
Leerpad
KNIME-basisprincipes
17 Hr
De nieuwe enterprise-AI-paradox is deze: hoe meer we acties delegeren aan AI-agents, hoe meer we onze eigen zeggenschap verliezen. In het agentische tijdperk zijn beoordeling en vertrouwen, niet generatie, de bottleneck.
We zijn gewend geraakt aan AI-systemen die vooral ons eigen menselijk oordeel ondersteunen. In veel gevallen zijn we er ook aan gewend geraakt dat deze systemen ons menselijk oordeel en onze biases bevestigen, en die niet wezenlijk ter discussie stellen. Ze genereren tekst, vatten informatie samen of geven aanbevelingen.
Toch bleef de mens de beslisser en goedkeurder.
AI-agents hebben dat veranderd. Agentische systemen genereren niet alleen suggesties, maar zijn ontworpen om te plannen, te beslissen en te handelen binnen complexe organisatorische ecosystemen.
Ze starten workflows, roepen API's aan, verplaatsen geld en werken dossiers bij. Ze initiëren processen zonder per se op menselijke bevestiging te wachten. Dit verandert het risicolandschap voor bedrijven.
Het probleem is dat wanneer agentische systemen handelen, de gevolgen kostbaar kunnen zijn. Als een agent een inkoopfout van $300k maakt, is “de tool nam de beslissing” geen houdbare verdediging meer. Het verlies voor het bedrijf is reëel, en iemand moet verantwoordelijk worden gehouden. Je verantwoordelijkheid verdwijnt niet alleen omdat de agent handelde.
Ondernemingen willen de snelheid, schaal en efficiëntie van autonome agents, maar verantwoordelijkheid laat zich niet wegautomatiseren. Acties delegeren aan een agent betekent niet dat je verantwoordelijkheid delegeert.
De centrale vraag is: hoe schalen we het gebruik van agentische AI zonder zeggenschap op te geven?
Om dat te beantwoorden, moeten we onderscheid maken tussen assisterende AI en agentische AI.
Het onderscheid zit in de mate van controle. In assisterende systemen ligt de zeggenschap duidelijk bij de mens. Autoriteit en verantwoordelijkheid vallen eerder samen, waarbij mensen beslissen en systemen ondersteunen. Maar in agentische systemen handelt het systeem, terwijl de uiteindelijke verantwoordelijkheid bij de mens blijft.
Daar verergert de paradox.
Naarmate autonomie toeneemt, wordt voortdurende menselijke controle (de human-in-the-loop) onpraktisch. Maar minder toezicht vergroot de blootstelling aan risico's, zoals beleidsovertredingen, fouten en onbedoelde gevolgen. En agents te strak inperken maakt autonomie theoretisch en we missen schaal en efficiëntie.
Het ontbreekt niet aan leveranciers die grootschalige automatisering beloven. Agents maken plannen, nemen beslissingen en handelen sneller dan welk menselijk team dan ook.
Maar wanneer agents handelen, krijgen bedrijven een nieuwe vraag: hoe weten we dat die acties correct, veilig en in lijn met ons beleid zijn?
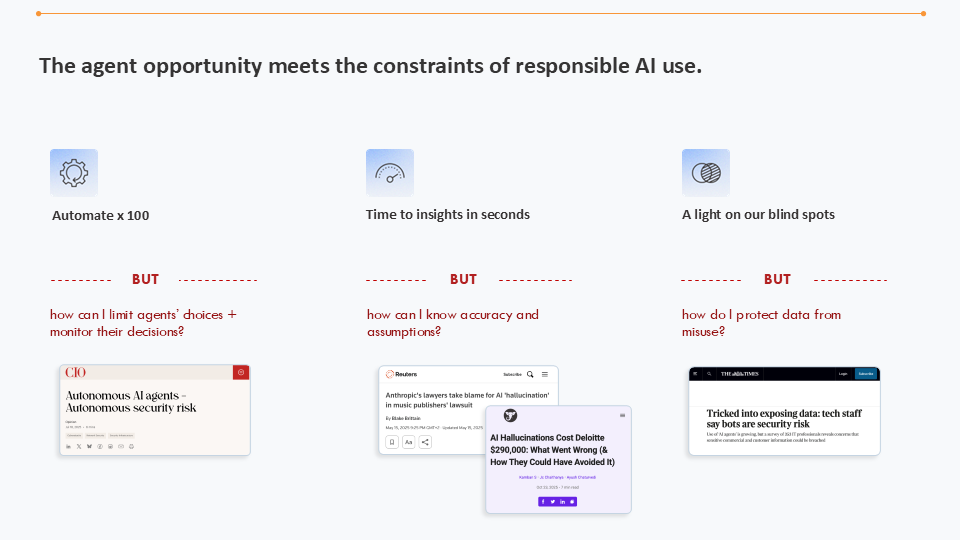
Wat gebeurt er wanneer agentkansen de beperkingen van verantwoord AI-gebruik ontmoeten
De gebruikelijke reflex is hier om goedkeuringsstappen toe te voegen: een reviewer die tekent en uitzonderingen escaleren. Maar de traditionele “human-in-the-loop” stort in op schaal.
Een agent die continu opereert, kan honderden of zelfs duizenden beslissingen per dag nemen. Als elke actie handmatige evaluatie vereist, zal het uiteindelijke “bewijswerk” zwaarder wegen dan de initiële tijdswinst. We hebben de uitvoering geautomatiseerd om vervolgens een nieuwe bottleneck in evaluatie te introduceren.
En er is nog een complicerende factor. We beoordelen of de acties die een agent onderneemt correct, veilig en beveiligd zijn. Maar hoe zit het met “nee” zeggen? Weet het systeem wanneer het niet moet handelen?
Dit is misschien wel een van de grootste problemen van agentische AI: een nuttige agent moet bijvoorbeeld beleidsconflicten kunnen detecteren en zeggen “dit kan ik niet doen” of “dit moet ik doorsturen naar een mens”. Zonder deze capaciteit worden agents outputmachines die resultaten genereren, of dat nu zou moeten of niet.
Op schaal wordt dit soort gedrag een aansprakelijkheid.
En daarmee zijn we terug bij de paradox.
Als mensen niet alles kunnen reviewen en agents niet betrouwbaar hun eigen grenzen kunnen inschatten, dan kan evaluatie niet een informele laag blijven die achteraf wordt toegevoegd. Het moet in het systeem zelf ontworpen zijn
De vraag is dus niet of evaluatie nodig is, maar hoe die wordt geïmplementeerd.
Bij KNIME hebben we dit in de praktijk gezien. In één geval bouwden we een agent die acties genereerde op basis van datainsights. Dat hielp enorm om ons werk te versnellen, maar we betrapten ons erop dat we bijna elke insight in twijfel trokken. We moeten agents niet blind vertrouwen, maar vertrouwen is wel nodig om te kunnen schalen.
Het kantelpunt kwam toen we feedback in de workflow integreerden. Door elke “fout” te labelen en te identificeren, leerde de agent van ons, de mensen in de loop, en verbeterde hij. Na verloop van tijd werd de agent beter en nam het vertrouwen toe.
Onze les hier: bouw vertrouwen in het systeem. Evaluatie en feedback moeten deel uitmaken van het systeem, niet een add-onproces.
Het doel is niet onbeperkte autonomie of permanente menselijke supervisie, maar “gereguleerde autonomie”, waarbij systemen zelfstandig handelen binnen duidelijk gedefinieerde grenzen.
Onze platforms moeten antwoorden hebben op situaties zoals wat er gebeurt als de agent het mis heeft, hoeveel fouten acceptabel zijn en wat de kosten van falen zijn versus het voordeel van automatisering.
Gereguleerde autonomie vereist dat organisaties vooraf definiëren:
|
Duidelijke vangrails en beperkingen |
Bijvoorbeeld de voorwaarden waaronder een agent zonder tussenkomst mag handelen |
|
Gedefinieerde fouttolerantieniveaus |
Bijvoorbeeld de betrouwbaarheidsdrempels die nodig zijn voor autonome uitvoering |
|
Geleidelijke uitrolstrategieën |
Bijvoorbeeld: een initiële uitrol met een hoog niveau van menselijke review in de vroege fase, waar de agents van kunnen leren en verbeteren |
Een agent kan autonoom opereren boven een gedefinieerd zekerheidsniveau. Onder die drempel moet hij de beslissing overlaten aan menselijke review. Naarmate vertrouwen en prestaties verbeteren en foutpercentages dalen, kunnen die drempels zich aanpassen, maar het escalatiemechanisme blijft bestaan.
Cruciaal is dat menselijk ingrijpen altijd mogelijk moet blijven. Autonomie zou de routinebetrokkenheid moeten verminderen, maar niet elimineren.
Deze aanpak herkadert de paradox: zeggenschap gaat niet verloren wanneer je delegeert, maar wordt uitgeoefend op basis van een vangrailkader.
Ik geloof dat vertrouwen in agentische systemen niet voortkomt uit betere modellen, maar uit betere kaders.
Bedrijven hebben een vangrailkader nodig dat onderdeel is van de systeemarchitectuur. Het geeft agents de ruimte, terwijl het ze verbindt aan deterministische logica.
Een robuust ondernemingskader zou het volgende moeten omvatten:
Agents zouden niet alleen op data moeten vertrouwen om hun volgende acties te bepalen. Ze moeten opereren binnen vooraf gedefinieerde regels en beperkingen, in lijn met de regelgevende, financiële en organisatorische policies van het bedrijf.
Deze regels en beperkingen moeten in workflows worden geïntegreerd. Zo worden policies afdwingbaar.
Bedrijven hebben traceerbaarheid nodig in hoe beslissingen worden opgebouwd en uitgevoerd.
Het is niet genoeg om alleen de uitkomst van de agent te zien; organisaties moeten het "denk"proces kunnen inspecteren – het redeneerpad, evenals toolgebruik en databronnen.
Dit maakt een audittrail mogelijk die uitlegt waarom een beslissing is genomen. Dit creëert verantwoordelijkheid, ondersteunt naleving van regelgeving en maakt analyse achteraf mogelijk.
Agents moeten niet improviseren op gebieden waar al deterministische logica bestaat.
In plaats van een agent elke keer te laten raden hoe een complexe belastingmarge te berekenen, geef je hem een vaste, geverifieerde tool (een "node" of subtaak) om precies die berekening uit te voeren.
Zo wordt de agent een orkestrator van betrouwbare tools in plaats van een generator van onzekere redeneringen in mogelijk risicovolle contexten.
Diepe datatoegang is niet altijd nodig.
Agents zouden data moeten benaderen op basis van “need-to-know”. Terwijl een supportagent gespreksgeschiedenis en een kennisbank nodig heeft, heeft die waarschijnlijk geen burgerservicenummer van een klant nodig om effectief te zijn.
Agentische systemen zouden niet in één stap van pilot naar autonomie moeten gaan.
Vroege fasen kunnen hogere niveaus van menselijke review en actief monitoren omvatten. Maar na verloop van tijd, wanneer prestaties stabiliseren en faalwijzen begrepen worden, kan autonomie worden uitgebreid.
Continu onderhoud is essentieel. Agents moeten continu worden onderhouden en geoptimaliseerd. Data kan verschuiven, verouderen en regelgeving kan veranderen. Als agents niet worden gemonitord en opnieuw gekalibreerd, nemen ze beslissingen op basis van onnauwkeurige of oude informatie.
Om gereguleerde autonomie op schaal te implementeren, moet de governancelayer van een organisatie boven individuele modellen en leveranciers liggen, om vendor lock-in te vermijden.
Governance moet bestaan als een architecturele laag, zodat je de onderliggende AI kunt wisselen terwijl de vangrails intact blijven.
Platforms die orkestratie, deterministische logica en transparante uitvoering combineren, zijn in deze context strategisch belangrijk. Ze stellen organisaties in staat te bepalen hoe agents interageren met enterprise-data en -processen.
Er bestaat een misvatting dat betere modellen automatisch tot betere beslissingen leiden. De schadelijkste incidenten zullen niet terug te voeren zijn op model fouten, maar op mensen die verantwoordelijkheid delegeren zonder verantwoordelijkheid te ontwerpen. De controle zit in het systeem, niet in het model.
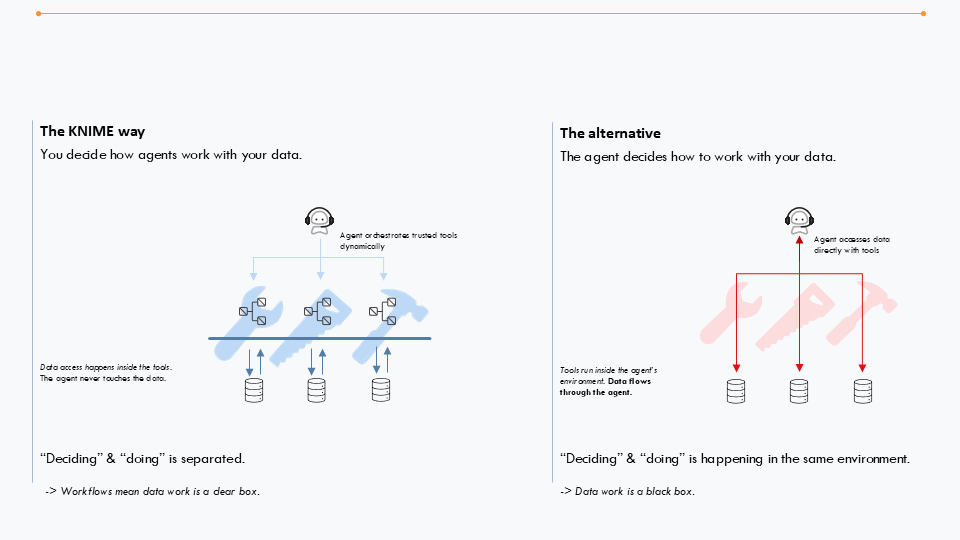
KNIME volgt best practices voor het bouwen van agents en zorgt ervoor dat de agent de data nooit aanraakt
De enterprise-AI-paradox zal niet verdwijnen: organisaties zullen meer autonomie willen om te profiteren van meer efficiëntie en schaal, maar regelgevende inspecties en risico zullen toenemen.
Het belangrijkste inzicht is dat zeggenschap door ontwerp moet worden geborgd.
De grootste mislukkingen van het agentische tijdperk zullen waarschijnlijk niet voortkomen uit de technologie zelf, maar uit slecht ontworpen governance. De organisaties die slagen, zijn degenen die autonomie bewust ontwerpen en toezicht structureel inbedden.
De kers op de taart is wanneer je AI-platform geïntegreerde governance-mogelijkheden biedt. Zo kunnen organisaties zowel automatisering als evaluatie opschalen. Je kunt meer leren over het ontwikkelen van een playbook voor AI-governance met dit DataCamp-webinar.
Topcursussen op DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
