
Curso
Comprender la inteligencia artificial
2 h
408.4K
Una duda habitual en el mundo de la IA autoalojada es cómo chatear con documentos privados sin enviarlos a una API en la nube.
AnythingLLM es una de las respuestas más populares. Se encarga de todo (subida de documentos, embedding, búsqueda y chat) en una sola interfaz y conecta con una gran variedad de proveedores de LLM. Te permite crear flujos de IA privados sin depender de servicios en la nube.
En esta guía, te explicaré qué es AnythingLLM, revisaré su arquitectura, te mostraré cómo instalarlo con Docker y Ollama y te enseñaré una pipeline de Retrieval-Augmented Generation (RAG) en funcionamiento. También lo compararé con Open WebUI y ChatGPT.
AnythingLLM es una aplicación de código abierto creada por Mintplex Labs bajo licencia MIT. Tiene una comunidad activa en GitHub, lanzamientos frecuentes y es muy utilizada en el ecosistema de IA autoalojada.
¿Qué hace? Convierte tus documentos en contexto que un large language model (LLM) puede usar durante las conversaciones. Subes archivos, el sistema los procesa y los guarda, y luego el LLM puede responder preguntas basándose en tus datos. El proyecto ha crecido rápido, con una comunidad activa en Discord y actualizaciones mensuales que añaden nuevos proveedores de LLM y funciones.
Dos cosas importantes de entrada. Primero, AnythingLLM no es un modelo en sí. Es un puente que te conecta con proveedores externos de LLM, ya sean locales (como Ollama) o en la nube (como OpenAI o Anthropic).
Segundo, la plataforma organiza todo en workspaces. Piensa en ellos como salas separadas para distintos proyectos. Cada workspace tiene sus propios documentos y conversaciones que permanecen aislados salvo que configures explícitamente que compartan.
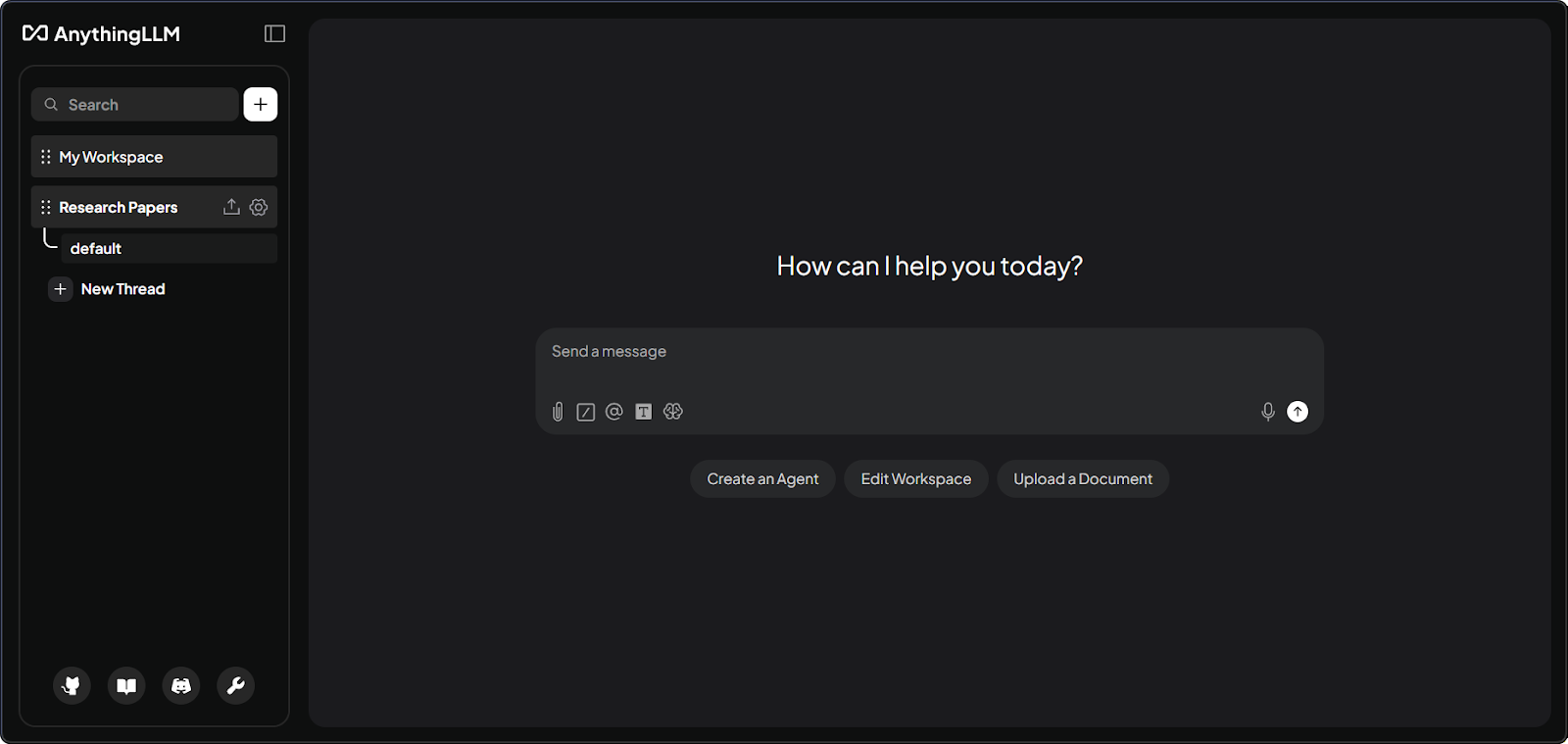
Interfaz del workspace de AnythingLLM con documentos. Imagen del autor.
La app de escritorio (macOS, Windows, Linux) está pensada para una sola persona ejecutándolo todo en local. Incluye un motor LLM integrado, un embedder por CPU y LanceDB incluido. Instalación con un clic y sin configuración.
La versión Docker está orientada a equipos y servidores. Añade control de acceso con roles Admin, Manager y Default, además de widgets de chat insertables en webs y white-label. Si necesitas acceso de equipo o widgets públicos, Docker es tu única opción.
|
Función |
Escritorio |
Docker |
|
Soporte multiusuario |
No |
Sí (roles Admin, Manager, Default) |
|
Motor LLM integrado |
Sí |
No (conecta con proveedores externos) |
|
Widgets de chat insertables |
No |
Sí |
|
White-label |
No |
Sí |
|
Complejidad de configuración |
Instalación con un clic |
Requiere conocimientos de Docker |
Ahora que ya sabes qué es AnythingLLM y cómo elegir entre Escritorio y Docker, veamos las funciones que lo hacen útil para flujos de IA basados en documentos.
Funciona con PDF, DOCX, TXT, Markdown, CSV, XLSX, PPTX, HTML, más de 50 tipos de archivos de código y archivos de audio (usando transcripción con Whisper). También puedes extraer contenido directamente de repos de GitHub, transcripciones de YouTube, páginas de Confluence y sitios web con el scraper integrado.
LanceDB viene integrado y no requiere configuración. Si necesitas funciones para empresa, puedes cambiar a Chroma, Milvus, Pinecone, Qdrant, Weaviate, Zilliz, AstraDB o PGVector.
Admite una amplia gama de proveedores, incluidos Ollama, LM Studio, OpenAI, Anthropic, Azure OpenAI, Google Gemini, AWS Bedrock, Groq y DeepSeek. Puedes elegir modelos por workspace, así que un workspace puede usar un modelo local de Ollama para temas sensibles y otro usar GPT-4o a través de OpenAI.
Escribe @agent en cualquier chat para activar el creador de agentes sin código. Incluye habilidades integradas para buscar en documentos, resumir y hacer scraping web. Agent Flows te da un lienzo visual para encadenar llamadas a APIs, instrucciones al LLM y operaciones con archivos. También admite Model Context Protocol (MCP) para conectar herramientas externas.
La API para desarrolladores está en /api/docs (documentación Swagger). Puedes gestionar workspaces, hacer embedding de documentos y enviar mensajes de chat de forma programática.
La aplicación tiene tres partes: el frontend (React/ViteJS) te da la interfaz con la que interactúas. El servidor (backend en Express) gestiona todas las interacciones con LLM, el trabajo con la base de datos vectorial y las peticiones a la API. Usa SQLite para almacenar la configuración. El collector es un servicio aparte que analiza y procesa los documentos que subes. Cuando subes un PDF, el collector extrae el texto, y luego el servidor trocea, hace embedding y lo guarda.
La pipeline funciona en dos fases.
Ingesta: Tus documentos van al collector, que extrae el texto. El servidor divide ese texto en fragmentos (hasta 1.000 caracteres con un pequeño solapamiento para mantener el contexto). Cada fragmento se convierte en un vector mediante el modelo de embeddings y luego se guarda en la base de datos vectorial. Una carpeta vector-cache/ reduce re-embeddings innecesarios en muchos casos.
Consulta: Tu pregunta se convierte en un vector usando el mismo modelo de embeddings. Luego el sistema busca los fragmentos más similares (normalmente entre cuatro y seis). Tras filtrar por puntuación de similitud, el texto coincidente se añade al prompt del LLM junto con tu pregunta y el historial del chat. El LLM lee todo (instrucciones del sistema, contexto recuperado, tu pregunta y mensajes previos) y genera la respuesta.
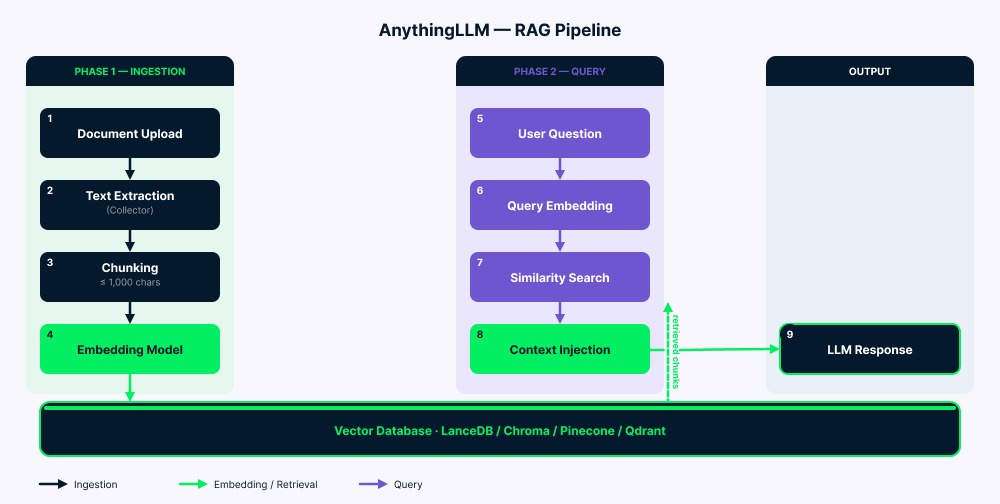
Vista general de la arquitectura RAG de AnythingLLM. Imagen del autor.
Como verás en las preguntas frecuentes, AnythingLLM es ligero: alrededor de 2 GB de RAM, una CPU de 2 núcleos y unos 5 GB de almacenamiento. Ejecutar un LLM local a la vez requiere más (un modelo de 7B suele necesitar 8 GB o más de RAM/VRAM). Para este tutorial uso un modelo de 3B que funciona en hardware limitado. Asegúrate de tener Docker instalado y en ejecución antes de empezar. En Windows también necesitas WSL.
Descarga Ollama desde ollama.com/download y luego descarga un modelo de chat y uno de embeddings:
ollama pull llama3.2:3b
ollama pull nomic-embed-text
ollama serveUso llama3.2:3b porque va bien en máquinas con VRAM limitada (como una RTX 3050 con 6 GB). Para más calidad, prueba llama3.2:8b o deepseek-r1:7b si tu hardware lo permite. Consulta nuestra guía sobre ejecutar LLMs en local para ver más opciones de modelos.
mkdir anythingllm-setup && cd anythingllm-setup
touch .envCrea docker-compose.yml:
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
cap_add:
- SYS_ADMIN
volumes:
- anythingllm_storage:/app/server/storage
- ./.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
anythingllm_storage:Algunas notas sobre esta configuración. La marca cap_add: SYS_ADMIN es necesaria para el scraper web integrado de PuppeteerJS, que usa un navegador Chromium en sandbox.
La línea extra_hosts soluciona el problema de red más común en Docker: permite que el contenedor alcance Ollama ejecutándose en tu máquina host. Sin esto, cualquier intento de conectar a localhost:11434 desde dentro del contenedor fallará porque los contenedores Docker tienen su propio espacio de red.
Uso un volumen con nombre de Docker (anythingllm_storage) en lugar de un bind mount por una mejor compatibilidad multiplataforma, especialmente en Windows y macOS, donde los permisos de bind mount pueden dar problemas.
Espera unos 30 segundos a que el contenedor se inicialice y abre http://localhost:3001. Verás el asistente de primera ejecución. Pero primero, ejecuta este comando:
docker compose up -d
Asistente de configuración inicial de AnythingLLM en Docker. Imagen del autor.
Durante el asistente, selecciona Ollama tanto como proveedor de LLM como de embeddings, define la URL base como http://host.docker.internal:11434, elige llama3.2:3b como modelo de chat y nomic-embed-text como embedder. Mantén LanceDB como base de datos vectorial por defecto.
Aprende con DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Ryan Ong
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali


