
Curso
Entendendo a inteligência artificial
2 h
408.7K
Uma dúvida comum no universo de IA autogerenciada é como conversar com documentos privados sem enviá-los para uma API na nuvem.
AnythingLLM é uma resposta popular. Ele cuida de tudo (upload de documentos, embedding, busca e chat) em uma única interface e se conecta a uma ampla variedade de provedores de LLM. Assim, você cria fluxos de IA privados sem depender de serviços em nuvem.
Neste guia, vou explicar o que é o AnythingLLM, detalhar sua arquitetura, mostrar como instalar com Docker e Ollama, e demonstrar um pipeline de Retrieval-Augmented Generation (RAG) funcionando. Também vou compará-lo com Open WebUI e ChatGPT.
AnythingLLM é um aplicativo open source criado pela Mintplex Labs sob a licença MIT. Tem uma comunidade ativa no GitHub, lançamentos frequentes e é amplamente usado no ecossistema de IA autogerenciada.
O que ele faz: transforma seus documentos em contexto que um large language model (LLM) pode usar durante as conversas. Você faz upload de arquivos, o sistema processa e armazena, e então o LLM responde com base nos seus dados. O projeto cresceu rápido, com comunidade ativa no Discord e atualizações mensais que adicionam novos provedores e recursos.
Duas coisas importantes desde já. Primeiro: AnythingLLM não é um modelo. Ele é uma ponte para provedores externos de LLM, sejam locais (como o Ollama) ou na nuvem (como OpenAI ou Anthropic).
Segundo: a plataforma organiza tudo em workspaces. Pense neles como salas separadas para projetos diferentes. Cada workspace tem seus próprios documentos e conversas, que ficam isolados a menos que você configure para compartilhar.
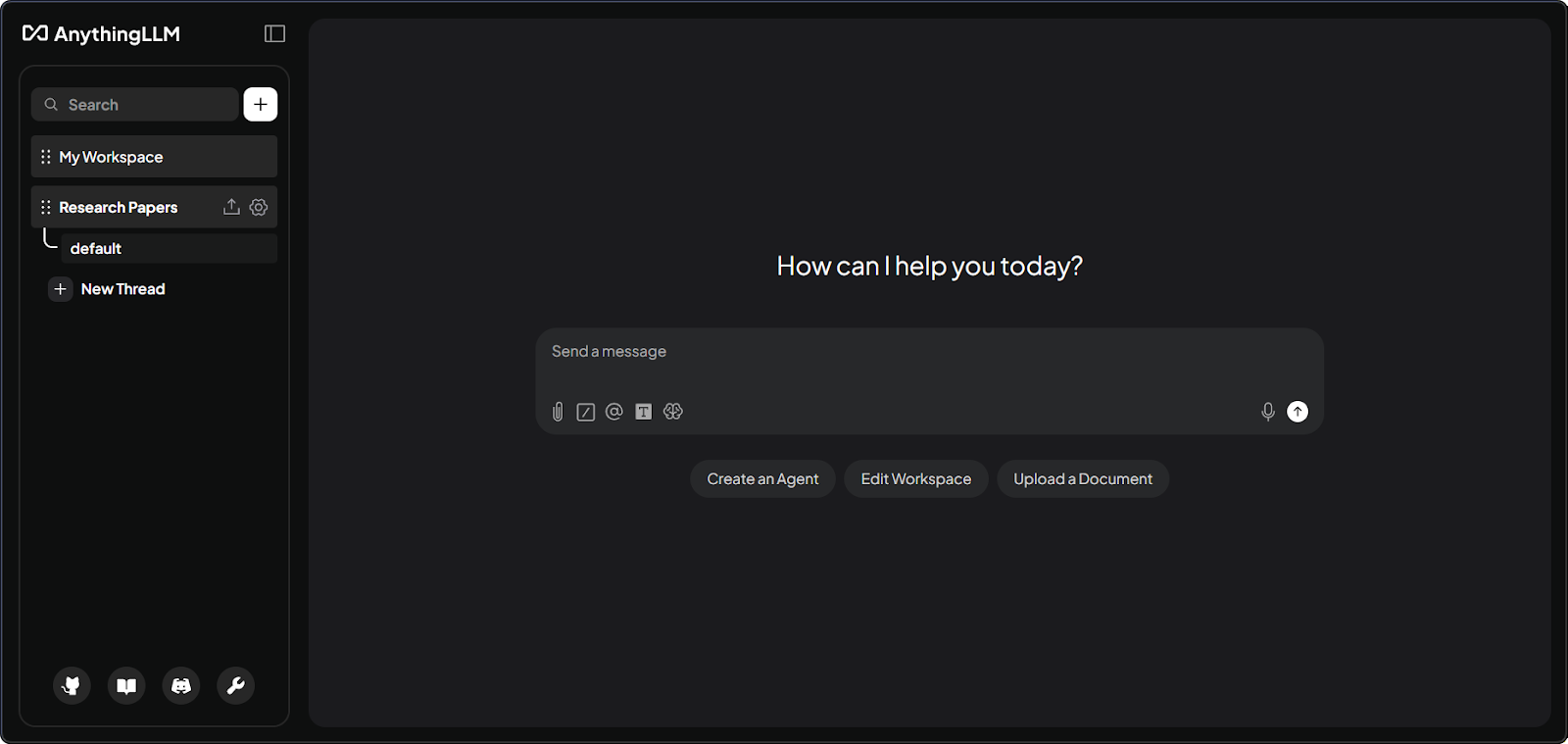
Interface do workspace do AnythingLLM com documentos. Imagem do autor.
O app para desktop (macOS, Windows, Linux) é para um único usuário rodando tudo localmente. Vem com engine de LLM embutido, embedder baseado em CPU e LanceDB incluído. Instalação em um clique, sem configuração.
A versão Docker é feita para times e servidores. Ela adiciona controle de acesso com papéis de Admin, Manager e Default, além de widgets de chat incorporáveis em sites e white-label. Se você precisa de acesso em equipe ou widgets de chat públicos, Docker é a sua única opção.
|
Recurso |
Desktop |
Docker |
|
Suporte multiusuário |
Não |
Sim (papeis Admin, Manager, Default) |
|
Engine de LLM embutido |
Sim |
Não (conecta a provedores externos) |
|
Widgets de chat incorporáveis |
Não |
Sim |
|
White-label |
Não |
Sim |
|
Complexidade de setup |
Instalação em um clique |
Requer conhecimento de Docker |
Agora que você já sabe o que é o AnythingLLM e como escolher entre Desktop e Docker, vamos ver os recursos que tornam a ferramenta útil para fluxos de IA baseados em documentos.
Funciona com PDF, DOCX, TXT, Markdown, CSV, XLSX, PPTX, HTML, mais de 50 tipos de arquivos de código e arquivos de áudio (usando transcrição Whisper). Você também pode puxar conteúdo direto de repositórios do GitHub, transcrições do YouTube, páginas do Confluence e sites usando o scraper embutido.
O LanceDB já vem integrado e não requer configuração. Se precisar de recursos enterprise, dá para trocar para Chroma, Milvus, Pinecone, Qdrant, Weaviate, Zilliz, AstraDB ou PGVector.
Suporta diversos provedores, incluindo Ollama, LM Studio, OpenAI, Anthropic, Azure OpenAI, Google Gemini, AWS Bedrock, Groq e DeepSeek. Você escolhe os modelos por workspace, então um workspace pode usar um modelo local do Ollama para dados sensíveis enquanto outro usa GPT-4o via OpenAI.
Digite @agent em qualquer chat para ativar o construtor de agentes no-code. Ele já traz habilidades para busca em documentos, sumarização e web scraping. O Agent Flows oferece um canvas visual para encadear chamadas de API, instruções para LLM e operações em arquivos. Também há suporte a Model Context Protocol (MCP) para conectar ferramentas externas.
A API para desenvolvedores fica em /api/docs (documentação Swagger). Você pode gerenciar workspaces, incorporar documentos e enviar mensagens de chat programaticamente.
O app tem três partes: o frontend (React/ViteJS) oferece a interface com a qual você interage. O servidor (backend em Express) lida com as interações com LLM, o trabalho no banco vetorial e as requisições de API. Ele usa SQLite para armazenar a configuração. O collector é um serviço separado que faz o parsing e processa os documentos enviados. Quando você faz upload de um PDF, o collector extrai o texto, e então o servidor divide, faz o embedding e armazena.
O pipeline funciona em duas fases.
Ingestão: seus documentos vão para o collector, que extrai o texto. O servidor então divide esse texto em chunks (até 1.000 caracteres, com pequena sobreposição para manter contexto). Cada chunk é convertido em vetor pelo modelo de embedding e armazenado no banco vetorial. A pasta vector-cache/ reduz re-embeddings desnecessários em muitos casos.
Consulta: sua pergunta é convertida em vetor usando o mesmo modelo de embedding. Em seguida, o sistema busca os chunks mais semelhantes (geralmente de quatro a seis). Após filtrar por score de similaridade, o texto correspondente é adicionado ao prompt do LLM junto com sua pergunta e o histórico do chat. O LLM lê tudo isso (instruções do sistema, contexto recuperado, sua pergunta e mensagens anteriores) e gera a resposta.
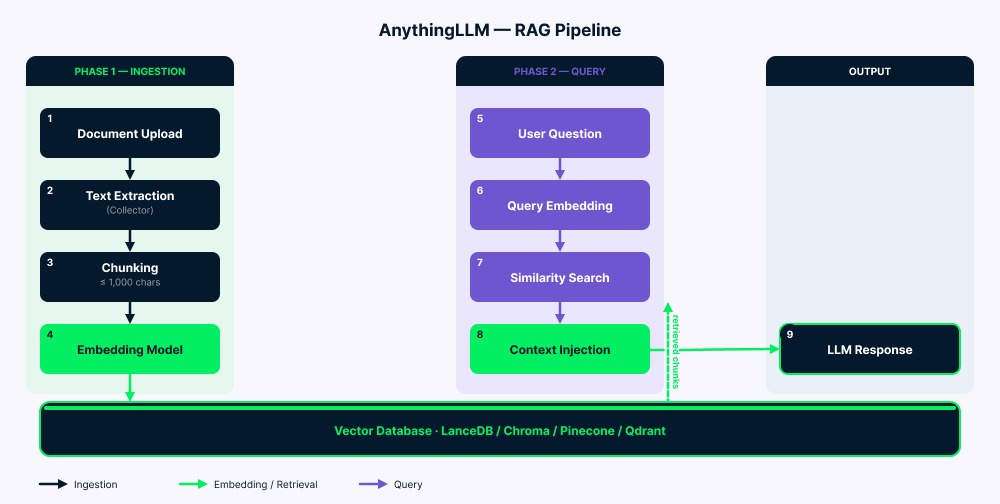
Visão geral da arquitetura do pipeline RAG do AnythingLLM. Imagem do autor.
Como você verá no FAQ, AnythingLLM é leve: cerca de 2 GB de RAM, CPU de 2 núcleos e uns 5 GB de storage. Rodar um LLM local junto dele exige mais (um modelo 7B normalmente precisa de 8 GB+ de RAM/VRAM). Para este tutorial, uso um modelo 3B que funciona em hardware limitado. Certifique-se de ter o Docker instalado e rodando antes de começar. No Windows, também é preciso WSL.
Baixe o Ollama em ollama.com/download e depois puxe um modelo de chat e um de embedding:
ollama pull llama3.2:3b
ollama pull nomic-embed-text
ollama serveEu uso llama3.2:3b porque roda bem em máquinas com VRAM limitada (como uma RTX 3050 com 6 GB). Para melhor qualidade, tente llama3.2:8b ou deepseek-r1:7b se o seu hardware permitir. Confira nosso guia sobre rodar LLMs localmente para mais opções de modelos.
mkdir anythingllm-setup && cd anythingllm-setup
touch .envCrie o docker-compose.yml:
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
cap_add:
- SYS_ADMIN
volumes:
- anythingllm_storage:/app/server/storage
- ./.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
anythingllm_storage:Alguns pontos sobre essa configuração. A flag cap_add: SYS_ADMIN é necessária para o scraper web embutido em PuppeteerJS, que usa um Chromium em sandbox.
A linha extra_hosts resolve o problema de rede mais comum no Docker: permite que o contêiner acesse o Ollama rodando na máquina host. Sem isso, qualquer tentativa de conectar a localhost:11434 de dentro do contêiner vai falhar, pois contêineres Docker têm seu próprio namespace de rede.
Uso um volume nomeado do Docker (anythingllm_storage) em vez de bind mount para melhor compatibilidade entre plataformas, especialmente no Windows e macOS, onde permissões de bind mount podem dar dor de cabeça.
Espere cerca de 30 segundos para o contêiner inicializar e abra http://localhost:3001. Você verá o assistente de primeira execução. Mas antes, rode este comando:
docker compose up -d
Assistente de setup inicial do AnythingLLM no Docker. Imagem do autor.
Durante o assistente, selecione Ollama como provedor de LLM e de embedding, defina a base URL como http://host.docker.internal:11434, escolha llama3.2:3b como modelo de chat e nomic-embed-text como embedder. Mantenha o LanceDB como banco vetorial padrão.
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Ryan Ong
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita


