
Course
Understanding Artificial Intelligence
2 hr
405.2K
A common question in the self-hosted AI space is how to chat with private documents without sending them to a cloud API.
AnythingLLM is a popular answer. It handles everything (document upload, embedding, search, and chat) in one interface and connects to a wide range of LLM providers. It lets you build private AI workflows without depending on cloud services.
In this guide, I will explain what AnythingLLM is, walk through its architecture, show you how to install it with Docker and Ollama, and demonstrate a working Retrieval-Augmented Generation (RAG) pipeline. I will also compare it against Open WebUI and ChatGPT.
AnythingLLM is an open-source application built by Mintplex Labs under the MIT license. It has an active GitHub community and frequent releases, and is widely used in the self-hosted AI space.
Here's what it does: it turns your documents into context that a large language model (LLM) can use during conversations. You upload files, the system processes and stores them, and then the LLM can answer questions based on your data. The project has grown fast, with an active Discord community and monthly updates that add new LLM providers and features.
Two things to understand upfront. First, AnythingLLM is not a model itself. It's a bridge connecting you to external LLM providers, whether local (like Ollama) or cloud-based (like OpenAI or Anthropic).
Second, the platform organizes everything into workspaces. Think of these as separate rooms for different projects. Each workspace has its own documents and conversations that stay isolated unless you explicitly configure them to share.
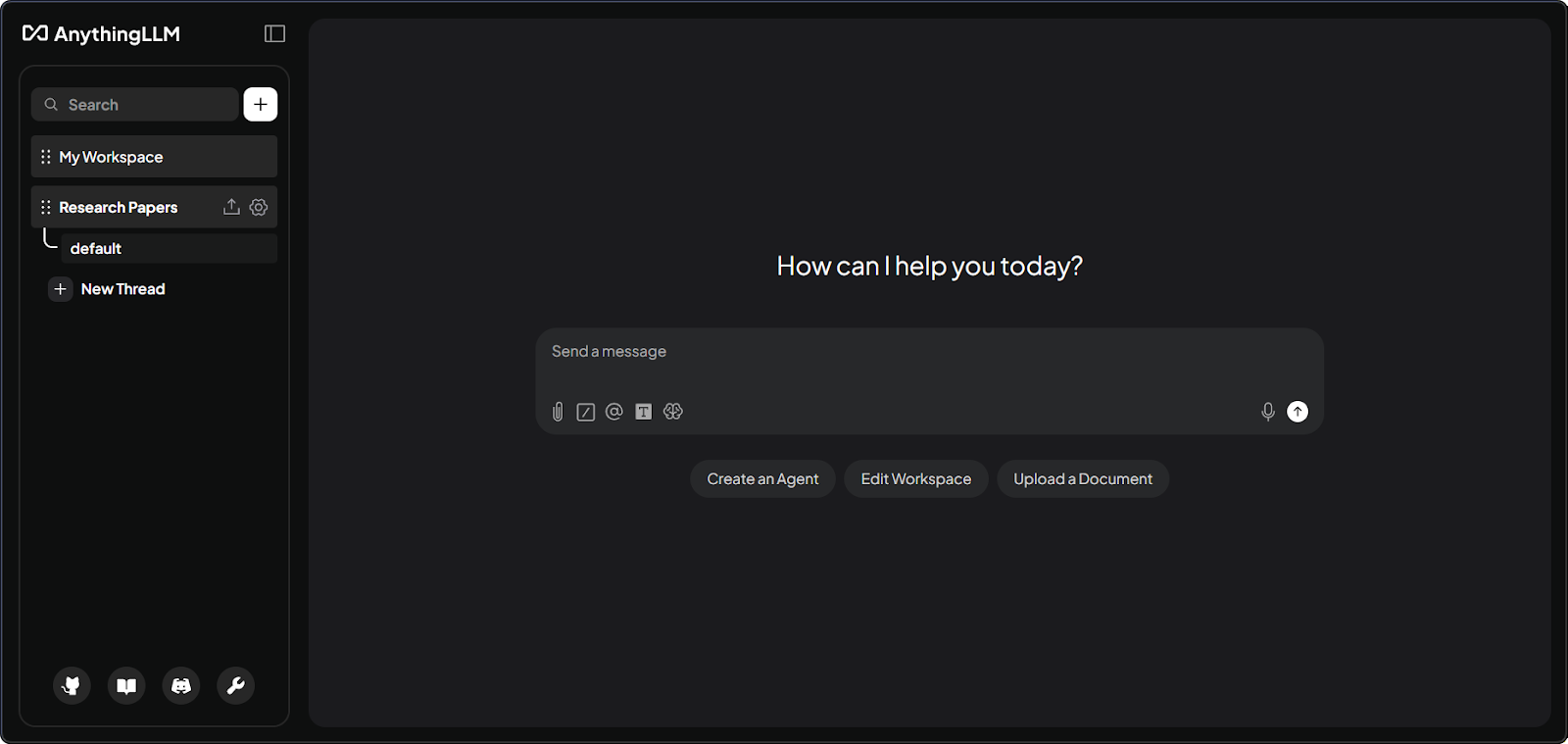
AnythingLLM workspace interface with documents. Image by Author.
The desktop app (macOS, Windows, Linux) is for single users running everything locally. It comes with a built-in LLM engine, CPU-based embedder, and bundled LanceDB. One-click install, no configuration needed.
The Docker version is built for teams and servers. It adds proper access control with Admin, Manager, and Default roles, plus embeddable chat widgets for websites and white-labeling. If you need team access or public-facing chat widgets, Docker is your only option.
|
Feature |
Desktop |
Docker |
|
Multi-user support |
No |
Yes (Admin, Manager, Default roles) |
|
Built-in LLM engine |
Yes |
No (connect to external providers) |
|
Embeddable chat widgets |
No |
Yes |
|
White-labeling |
No |
Yes |
|
Setup complexity |
One-click install |
Requires Docker knowledge |
Now that you know what AnythingLLM is and how to choose between Desktop and Docker, let's walk through the features that make it useful for document-based AI workflows.
Works with PDF, DOCX, TXT, Markdown, CSV, XLSX, PPTX, HTML, 50+ code file types, and audio files (using Whisper transcription). You can also pull content directly from GitHub repos, YouTube transcripts, Confluence pages, and websites using the built-in scraper.
LanceDB comes built in and needs zero setup. If you need enterprise features, you can switch to Chroma, Milvus, Pinecone, Qdrant, Weaviate, Zilliz, AstraDB, or PGVector.
Supports a wide range of providers, including Ollama, LM Studio, OpenAI, Anthropic, Azure OpenAI, Google Gemini, AWS Bedrock, Groq, and DeepSeek. You pick models per workspace, so one workspace can use a local Ollama model for sensitive stuff while another uses GPT-4o through OpenAI.
Type @agent in any chat to activate the no-code agent builder. It has built-in skills for searching documents, summarization, and web scraping. Agent Flows gives you a visual canvas for chaining together API calls, LLM instructions, and file operations. It also supports Model Context Protocol (MCP) for connecting external tools.
The developer API lives at /api/docs (Swagger docs). You can programmatically manage workspaces, embed documents, and send chat messages.
The application has three parts: the frontend (React/ViteJS) gives you the interface you see and interact with. The server (Express backend) handles all the LLM interactions, vector database work, and API requests. It uses SQLite for storing configuration. The collector is a separate service that parses and processes your uploaded documents. When you upload a PDF, the collector extracts the text, then the server chunks, embeds, and stores it.
The pipeline works in two phases.
Ingestion: Your documents go to the collector, which extracts the text. The server then splits this text into chunks (up to 1,000 characters with a small overlap to keep context). Each chunk gets converted into a vector by the embedding model, then stored in the vector database. A vector-cache/ folder reduces unnecessary re-embedding in many cases.
Query: Your question gets converted into a vector using the same embedding model. Then the system searches for the most similar chunks (usually four to six). After filtering by similarity score, the matching text gets added to the LLM prompt along with your question and chat history. The LLM reads all of this (system instructions, retrieved context, your question, and previous messages) and generates its answer.
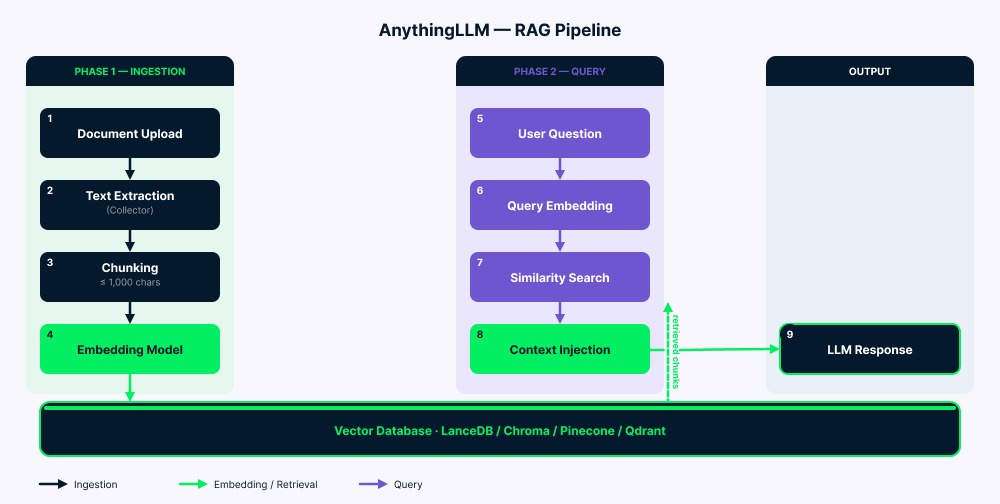
AnythingLLM RAG pipeline architecture overview. Image by Author.
As you'll see in the FAQ, AnythingLLM is lightweight: around 2GB RAM, a 2-core CPU, and about 5GB of storage. Running a local LLM alongside it requires more (a 7B model typically needs 8GB+ RAM/VRAM). For this tutorial, I use a 3B model that works on limited hardware. Make sure Docker is installed and running before starting. Windows users also need WSL.
Download Ollama from ollama.com/download, then pull a chat model and an embedding model:
ollama pull llama3.2:3b
ollama pull nomic-embed-text
ollama serveI use llama3.2:3b because it runs well on machines with limited VRAM (like an RTX 3050 with 6GB). For better quality, try llama3.2:8b or deepseek-r1:7b if your hardware allows. Check out our guide on running LLMs locally for more model options.
mkdir anythingllm-setup && cd anythingllm-setup
touch .envCreate docker-compose.yml:
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
cap_add:
- SYS_ADMIN
volumes:
- anythingllm_storage:/app/server/storage
- ./.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
anythingllm_storage:A few things to note about this configuration. The cap_add: SYS_ADMIN flag is required for the built-in PuppeteerJS web scraper, which uses a sandboxed Chromium browser.
The extra_hosts line solves the most common Docker networking issue: it allows the container to reach Ollama running on your host machine. Without this, any attempt to connect to localhost:11434 from inside the container will fail because Docker containers have their own network namespace.
I use a named Docker volume (anythingllm_storage) instead of a bind mount for better cross-platform compatibility, especially on Windows and macOS, where bind mount permissions can be problematic.
Wait about 30 seconds for the container to initialize, then open http://localhost:3001. You will see the first-run setup wizard. But first, run this command:
docker compose up -d
AnythingLLM initial setup wizard on Docker. Image by Author.
During the setup wizard, select Ollama as both the LLM and embedding provider, set the base URL to http://host.docker.internal:11434, choose llama3.2:3b as the chat model, and nomic-embed-text as the embedder. Keep LanceDB as the default vector database.
Learn with DataCamp
Course
Course
Course
Tutorial
Dario Radečić
Tutorial
Ryan Ong
Tutorial
François Aubry
Tutorial
Bex Tuychiev
Tutorial
François Aubry
Tutorial
Abid Ali Awan