
Courses
Hiểu về Trí tuệ Nhân tạo
2 giờ
409.2K
Một câu hỏi thường gặp trong lĩnh vực AI tự triển khai là làm thế nào để trò chuyện với các tài liệu riêng tư mà không cần gửi chúng đến API đám mây.
AnythingLLM là một câu trả lời phổ biến. Công cụ này xử lý mọi thứ (tải tài liệu, nhúng, tìm kiếm và trò chuyện) trong một giao diện và kết nối với nhiều nhà cung cấp LLM. Nó cho phép bạn xây dựng các quy trình AI riêng tư mà không phụ thuộc vào dịch vụ đám mây.
Trong hướng dẫn này, tôi sẽ giải thích AnythingLLM là gì, đi qua kiến trúc của nó, chỉ bạn cách cài đặt bằng Docker và Ollama, và trình diễn một pipeline Retrieval-Augmented Generation (RAG) đang hoạt động. Tôi cũng sẽ so sánh nó với Open WebUI và ChatGPT.
AnythingLLM là một ứng dụng mã nguồn mở do Mintplex Labs xây dựng theo giấy phép MIT. Dự án có cộng đồng GitHub năng động, phát hành thường xuyên và được sử dụng rộng rãi trong lĩnh vực AI tự triển khai.
Nó làm gì: nó biến tài liệu của bạn thành ngữ cảnh mà một mô hình ngôn ngữ lớn (LLM) có thể sử dụng trong hội thoại. Bạn tải tệp lên, hệ thống xử lý và lưu trữ chúng, sau đó LLM có thể trả lời câu hỏi dựa trên dữ liệu của bạn. Dự án phát triển nhanh, có cộng đồng Discord sôi động và các bản cập nhật hàng tháng bổ sung nhà cung cấp LLM và tính năng mới.
Có hai điều cần hiểu trước. Thứ nhất, AnythingLLM không phải là một mô hình. Nó là cầu nối kết nối bạn với các nhà cung cấp LLM bên ngoài, dù là cục bộ (như Ollama) hay trên đám mây (như OpenAI hoặc Anthropic).
Thứ hai, nền tảng tổ chức mọi thứ thành workspace. Hãy coi đây là các phòng riêng cho từng dự án. Mỗi workspace có tài liệu và hội thoại riêng, được cách ly trừ khi bạn cấu hình để chia sẻ.
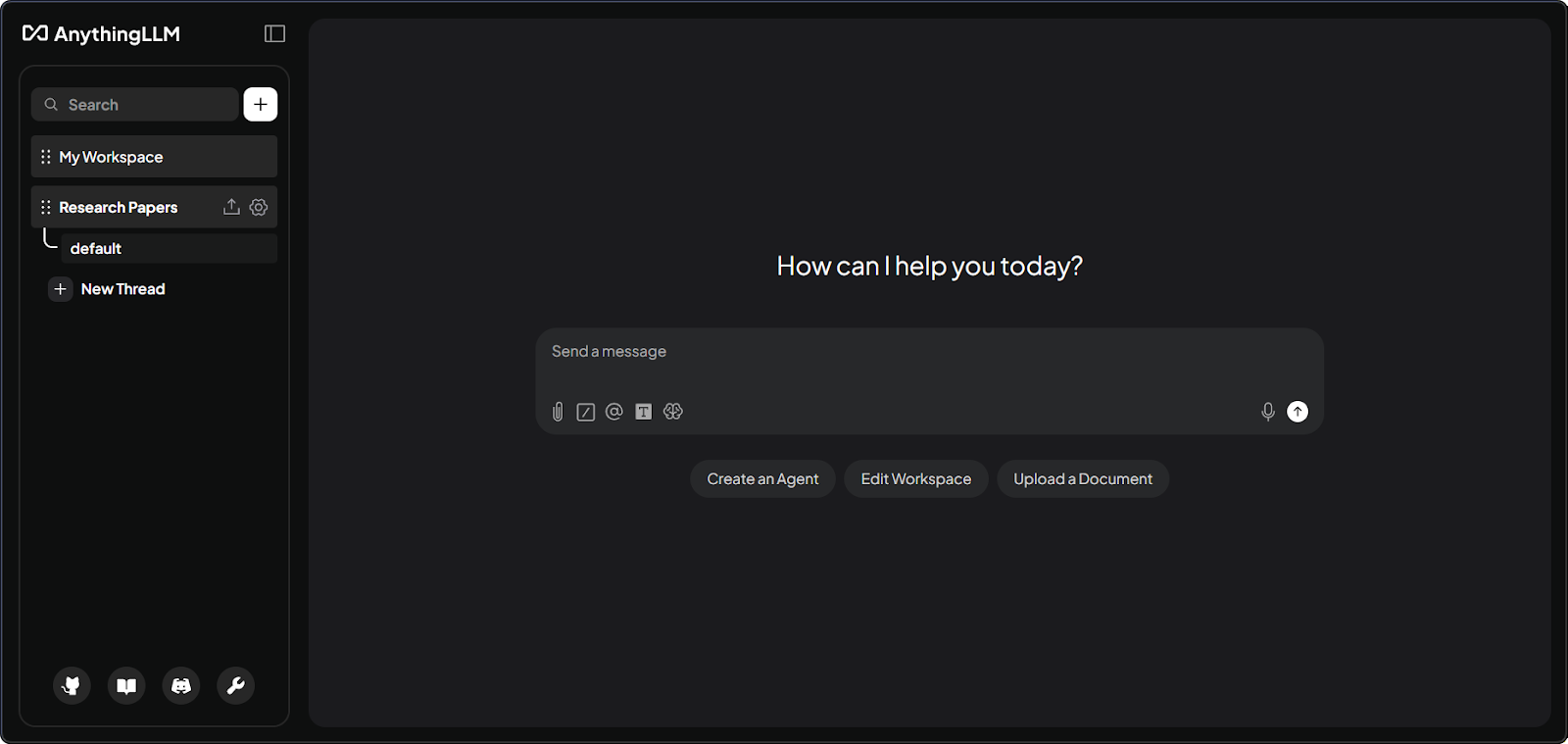
Giao diện workspace AnythingLLM với tài liệu. Ảnh: Tác giả.
Ứng dụng desktop (macOS, Windows, Linux) dành cho người dùng đơn chạy mọi thứ cục bộ. Nó đi kèm động cơ LLM tích hợp, bộ embedder chạy trên CPU và LanceDB đóng gói sẵn. Cài đặt một cú nhấp, không cần cấu hình.
Phiên bản Docker được xây cho đội nhóm và máy chủ. Nó bổ sung kiểm soát truy cập đúng nghĩa với vai trò Admin, Manager và Default, cùng widget chat có thể nhúng cho website và gắn nhãn trắng. Nếu bạn cần truy cập theo nhóm hoặc widget chat hướng công chúng, Docker là lựa chọn duy nhất.
|
Tính năng |
Desktop |
Docker |
|
Hỗ trợ đa người dùng |
Không |
Có (vai trò Admin, Manager, Default) |
|
Động cơ LLM tích hợp |
Có |
Không (kết nối nhà cung cấp bên ngoài) |
|
Widget chat có thể nhúng |
Không |
Có |
|
Gắn nhãn trắng |
Không |
Có |
|
Độ phức tạp thiết lập |
Cài đặt một cú nhấp |
Cần kiến thức Docker |
Giờ bạn đã biết AnythingLLM là gì và cách chọn giữa Desktop và Docker, cùng đi qua các tính năng khiến nó hữu ích cho quy trình AI dựa trên tài liệu.
Hoạt động với PDF, DOCX, TXT, Markdown, CSV, XLSX, PPTX, HTML, hơn 50 loại tệp mã và tệp âm thanh (dùng chuyển âm Whisper). Bạn cũng có thể kéo nội dung trực tiếp từ repo GitHub, bản chép YouTube, trang Confluence và website bằng trình thu thập tích hợp.
LanceDB được tích hợp sẵn và không cần thiết lập. Nếu cần tính năng doanh nghiệp, bạn có thể chuyển sang Chroma, Milvus, Pinecone, Qdrant, Weaviate, Zilliz, AstraDB hoặc PGVector.
Hỗ trợ nhiều nhà cung cấp, gồm Ollama, LM Studio, OpenAI, Anthropic, Azure OpenAI, Google Gemini, AWS Bedrock, Groq và DeepSeek. Bạn chọn mô hình theo từng workspace, vì vậy một workspace có thể dùng mô hình Ollama cục bộ cho nội dung nhạy cảm trong khi workspace khác dùng GPT-4o qua OpenAI.
Gõ @agent trong bất kỳ cuộc chat nào để kích hoạt trình dựng tác tử không cần mã. Nó có sẵn kỹ năng tìm kiếm tài liệu, tóm tắt và thu thập web. Agent Flows cung cấp canvas trực quan để chuỗi các lời gọi API, hướng dẫn LLM và thao tác tệp. Công cụ cũng hỗ trợ Model Context Protocol (MCP) để kết nối công cụ bên ngoài.
API cho nhà phát triển nằm tại /api/docs (tài liệu Swagger). Bạn có thể quản lý workspace, nhúng tài liệu và gửi tin nhắn chat bằng lập trình.
Ứng dụng có ba phần: frontend (React/ViteJS) cung cấp giao diện bạn thấy và tương tác. Server (backend Express) xử lý toàn bộ tương tác LLM, công việc cơ sở dữ liệu vector và yêu cầu API. Nó dùng SQLite để lưu cấu hình. Collector là dịch vụ riêng phân tích và xử lý tài liệu bạn tải lên. Khi bạn tải PDF, collector trích xuất văn bản, sau đó server chia nhỏ, nhúng và lưu trữ nó.
Pipeline hoạt động qua hai giai đoạn.
Ingestion: Tài liệu của bạn đến collector để trích xuất văn bản. Server sau đó chia văn bản thành các đoạn (tối đa 1.000 ký tự với chút chồng lấn để giữ ngữ cảnh). Mỗi đoạn được chuyển thành vector bởi mô hình embedding, rồi lưu vào cơ sở dữ liệu vector. Thư mục vector-cache/ giảm việc nhúng lại không cần thiết trong nhiều trường hợp.
Truy vấn: Câu hỏi của bạn được chuyển thành vector bằng cùng mô hình embedding. Hệ thống sau đó tìm các đoạn tương đồng nhất (thường bốn đến sáu). Sau khi lọc theo điểm tương đồng, văn bản khớp được thêm vào prompt của LLM cùng câu hỏi và lịch sử chat. LLM đọc tất cả (hướng dẫn hệ thống, ngữ cảnh truy xuất, câu hỏi của bạn và tin nhắn trước đó) và tạo câu trả lời.
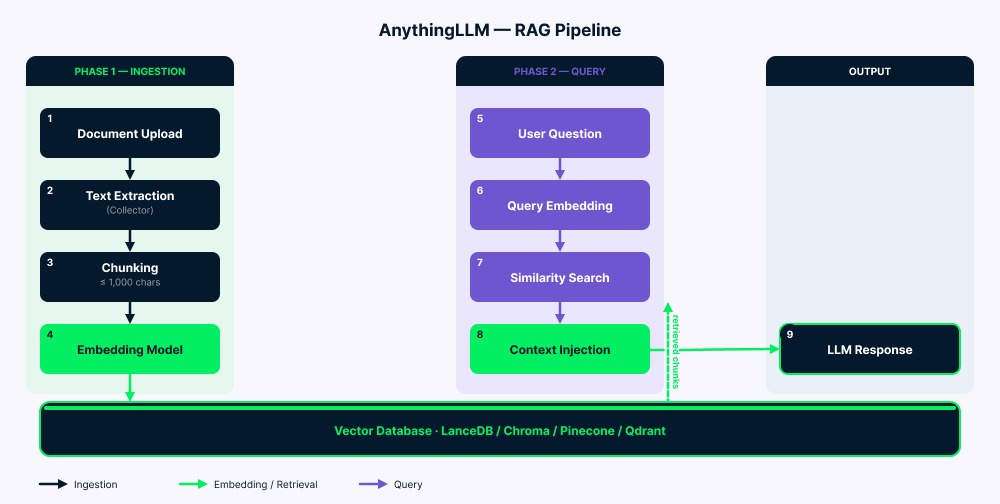
Tổng quan kiến trúc pipeline RAG của AnythingLLM. Ảnh: Tác giả.
Như bạn sẽ thấy trong mục FAQ, AnythingLLM khá nhẹ: khoảng 2GB RAM, CPU 2 nhân và khoảng 5GB lưu trữ. Chạy một LLM cục bộ song song sẽ cần nhiều hơn (mô hình 7B thường cần 8GB+ RAM/VRAM). Trong hướng dẫn này, tôi dùng mô hình 3B phù hợp phần cứng hạn chế. Hãy đảm bảo Docker đã cài và chạy trước khi bắt đầu. Người dùng Windows cần WSL.
Tải Ollama từ ollama.com/download, sau đó kéo một mô hình chat và một mô hình embedding:
ollama pull llama3.2:3b
ollama pull nomic-embed-text
ollama serveTôi dùng llama3.2:3b vì nó chạy tốt trên máy có VRAM hạn chế (như RTX 3050 với 6GB). Để có chất lượng tốt hơn, hãy thử llama3.2:8b hoặc deepseek-r1:7b nếu phần cứng cho phép. Xem thêm hướng dẫn về chạy LLM cục bộ để có thêm lựa chọn mô hình.
mkdir anythingllm-setup && cd anythingllm-setup
touch .envTạo docker-compose.yml:
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
cap_add:
- SYS_ADMIN
volumes:
- anythingllm_storage:/app/server/storage
- ./.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
volumes:
anythingllm_storage:Một vài điểm cần lưu ý về cấu hình này. Cờ cap_add: SYS_ADMIN là bắt buộc cho trình thu thập web PuppeteerJS tích hợp, sử dụng trình duyệt Chromium trong sandbox.
Dòng extra_hosts giải quyết vấn đề mạng Docker phổ biến nhất: cho phép container truy cập Ollama chạy trên máy chủ của bạn. Nếu không có dòng này, mọi nỗ lực kết nối đến localhost:11434 từ trong container sẽ thất bại vì các container có namespace mạng riêng.
Tôi dùng volume Docker có tên (anythingllm_storage) thay vì bind mount để tăng tương thích đa nền tảng, đặc biệt trên Windows và macOS, nơi quyền bind mount có thể gây vấn đề.
Chờ khoảng 30 giây để container khởi tạo, sau đó mở http://localhost:3001. Bạn sẽ thấy trình hướng dẫn thiết lập lần đầu. Nhưng trước tiên, chạy lệnh này:
docker compose up -d
Trình hướng dẫn thiết lập ban đầu của AnythingLLM trên Docker. Ảnh: Tác giả.
Trong trình hướng dẫn, chọn Ollama làm cả nhà cung cấp LLM và embedding, đặt base URL là http://host.docker.internal:11434, chọn llama3.2:3b làm mô hình chat, và nomic-embed-text làm embedder. Giữ LanceDB là cơ sở dữ liệu vector mặc định.
Học cùng DataCamp
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút