utiliser un modèle Ollama local pour les sujets sensibles tandis qu’un autre exploite GPT-4o via OpenAI.
Tapez @agent dans n’importe quel chat pour activer le builder d’agents no-code. Compétences intégrées : recherche documentaire, synthèse, scraping web. Agent Flows propose un canvas visuel pour chaîner appels d’API, instructions LLM et opérations fichiers. Compatible Model Context Protocol (MCP) pour connecter des outils externes.
L’API développeur est disponible sur /api/docs (docs Swagger). Vous pouvez gérer les espaces de travail, embarquer des documents et envoyer des messages de chat par programmation.
L’application comporte trois volets : le frontend (React/ViteJS) qui fournit l’interface, le serveur (backend Express) qui gère les interactions LLM, la base vectorielle et les requêtes API. Il utilise SQLite pour la configuration. Le collecteur est un service distinct qui parse et traite vos documents téléversés. Quand vous importez un PDF, le collecteur extrait le texte, puis le serveur segmente, embed et stocke.
Le pipeline fonctionne en deux phases.
Ingestion : vos documents arrivent au collecteur, qui extrait le texte. Le serveur découpe ensuite ce texte en segments (jusqu’à 1 000 caractères avec un petit chevauchement pour le contexte). Chaque segment est converti en vecteur par le modèle d’embedding, puis stocké dans la base vectorielle. Un dossier vector-cache/ réduit les re-embeddings inutiles dans de nombreux cas.
Requête : votre question est convertie en vecteur avec le même modèle d’embedding. Le système recherche ensuite les segments les plus similaires (généralement 4 à 6). Après filtrage par score de similarité, le texte correspondant est ajouté au prompt du LLM avec votre question et l’historique de chat. Le LLM lit l’ensemble (instructions système, contexte retrouvé, votre question, messages précédents) et génère sa réponse.
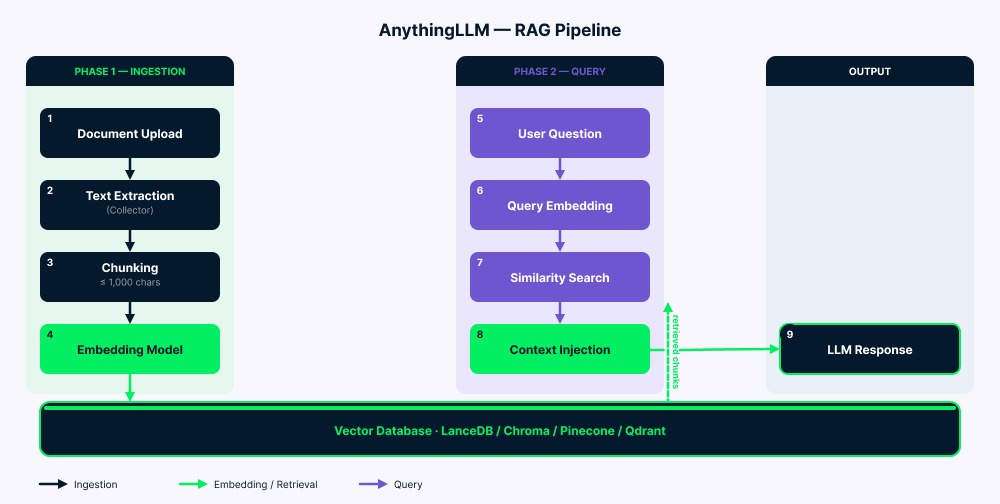
Vue d’ensemble de l’architecture du pipeline RAG AnythingLLM. Image par l’auteur.
Comme indiqué dans la FAQ, AnythingLLM est léger : environ 2 Go de RAM, un CPU 2 cœurs et 5 Go de stockage. Faire tourner un LLM local en parallèle demande plus (un modèle 7B requiert typiquement 8 Go+ de RAM/VRAM). Pour ce tutoriel, j’utilise un modèle 3B adapté au matériel limité. Assurez-vous que Docker est installé et actif avant de commencer. Sous Windows, WSL est nécessaire.
Téléchargez Ollama depuis ollama.com/download, puis téléchargez un modèle de chat et un modèle d’embedding :
ollama pull llama3.2:3b
ollama pull nomic-embed-text
ollama serveJ’emploie llama3.2:3b car il fonctionne bien sur des machines à VRAM limitée (ex. RTX 3050 avec 6 Go). Pour une meilleure qualité, essayez llama3.2:8b ou deepseek-r1:7b si votre matériel le permet. Consultez notre guide sur l’exécution de LLMs en local pour d’autres options.
mkdir anythingllm-setup && cd anythingllm-setup
touch .envCréez docker-compose.yml :
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
cap_add:
- SYS_ADMIN
volumes:
- anythingllm_storage:/app/server/storage
- ./.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
anythingllm_storage:Quelques remarques : le flag cap_add: SYS_ADMIN est requis pour le scraper web PuppeteerJS intégré, qui utilise un navigateur Chromium sandboxé.
La ligne extra_hosts résout le problème de réseau Docker le plus courant : elle permet au conteneur d’atteindre Ollama qui tourne sur votre machine hôte. Sans cela, toute tentative de connexion à localhost:11434 depuis le conteneur échouera, car les conteneurs disposent de leur propre espace de noms réseau.
J’utilise un volume Docker nommé (anythingllm_storage) plutôt qu’un bind mount pour une meilleure compatibilité multi-plateformes, notamment sous Windows et macOS où les permissions des bind mounts peuvent poser problème.
Patientez environ 30 secondes le temps que le conteneur s’initialise, puis ouvrez http://localhost:3001. L’assistant de première configuration s’affiche. Mais d’abord, exécutez cette commande :
docker compose up -d
Assistant de configuration initiale AnythingLLM sur Docker. Image par l’auteur.
Pendant l’assistant, sélectionnez Ollama comme fournisseur LLM et embedder, définissez l’URL de base sur http://host.docker.internal:11434, choisissez llama3.2:3b comme modèle de chat et nomic-embed-text comme embedder. Conservez LanceDB comme base vectorielle par défaut.
Learn with DataCamp
Cours
Cours
Cours