
Corso
Comprendere l'intelligenza artificiale
2 h
409.2K
Una domanda comune nel mondo dell’AI self-hosted è come chattare con documenti privati senza inviarli a un’API cloud.
AnythingLLM è una risposta diffusa. Gestisce tutto (upload dei documenti, embedding, ricerca e chat) in un’unica interfaccia e si collega a un’ampia gamma di provider LLM. Ti permette di creare workflow di AI privati senza dipendere da servizi cloud.
In questa guida ti spiego cos’è AnythingLLM, ne illustro l’architettura, ti mostro come installarlo con Docker e Ollama e ti mostro una pipeline Retrieval-Augmented Generation (RAG) funzionante. Lo confronterò anche con Open WebUI e ChatGPT.
AnythingLLM è un’applicazione open-source sviluppata da Mintplex Labs sotto licenza MIT. Ha una community attiva su GitHub, rilasci frequenti ed è ampiamente utilizzata nello spazio AI self-hosted.
Cosa fa in pratica: trasforma i tuoi documenti in contesto che un large language model (LLM) può utilizzare durante le conversazioni. Carichi i file, il sistema li elabora e li memorizza, e poi l’LLM può rispondere alle domande basandosi sui tuoi dati. Il progetto è cresciuto rapidamente, con una community Discord attiva e aggiornamenti mensili che aggiungono nuovi provider LLM e funzionalità.
Due cose da capire subito. Primo: AnythingLLM non è di per sé un modello. È un ponte che ti collega a provider LLM esterni, sia locali (come Ollama) che cloud (come OpenAI o Anthropic).
Secondo: la piattaforma organizza tutto in workspace. Pensali come stanze separate per progetti diversi. Ogni workspace ha i propri documenti e conversazioni che restano isolate, a meno che tu non configuri esplicitamente la condivisione.
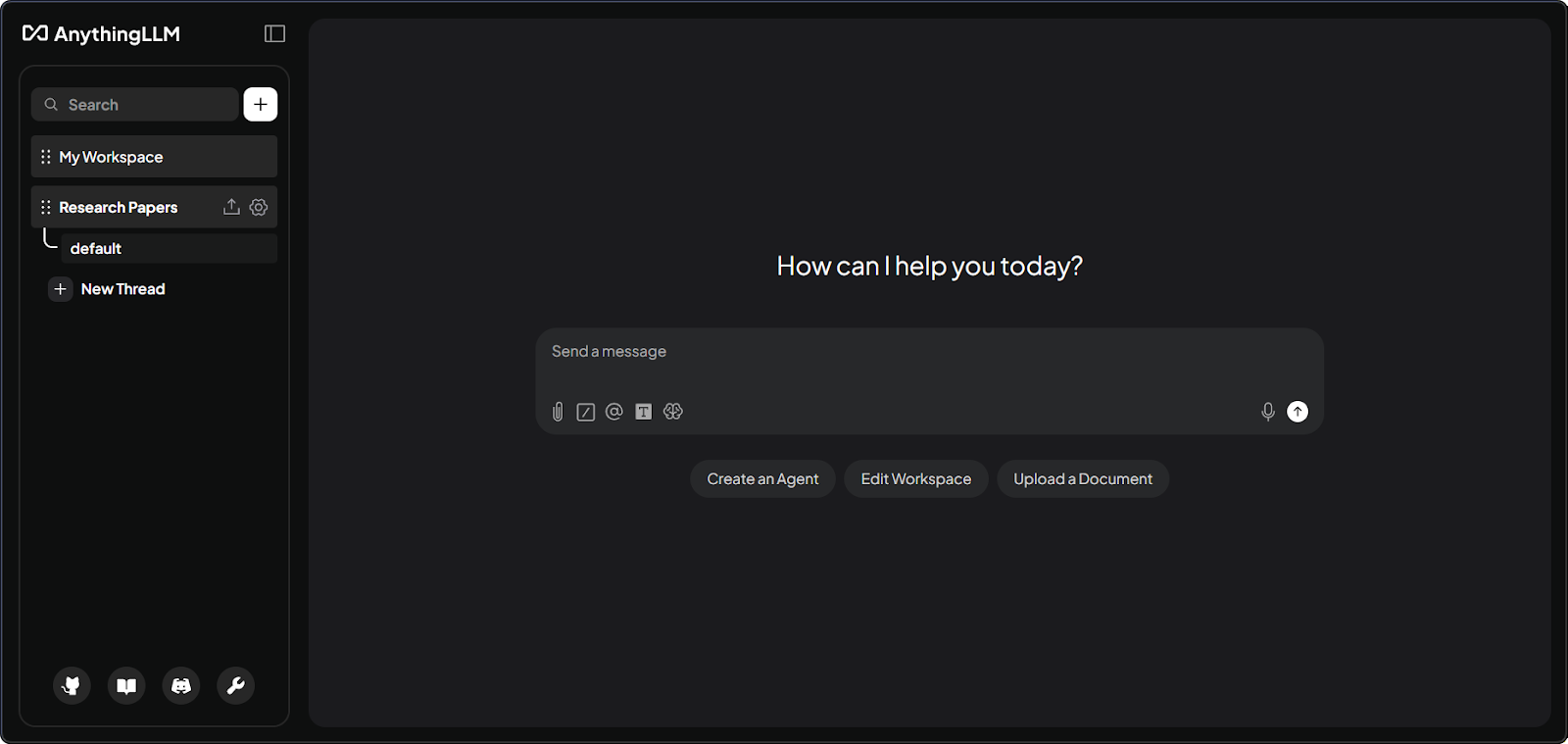
Interfaccia del workspace di AnythingLLM con documenti. Immagine dell’autore.
L’app desktop (macOS, Windows, Linux) è pensata per singoli utenti che eseguono tutto in locale. Include un motore LLM integrato, un embedder basato su CPU e LanceDB in bundle. Installazione in un clic, nessuna configurazione necessaria.
La versione Docker è pensata per team e server. Aggiunge un controllo degli accessi completo con ruoli Admin, Manager e Default, oltre a widget di chat incorporabili per siti web e white-labeling. Se ti serve accesso di team o widget di chat pubblici, Docker è l’unica opzione.
|
Funzionalità |
Desktop |
Docker |
|
Supporto multi-utente |
No |
Sì (ruoli Admin, Manager, Default) |
|
Motore LLM integrato |
Sì |
No (collegati a provider esterni) |
|
Widget di chat incorporabili |
No |
Sì |
|
White-labeling |
No |
Sì |
|
Complessità di setup |
Installazione in un clic |
Richiede conoscenze di Docker |
Ora che sai cos’è AnythingLLM e come scegliere tra Desktop e Docker, vediamo le funzionalità che lo rendono utile per workflow di AI basati sui documenti.
Funziona con PDF, DOCX, TXT, Markdown, CSV, XLSX, PPTX, HTML, oltre 50 tipi di file di codice e file audio (usando la trascrizione Whisper). Puoi anche importare contenuti direttamente da repository GitHub, transcript YouTube, pagine Confluence e siti web tramite lo scraper integrato.
LanceDB è integrato e non richiede setup. Se ti servono funzionalità enterprise, puoi passare a Chroma, Milvus, Pinecone, Qdrant, Weaviate, Zilliz, AstraDB o PGVector.
Supporta un’ampia gamma di provider, tra cui Ollama, LM Studio, OpenAI, Anthropic, Azure OpenAI, Google Gemini, AWS Bedrock, Groq e DeepSeek. Scegli i modelli per workspace, così un workspace può usare un modello locale di Ollama per dati sensibili mentre un altro usa GPT-4o tramite OpenAI.
Digita @agent in qualsiasi chat per attivare il builder di agent no-code. Include skill integrate per cercare nei documenti, riassumere e fare web scraping. Agent Flows ti offre una canvas visuale per concatenare chiamate API, istruzioni LLM e operazioni sui file. Supporta anche il Model Context Protocol (MCP) per collegare strumenti esterni.
La developer API è disponibile su /api/docs (documentazione Swagger). Puoi gestire i workspace in modo programmatico, incorporare documenti e inviare messaggi in chat.
L’applicazione ha tre parti: il frontend (React/ViteJS) fornisce l’interfaccia con cui interagisci. Il server (backend Express) gestisce tutte le interazioni con gli LLM, il lavoro sul database vettoriale e le richieste API. Usa SQLite per memorizzare la configurazione. Il collector è un servizio separato che esegue il parsing e l’elaborazione dei documenti caricati. Quando carichi un PDF, il collector estrae il testo e poi il server lo segmenta, lo embedded e lo memorizza.
La pipeline funziona in due fasi.
Ingestione: i tuoi documenti arrivano al collector, che estrae il testo. Il server poi divide questo testo in chunk (fino a 1.000 caratteri con una piccola sovrapposizione per mantenere il contesto). Ogni chunk viene convertito in un vettore dal modello di embedding e quindi salvato nel database vettoriale. Una cartella vector-cache/ riduce in molti casi re-embedding inutili.
Query: la tua domanda viene convertita in un vettore usando lo stesso modello di embedding. Il sistema cerca quindi i chunk più simili (di solito da quattro a sei). Dopo il filtraggio per punteggio di similarità, il testo corrispondente viene aggiunto al prompt dell’LLM insieme alla tua domanda e alla cronologia della chat. L’LLM legge tutto (istruzioni di sistema, contesto recuperato, tua domanda e messaggi precedenti) e genera la risposta.
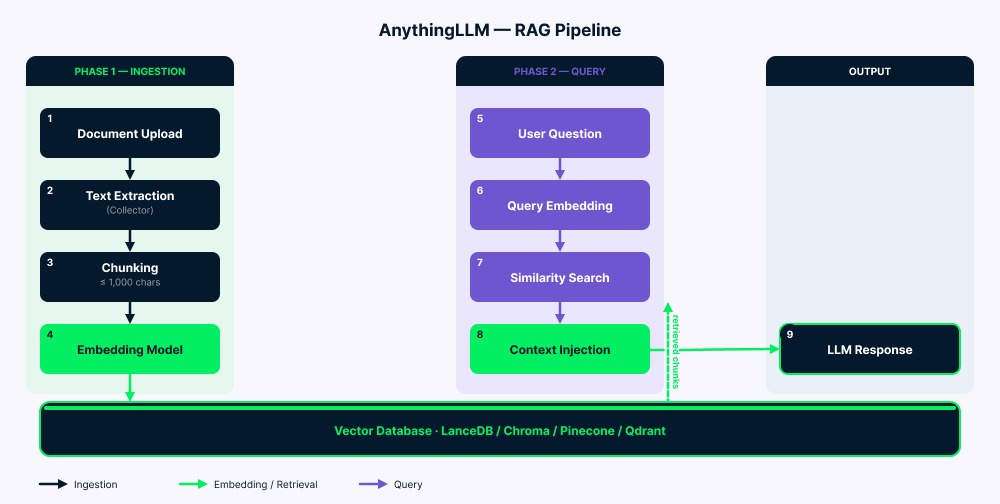
Panoramica dell’architettura della pipeline RAG di AnythingLLM. Immagine dell’autore.
Come vedrai nelle FAQ, AnythingLLM è leggero: circa 2 GB di RAM, una CPU a 2 core e circa 5 GB di storage. Eseguire un LLM locale insieme ad esso richiede di più (un modello 7B tipicamente necessita di 8 GB+ di RAM/VRAM). Per questo tutorial uso un modello 3B che funziona su hardware limitato. Assicurati che Docker sia installato e in esecuzione prima di iniziare. Gli utenti Windows necessitano anche di WSL.
Scarica Ollama da ollama.com/download, poi scarica un modello di chat e un modello di embedding:
ollama pull llama3.2:3b
ollama pull nomic-embed-text
ollama serveUso llama3.2:3b perché gira bene su macchine con VRAM limitata (come una RTX 3050 con 6 GB). Per una qualità migliore, prova llama3.2:8b o deepseek-r1:7b se l’hardware lo consente. Dai un’occhiata alla nostra guida su eseguire LLM in locale per ulteriori opzioni di modelli.
mkdir anythingllm-setup && cd anythingllm-setup
touch .envCrea docker-compose.yml:
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
cap_add:
- SYS_ADMIN
volumes:
- anythingllm_storage:/app/server/storage
- ./.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
anythingllm_storage:Alcune note su questa configurazione. Il flag cap_add: SYS_ADMIN è richiesto per lo scraper web integrato basato su PuppeteerJS, che usa un browser Chromium in sandbox.
La riga extra_hosts risolve il problema di networking Docker più comune: consente al container di raggiungere Ollama in esecuzione sulla tua macchina host. Senza questo, qualsiasi tentativo di connettersi a localhost:11434 dall’interno del container fallirà perché i container Docker hanno il proprio namespace di rete.
Uso un volume Docker nominato (anythingllm_storage) invece di un bind mount per una migliore compatibilità cross-platform, soprattutto su Windows e macOS, dove i permessi dei bind mount possono creare problemi.
Attendi circa 30 secondi per l’inizializzazione del container, poi apri http://localhost:3001. Vedrai la procedura guidata di primo avvio. Ma prima, esegui questo comando:
docker compose up -d
Procedura guidata iniziale di AnythingLLM su Docker. Immagine dell’autore.
Durante la procedura guidata, seleziona Ollama sia come LLM che come provider di embedding, imposta la base URL su http://host.docker.internal:11434, scegli llama3.2:3b come modello di chat e nomic-embed-text come embedder. Mantieni LanceDB come database vettoriale predefinito.
Impara con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

