
Kurs
Künstliche Intelligenz verstehen
2 Std.
408.4K
Eine häufige Frage im Self-Hosted-KI-Bereich ist, wie man mit privaten Dokumenten chatten kann, ohne sie an eine Cloud-API zu senden.
AnythingLLM ist eine beliebte Antwort darauf. Es übernimmt alles (Dokument-Upload, Embedding, Suche und Chat) in einer Oberfläche und verbindet sich mit einer großen Bandbreite an LLM-Anbietern. So baust du private KI-Workflows, ohne von Cloud-Diensten abhängig zu sein.
In diesem Guide erkläre ich, was AnythingLLM ist, gehe seine Architektur durch, zeige dir die Installation mit Docker und Ollama und demonstriere eine funktionierende Retrieval-Augmented Generation (RAG)-Pipeline. Außerdem vergleiche ich AnythingLLM mit Open WebUI und ChatGPT.
AnythingLLM ist eine Open-Source-Anwendung von Mintplex Labs unter der MIT-Lizenz. Sie hat eine aktive GitHub-Community, erscheint regelmäßig in neuen Versionen und ist im Self-Hosted-KI-Umfeld weit verbreitet.
Kurz gesagt: Es verwandelt deine Dokumente in Kontext, den ein Large Language Model (LLM) während des Gesprächs nutzen kann. Du lädst Dateien hoch, das System verarbeitet und speichert sie und das LLM beantwortet Fragen auf Basis deiner Daten. Das Projekt wächst schnell, mit einer aktiven Discord-Community und monatlichen Updates, die neue LLM-Anbieter und Features bringen.
Zwei Dinge solltest du vorab wissen. Erstens: AnythingLLM ist kein eigenes Modell. Es ist eine Brücke zu externen LLM-Anbietern, egal ob lokal (wie Ollama) oder cloudbasiert (wie OpenAI oder Anthropic).
Zweitens organisiert die Plattform alles in Workspaces. Denk an getrennte Räume für verschiedene Projekte. Jeder Workspace hat eigene Dokumente und Unterhaltungen, die isoliert bleiben, außer du aktivierst bewusst eine Freigabe.
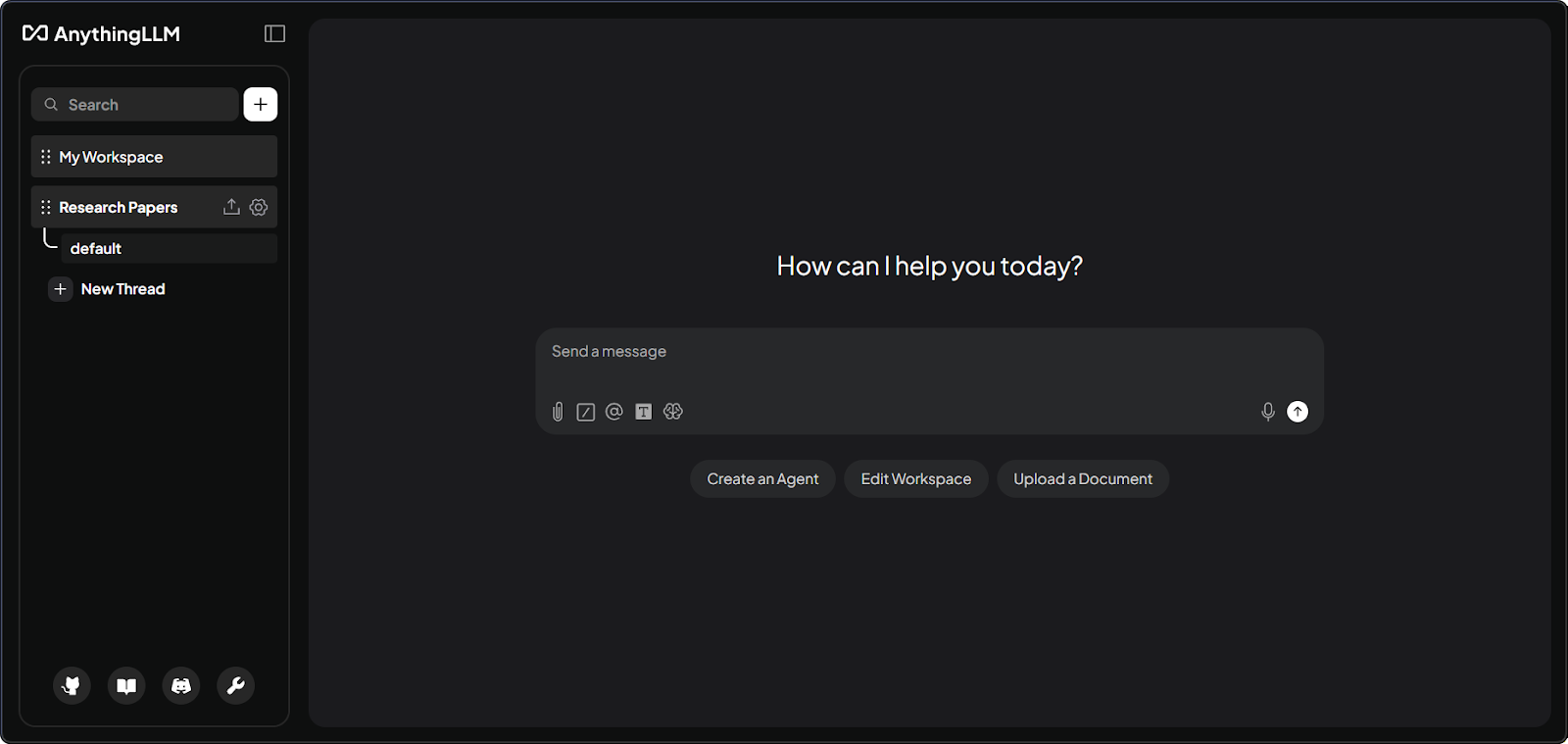
AnythingLLM-Workspace-Oberfläche mit Dokumenten. Bild: Autor.
Die Desktop-App (macOS, Windows, Linux) ist für Einzelnutzer, die alles lokal betreiben. Sie bringt eine integrierte LLM-Engine, einen CPU-basierten Embedder und ein gebündeltes LanceDB mit. Ein-Klick-Installation, keine Konfiguration nötig.
Die Docker-Version ist für Teams und Server gebaut. Sie ergänzt sauberes Zugriffsmanagement mit Admin-, Manager- und Default-Rollen sowie einbettbare Chat-Widgets für Websites und White-Labeling. Wenn du Teamzugriff oder öffentliche Chat-Widgets brauchst, ist Docker deine einzige Option.
|
Funktion |
Desktop |
Docker |
|
Multi-User-Unterstützung |
Nein |
Ja (Admin-, Manager-, Default-Rollen) |
|
Integrierte LLM-Engine |
Ja |
Nein (Anbindung externer Anbieter) |
|
Einbettbare Chat-Widgets |
Nein |
Ja |
|
White-Labeling |
Nein |
Ja |
|
Setup-Komplexität |
Ein-Klick-Installation |
Erfordert Docker-Kenntnisse |
Jetzt, da du weißt, was AnythingLLM ist und wie du zwischen Desktop und Docker wählst, schauen wir uns die Features an, die es für dokumentbasierte KI-Workflows so nützlich machen.
Funktioniert mit PDF, DOCX, TXT, Markdown, CSV, XLSX, PPTX, HTML, 50+ Code-Dateiformaten und Audiodateien (per Whisper-Transkription). Du kannst Inhalte auch direkt aus GitHub-Repos, YouTube-Transkripten, Confluence-Seiten und Websites über den integrierten Scraper ziehen.
LanceDB ist eingebaut und benötigt kein Setup. Wenn du Enterprise-Features brauchst, kannst du auf Chroma, Milvus, Pinecone, Qdrant, Weaviate, Zilliz, AstraDB oder PGVector umschalten.
Unterstützt eine breite Auswahl an Anbietern, darunter Ollama, LM Studio, OpenAI, Anthropic, Azure OpenAI, Google Gemini, AWS Bedrock, Groq und DeepSeek. Du wählst Modelle pro Workspace, sodass ein Workspace ein lokales Ollama-Modell für Sensibles nutzen kann, während ein anderer GPT-4o über OpenAI verwendet.
Tippe @agent in jedem Chat, um den No-Code-Agenten-Builder zu aktivieren. Er hat eingebaute Skills für Dokumentsuche, Zusammenfassungen und Web-Scraping. Agent Flows bietet dir eine visuelle Oberfläche, um API-Aufrufe, LLM-Anweisungen und Dateioperationen zu verketten. Außerdem wird das Model Context Protocol (MCP) für die Anbindung externer Tools unterstützt.
Die Developer-API findest du unter /api/docs (Swagger-Dokumentation). Du kannst Workspaces programmatisch verwalten, Dokumente einbetten und Chat-Nachrichten senden.
Die Anwendung hat drei Teile: Das Frontend (React/ViteJS) ist die Benutzeroberfläche. Der Server (Express-Backend) übernimmt alle LLM-Interaktionen, Vektordatenbank-Aufgaben und API-Requests. Für Konfiguration wird SQLite genutzt. Der Collector ist ein separater Dienst, der deine hochgeladenen Dokumente parst und verarbeitet. Wenn du ein PDF hochlädst, extrahiert der Collector den Text, danach zerlegt der Server ihn, erstellt Embeddings und speichert alles.
Die Pipeline läuft in zwei Phasen.
Ingestion: Deine Dokumente gehen an den Collector, der den Text extrahiert. Der Server teilt den Text anschließend in Chunks (bis zu 1.000 Zeichen mit kleiner Überlappung für Kontext). Jeder Chunk wird vom Embedding-Modell in einen Vektor umgewandelt und in der Vektordatenbank gespeichert. Ein vector-cache/ Ordner reduziert in vielen Fällen unnötige Re-Embeddings.
Query: Deine Frage wird mit demselben Embedding-Modell in einen Vektor umgewandelt. Dann sucht das System die ähnlichsten Chunks (meist vier bis sechs). Nach dem Filtern über den Similarity-Score wird der passende Text zusammen mit deiner Frage und der Chat-Historie dem LLM-Prompt hinzugefügt. Das LLM liest all das (Systemanweisungen, zurückgeholten Kontext, deine Frage und frühere Nachrichten) und generiert die Antwort.
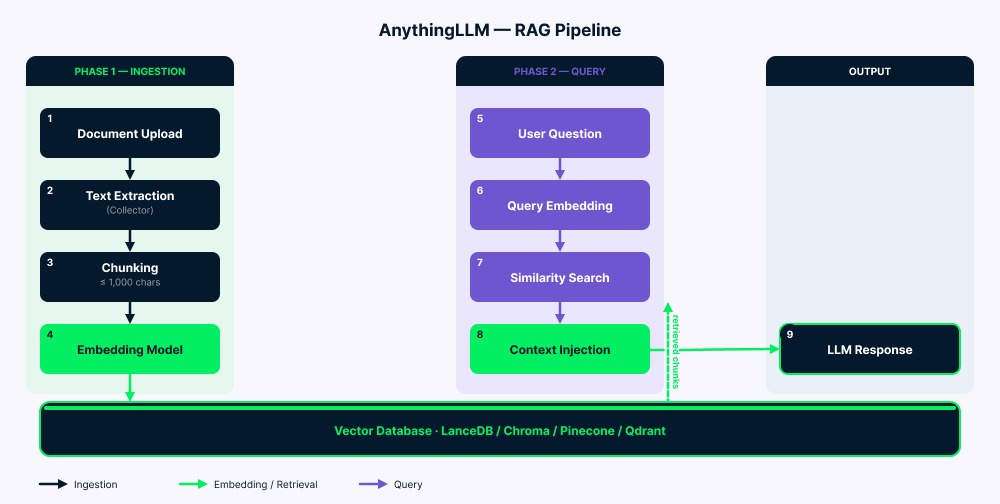
AnythingLLM RAG-Pipeline Architekturüberblick. Bild: Autor.
Wie du in den FAQs siehst, ist AnythingLLM leichtgewichtig: etwa 2 GB RAM, eine 2-Core-CPU und rund 5 GB Speicher. Ein lokales LLM parallel dazu braucht mehr (ein 7B-Modell benötigt typischerweise 8 GB+ RAM/VRAM). Für dieses Tutorial nutze ich ein 3B-Modell, das auf schwächerer Hardware läuft. Stelle sicher, dass Docker installiert und gestartet ist. Windows-Nutzer brauchen zusätzlich WSL.
Lade Ollama von ollama.com/download herunter und ziehe dann ein Chat-Modell und ein Embedding-Modell:
ollama pull llama3.2:3b
ollama pull nomic-embed-text
ollama serveIch nutze llama3.2:3b, weil es auf Maschinen mit wenig VRAM gut läuft (z. B. eine RTX 3050 mit 6 GB). Für bessere Qualität probiere llama3.2:8b oder deepseek-r1:7b, falls deine Hardware das hergibt. Weitere Modelloptionen findest du in unserem Guide zum lokalen Ausführen von LLMs.
mkdir anythingllm-setup && cd anythingllm-setup
touch .envErstelle docker-compose.yml:
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
cap_add:
- SYS_ADMIN
volumes:
- anythingllm_storage:/app/server/storage
- ./.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
anythingllm_storage:Ein paar Hinweise zu dieser Konfiguration. Das Flag cap_add: SYS_ADMIN ist für den integrierten PuppeteerJS-Web-Scraper nötig, der einen sandboxed Chromium-Browser verwendet.
Die Zeile extra_hosts löst das häufigste Docker-Netzwerkproblem: Sie ermöglicht dem Container den Zugriff auf Ollama, das auf deinem Host läuft. Ohne dies schlagen Verbindungen zu localhost:11434 aus dem Container fehl, da Docker-Container einen eigenen Netzwerk-Namespace haben.
Ich nutze ein benanntes Docker-Volume (anythingllm_storage) statt eines Bind-Mounts für bessere Kompatibilität über Plattformen hinweg, besonders auf Windows und macOS, wo Berechtigungen bei Bind-Mounts problematisch sein können.
Warte etwa 30 Sekunden, bis der Container initialisiert ist, und öffne dann http://localhost:3001. Du siehst den Ersteinrichtungsassistenten. Führe vorher diesen Befehl aus:
docker compose up -d
AnythingLLM Ersteinrichtungsassistent unter Docker. Bild: Autor.
Wähle im Setup-Assistenten Ollama sowohl als LLM- als auch als Embedding-Anbieter, setze die Base-URL auf http://host.docker.internal:11434, nimm llama3.2:3b als Chat-Modell und nomic-embed-text als Embedder. Lass LanceDB als Standard-Vektordatenbank aktiviert.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
